Node.js 社区热议 AI 代码引入:1.9 万行 Claude Code 引发关于可审计性、DCO 合规性和长期影响的激烈辩论。
原文标题:1.9万行 Claude Code“AI垃圾”杀入 Node.js:全球顶流开源项目,快守不住了
原文作者:AI前线
冷月清谈:
反对者主要担心 AI 代码的可审计性、DCO 合规性,以及可能对项目长期发展带来的负面影响,他们认为 Node.js 作为关键基础设施,其核心代码应由开发者以高度审慎的方式手工维护,AI 代码可能削弱这种工程传统,甚至动摇 Node.js 的可信度。
支持者则认为,AI 只是辅助工具,最终责任仍在于开发者,并且已有人工审核,同时,Linux 内核社区、Red Hat 法律团队和 OpenJS 基金会等组织也对 AI 辅助开发的 DCO 兼容性表示认可。他们认为审查者也是共同作者,应共同承担责任。
社区用户也对此事展开激烈辩论,一部分人反对 AI 进入核心代码,认为其不可复现,且存在版权风险;另一部分人则认为,只要代码经过核心维护者审核,就值得信任。Node.js 创始人 Ryan Dahl 也表达了对 AI 辅助开发的积极态度,认为未来软件开发将更多地依赖 AI,而人类开发者的价值在于创造力和解决问题的能力。
怜星夜思:
2、AI 生成的代码,出了bug到底应该谁负责?是提交PR的工程师,还是review代码的同事,或者是开发AI的公司?
3、Node.js 引入 AI 生成代码,对于小型开源项目来说,是否具有借鉴意义?是弯道超车的好机会,还是饮鸩止渴?
原文内容

近日,开源世界最具影响力的项目之一 Node.js 正面临一个前所未有的抉择。一场关于是否允许人工智能生成代码进入其核心代码库的争议,正在技术社区引发激烈的辩论。
事情是这样的。
1.9 万行 Claude Code 代码
进入 Node.js 惹争议
2026 年 1 月,一个引人注目的 Pull Request(PR)被提交到 Node.js 核心代码库。这个 PR 包含了近 19000 行代码(具体为约 14000 行,跨越 66 个文件),旨在为 Node.js 引入一个全新的虚拟文件系统(VFS)功能。
