HyperOffload通过图驱动分层存储管理,突破超节点大模型“显存墙”难题,已集成于华为MindSpore。
原文标题:以「图」破局,HyperOffload定义超节点存储管理新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到“选择性参数卸载”和“自适应激活值交换”技术,这两种技术分别解决了什么问题?它们之间有什么联系或者区别吗?
3、HyperOffload目前已集成于华为MindSpore 2.8版本,那么对于普通的开发者而言,如果想体验这项技术,需要做哪些准备工作?有没有一些简单的上手教程或者示例代码可以参考?
原文内容

随着生成式 AI 迈入万亿参数时代,大语言模型(LLM)的推理与部署面临着前所未有的“显存墙”挑战。如何在超节点(SuperNode)复杂的异构存储架构下,实现海量张量的高效管理和调度,已成为大模型落地的胜负手。
近日,上海交通大学可扩展计算研究所蒋力、刘方鑫老师团队联合华为MindSpore团队,正式发布技术报告:《HyperOffload: Graph-Driven Hierarchical Memory Management for Large Language Models on SuperNode Architectures》 (arXiv: 2602.00748)。

-
技术报告 (arXiv):
https://arxiv.org/abs/2602.00748
-
开源社区 (AtomGit):
https://atomgit.com/mindspore/hyper-parallel
该方案通过创新的“图驱动”显示存储层级管理,显著提升了超节点内异构资源的协同效率。目前,HyperOffload 核心技术已作为Hyper-Parallel库的关键特性,正式集成于华为官方 AI 框架 MindSpore 2.8 版本。Hyper-Paralle它成了多样化的并行策略与异构存储管理方案,助力开发者在超节点架构下实现万亿参数模型的“一键式”加速部署。
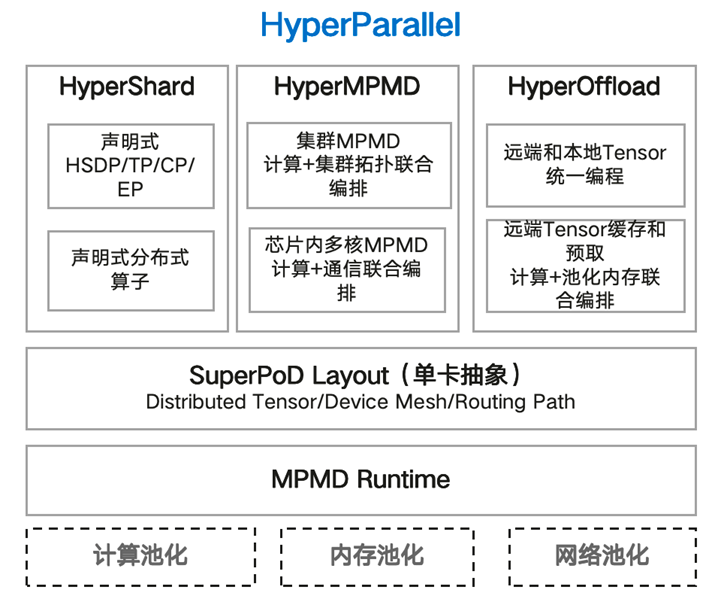
赋能超节点:从“存不下”到“存得优”
传统的内存优化方案往往聚焦于单卡或简单的多卡环境,而 HyperOffload 专为拥有 HBM、DDR 及 Flash 等多级存储的超节点(SuperNode)深度定制。其核心在于通过 Hierarchical Memory Manager (HMM) 模块,将物理隔离的存储介质转化为逻辑上的“资源池化”视图。
-
全要素存储协同与资源池化:HyperOffload 突破了以往只针对权重(Weights)卸载的局限,实现了对推理全流程中 KV Cache、中间激活值(Activations)及优化器状态的深度分层管理。论文提出的统一逻辑视图,能根据硬件拓扑自动感应 HBM 和 DDR 的带宽差异,将海量张量跨介质无缝缝合,实现了“逻辑显存”对物理显存瓶颈的降维打击。
-
极致容量拓容: 结合选择性参数卸载(Selective Offload)与自适应激活值交换(Adaptive Swapping)技术,该方案能让超大规模模型在有限显存的硬件集群上平滑运行,确保训推业务“不断档”。
选择性参数卸载:引入了多维代价模型(Cost Model),系统会根据张量的访问频率、重计算代价及通信带宽损耗进行智能评分。通过识别非关键路径上的“冷张量”,确保高频调用的核心算子始终驻留高速 HBM,而海量背景数据则有序分布在 DDR 