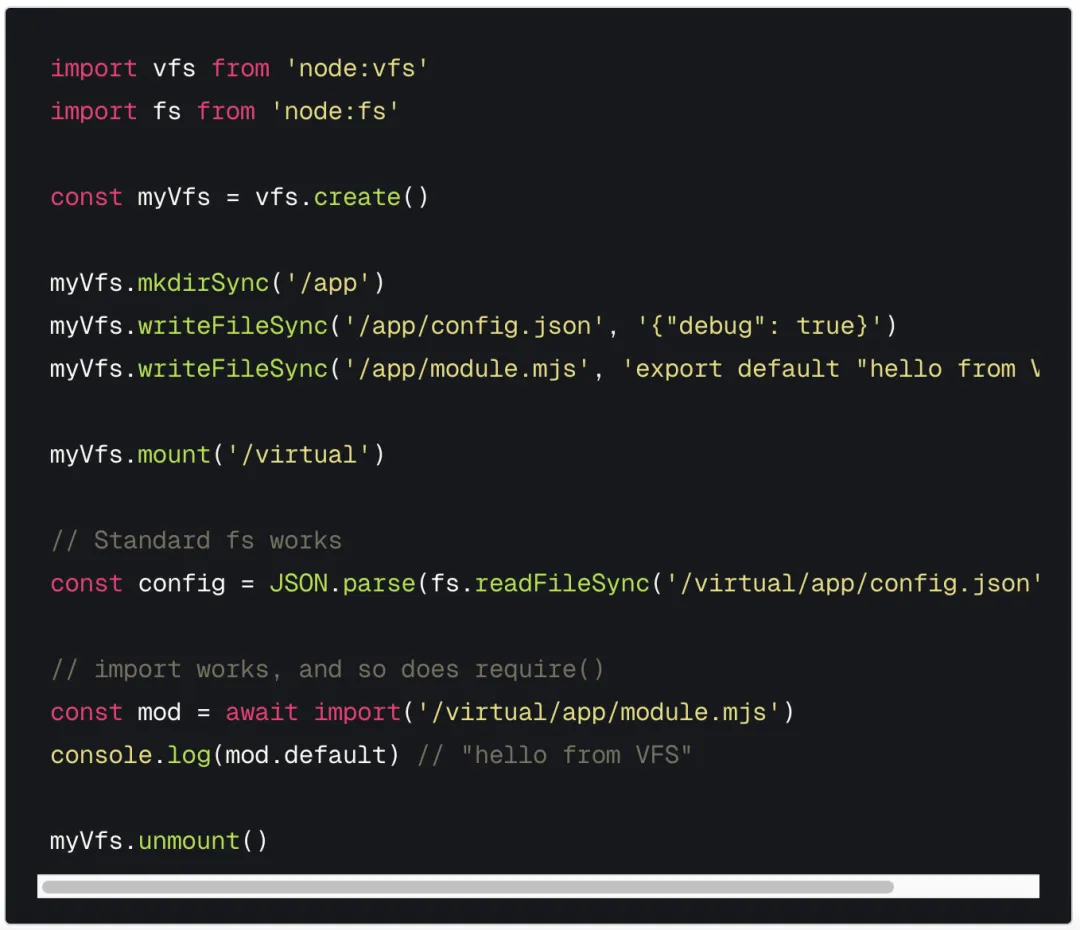
提交者是 Matteo Collina,Node.js 的技术指导委员会(TSC)成员、Platformatic 公司联合创始人兼 CTO,也是 Fastify 框架的维护者。他在 PR 描述中明确写道:“我使用了大量的 Claude Code token 来创建这个 PR。但所有代码均已由其本人完成审查。”
这个 PR 的出现本应被视为技术胜利——在短短一个圣诞假期内,完成了一个通常需要数月全职工作才能实现的大型功能。
Matteo Collina 公开表示 AI 处理了大量重复性工作,如实现所有 fs 方法、编写测试覆盖和生成文档,而他自己则专注于架构和 API 设计,并逐行检查代码。如果没有 AI,这作为假期业余项目是根本无法完成的。
他在名为《为什么 Node.js 需要虚拟文件系统》的博客中写道:“说实话,这么大的 PR 通常需要几个月的全职工作才能完成。这次之所以能成功,是因为我使用了 Claude Code。我让 AI 处理那些繁琐的部分,那些让 14000 行 PR 成为可能但却没人愿意手写的工作:实现每个fs方法变体(同步、回调、Promise),配置测试覆盖率,以及生成文档。我则专注于架构、API 设计以及逐行审查代码。如果没有 AI,这根本不可能成为一个假期副业项目,它根本不可能实现。”
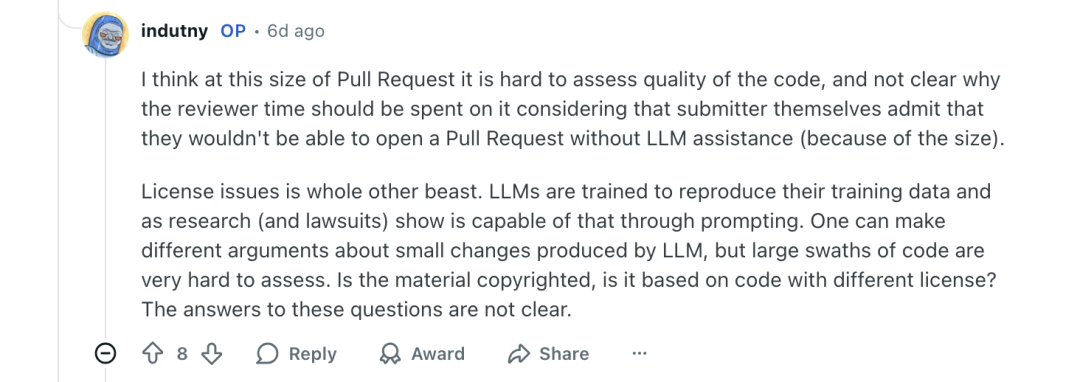
本来事情已经过去有一段时间了,但是几日前,长期 Node.js 核心贡献者 Fedor Indutny 对 Matteo Collina 借助 Claude Code 工具生成代码提交 PR 的行为产生了质疑。
Fedor Indutny 的担忧不在于代码质量,而在于 AI 辅助的代码是否符合 DCO 1.1 条款(每位 Node.js 贡献者在提交 PR 时必须签署的法律证明)。他甚至发起了一份请愿书,要求 Node.js 技术指导委员会(TSC)投票 禁止在核心项目中使用 AI 辅助开发。
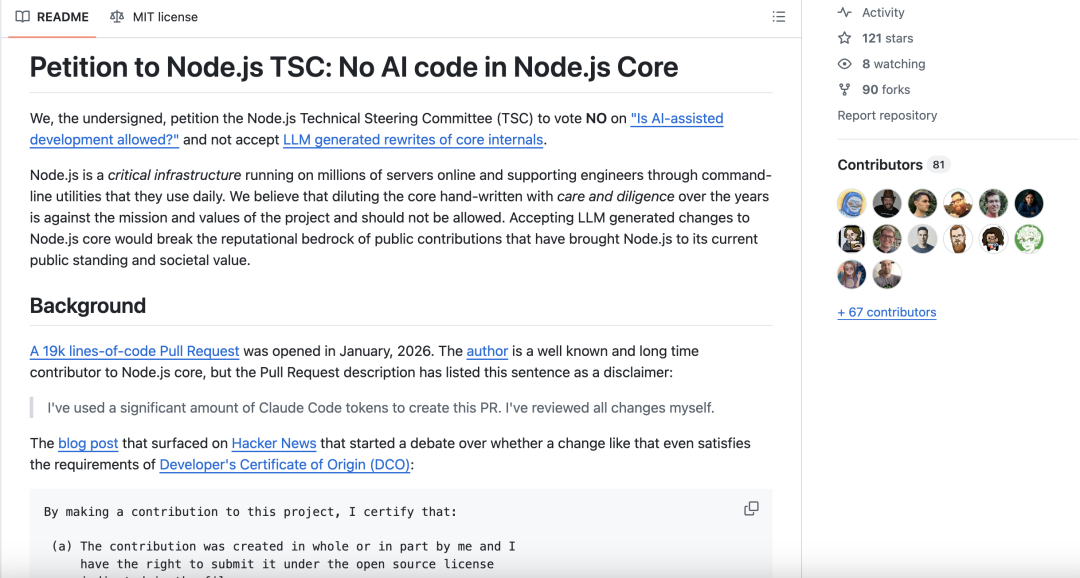
请愿书的核心论点包括:
-
基础设施的重要性:Node.js 是运行在数百万台服务器上的关键基础设施,通过工程师日常使用的命令行工具为他们提供支持。认为对多年来精心编写的核心代码进行稀释,违背了项目的使命和价值观。
-
DCO 合规性争议:尽管 OpenJS 基金会的法律意见认为 LLM 辅助的更改不违反 DCO,但请愿方认为这只是问题的冰山一角。
-
伦理考量:一些大型大模型公司在训练中使用了来源不正当的材料,包括受版权保护的作品和未经授权的开源代码。
-
教育影响:有证据表明,使用大模型会阻碍学生的学习过程。降低代码质量标准可能导致对 Node.js 核心的理解下降,危及项目的长期发展。代码审查流程不仅是为了发现漏洞和安全问题,更是为了帮助提交者学习成长。但 LLM 本身不具备学习能力,审查时间被浪费,贡献者的技能却没有得到提升。
-
特权问题:使用大模型需要付费订阅或大量硬件投资才能在本地运行。提交的生成代码应该能够被审阅者复现,而无需通过付费订阅的 LLM 工具。
总之,请愿者给出的理由中,最重要的部分指向 Node.js 的“基础设施属性”和代码的可审计性。
作为运行在全球数百万服务器上的关键运行时环境,Node.js 的核心代码长期以来依赖开发者以高度审慎的方式手工维护。在他们看来,这种“可追溯、可理解”的代码生产方式,本身就是项目可信度的重要组成部分。一旦引入 AI 生成代码,尤其是大规模改动,可能会削弱这种工程传统,甚至动摇 Node.js 在开发者生态中的声誉基础。
冲突的另一核心,在于“可审计性”。在传统开发流程中,代码不仅是执行逻辑的载体,更是设计决策的体现。评审者可以通过阅读代码,理解开发者在性能、兼容性与架构上的权衡。但 AI 生成代码往往缺乏明确的设计上下文,使评审过程从“理解设计”退化为“检查实现”。当这一问题叠加到 1.9 万行的变更规模时,代码审查的复杂度被指数级放大。
代码提交者回应争议:
如果有 bug,也是我的责任
请愿书在社区中引发热议,但却并非是一边倒的支持声。以 Matteo Collina 为代表的“AI 赋能派”提出了有力的反驳。
Collina 在博客文章《The DCO Debate: Who Is Responsible for AI-Generated Code?》中详细阐述了他的观点。他将 AI 比作“奶奶用的压面机”——工具帮助了制作,但最终的成品仍然是奶奶的责任。
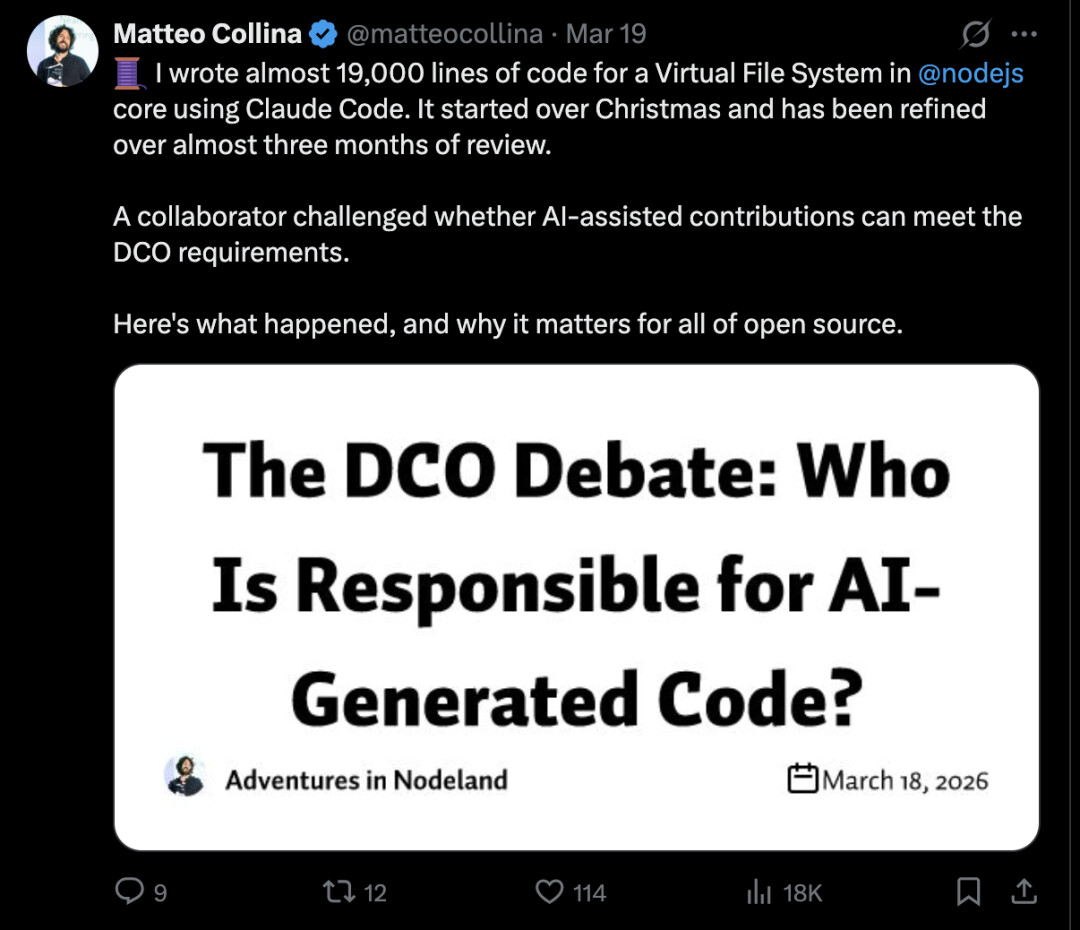
“我选择了架构。我根据所有审查者的反馈塑造了 API。我做出了设计决策,捕捉并修复了 AI 引入的问题,我理解代码每一部分的作用和原因。我签署了 DCO。我的名字在上面。如果有 bug,是我的责任。如果有许可问题,是我认证了合规性。”
Collina 还提出了一个重要观点:审查者同样应当被视为共同作者。“审查 PR、建议变更、捕捉边缘情况、帮助塑造最终实现的维护者——他们难道不是这项工作的共同作者吗?在 Node.js 历史上,每次 PR 都是如此。”
此外,Collina 还希望社区能够就“人工审核”在人工智能辅助贡献中的真正含义达成共识。仅仅说“我审核过了”是不够的。我们需要能够回答诸如此类的问题:你理解这段代码的功能吗?你能解释一下设计选择吗?你能在不再次询问人工智能的情况下回应反馈吗?你能在一年后维护这段代码吗?这些问题我们一直以来都问过贡献者。工具可能会改变,但对人的期望不会改变。
Collina 还在文章中阐明,更广泛的开源生态系统已经就 AI 辅助贡献问题形成了初步共识。
Linux 内核社区:作为 DCO 的创造者,Linux 内核社区对 AI 辅助贡献有明确的政策文件。他们的 coding-assistants.rst 要求严格的人机循环过程。AI 代理不被允许添加 Signed-off-by 标签。只有人类才能合法认证 DCO。提交代码的人必须审查所有 AI 生成的代码,检查许可合规性,并添加自己的签名。AI 辅助必须通过 Assisted-by 标签披露。
Red Hat 的法律团队:CTO Chris Wright 和法务顾问 Richard Fontana 发布了详细分析,直接回答了 DCO 问题。他们解释说,DCO 从未被解释为要求贡献的每一行都必须是贡献者的个人创造性表达。许多贡献包含例行的、不受版权保护的材料,开发者仍然签署。DCO 的真正要点是责任。在披露和人工监督下,AI 辅助贡献完全可以与 DCO 的精神兼容。
OpenJS 基金会:Node.js 自己的法律机构在 PR 上直接表态。执行董事 Robin Ginn 确认,基金会已咨询法律顾问,对 AI 辅助贡献的 DCO 兼容性表示满意,并承诺正式记录这一立场。
这三个独立组织——DCO 的创造者、世界最大的开源法律团队之一、Node.js 自己的基金会——都达成了相同的答案:AI 并不破坏 DCO。重要的是问责制。
与此同时,Hacker News、Reddit 等社区用户也就此事吵翻了!
在 Reddit 上,一部分开发者将矛头直接指向 AI,反对其进入核心代码。
该用户表示:“坦白说,虽然我支持大规模的代码重构和自动化生成,但直接利用大模型来管理这类变更并不是最优解。我更倾向于看到作者通过 AST(抽象语法树)转换脚本或其他可编程脚本来实现重构。这种方式逻辑清晰,能让我更直观地理解代码改动的本质及原因。相比之下,大模型生成的变更具有不可复现性,且依赖付费订阅工具,增加了协作门槛。此外,如果重构过于复杂,我建议将其拆解为多个小的增量 PR,通过循序渐进的方式来降低整体复杂度。”
还有用户吐槽,既然 PR 提交者自己都说代码是 AI 写的,为什么要让审查员去人肉排雷?他写道:
“说白了,这个 PR 太大了,大到没人能保证质量。提交者自己都说‘没 AI 我可写不出这么多’,这不就说明连作者自己都未必能完全掌控这 2 万行代码吗?既然你写起来是‘一键生成’,凭什么要求审查员枯坐几天几夜去人肉排雷?”
该用户继续还提到版权问题更是个大坑。“大家都知道 AI 会‘致敬’训练集里的代码,万一它随手甩给你一段别人的闭源专利代码,你根本分辨不出来。小修小补也就罢了,这种成批量、成规模的‘搬运’,法律风险实在太高——谁敢保证这代码背景干不干净?万一以后被告了,这责谁来负?”
还有用户算了一笔账,该用户表示:
“我算了一下,那是 1.9 万行代码。按每行审 2 分钟算,那就是 (19000 ✖️2) ➗ 60 ➗ 7 约等于 90 个工作日(按每天 7 小时计)。
你确定这些代码真的都被逐行阅读了吗?我的意思是,既然作者连写都懒得写,那他们真能耐下性子把这些代码全部读一遍吗?
如果这只是某个私人网站或者某家小公司的业务代码,冒这个险也就罢了;但对于一个被无数人赖以生存、作为基础设施的开源项目来说,看到如此海量的、由 AI 生成的‘看起来没问题’的代码,简直让人毛骨悚然。”
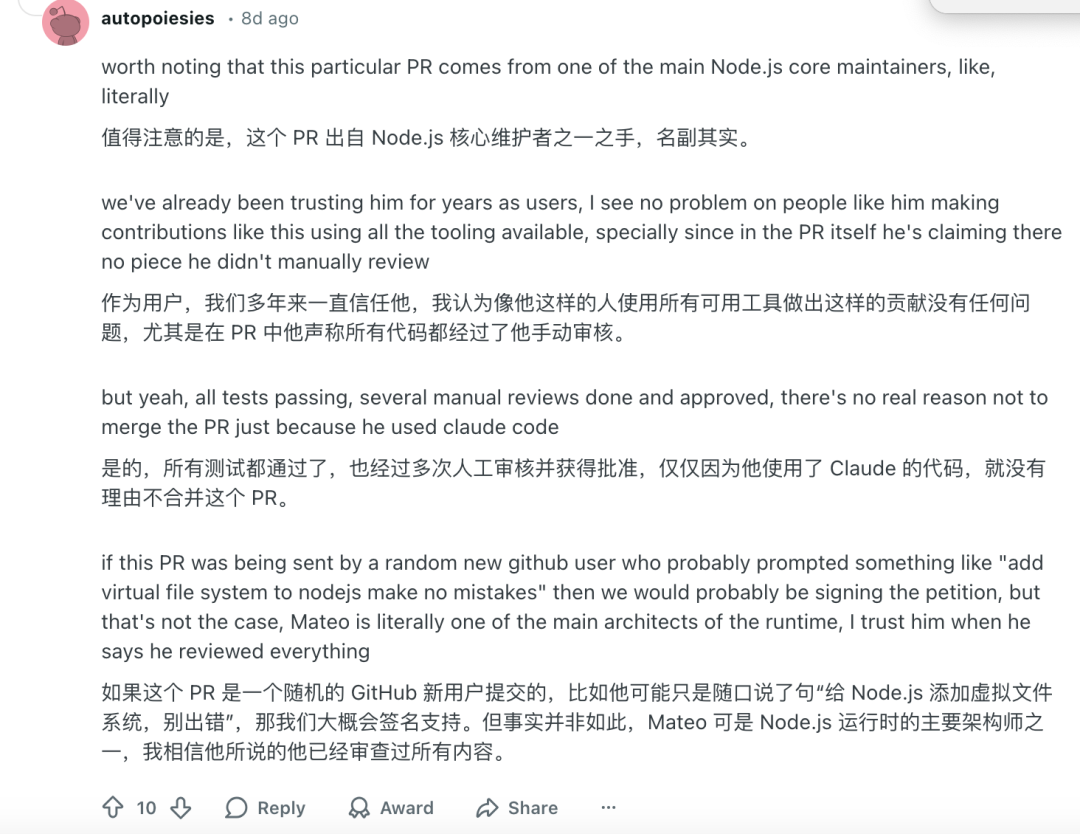
但也有用户认为,这些代码出自 Node.js 核心维护者之手,他自己也手动审核了代码,所以这些提交上去的代码是值得信任的,如果只是因为使用了 AI 就遭到质疑,是不公平的。
也有用户辩证地去看待这件事,他表示:“我坚决反对‘一刀切’地禁止大模型,但我也同样反对那些仅仅因为 AI 提速了,就毫无节制地提交巨量代码的行为。不能因为现在能比以前快 100 倍,就理所当然地往社区塞入 100 倍规模的 PR。”

Node.js 创始人:未来软件
不需要人类手搓代码了
事实上,Collina 用 Claude Code 提交 PR 的做法与 Node.js 创始人 Ryan Dahl 两个月前的观点很吻合。
今年 1 月份,Ryan Dahl 在 x 上发文称,“人类编写代码的时代已经结束了,机器现在能够在几秒钟内完成过去需要几个月才能完成的工作。”
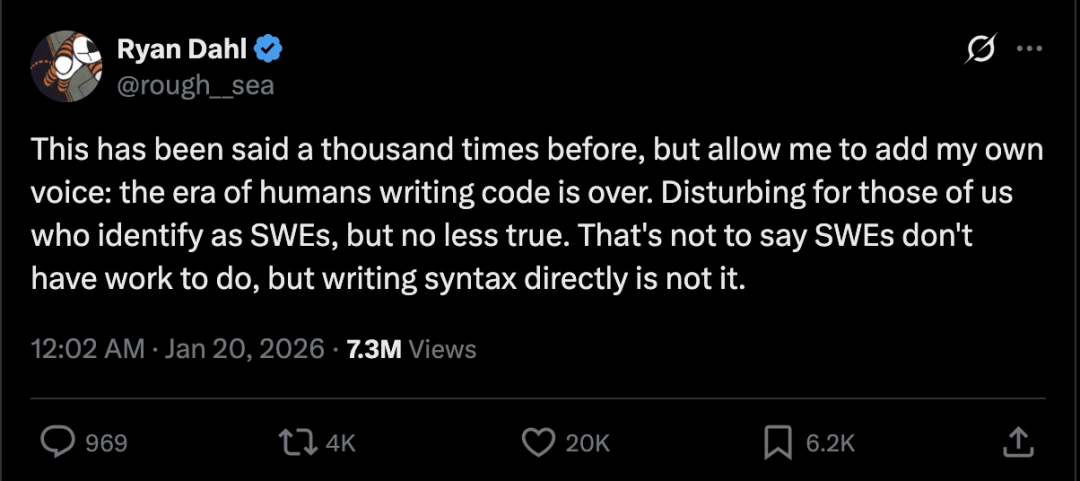
与人工智能的出现会使开发人员变得多余的观点相反,Dahl 强调,人类开发人员仍然必不可少,而且他们实际上拥有比以往更有价值的技能。开发人员不再需要执行诸如输入命令之类的底层编程任务,因为这些工作现在由 AI 算法完成。开发人员的价值更多地体现在他们所拥有的创造力和解决问题的能力上。
“人类的工作不再是编写每一行代码,而是协调人工智能工具,以前所未有的速度和质量构建系统。”
此外,初级职位将发生变化,那些只专注于编写 CRUD 应用或基本功能的入门级职位已经消失了。但新的职位正在涌现:人工智能提示工程师、人工智能质量保证专家和人工智能集成架构师。
在这样的背景下,了解领域专业知识更为重要。他曾提到,了解医疗保健、金融、物流或任何特定行业远比掌握 React 的语法重要得多。人工智能可以编写代码,但它无法取代深厚的领域知识。
参考链接:
https://yakhil25.medium.com/the-era-of-human-written-code-is-over-ryan-dahls-wake-up-call-to-software-engineers-dc6a4907b8ac
https://adventures.nodeland.dev/archive/who-is-responsible-for-ai-generated-code/
https://blog.platformatic.dev/why-nodejs-needs-a-virtual-file-system
https://www.reddit.com/r/node/comments/1qhulv1/creator_of_nodejs_says_humans_writing_code_is_over/
http://timesofindia.indiatimes.com/articleshow/127107198.cms?utm_source=contentofinterest&utm_medium=text&utm_campaign=cppst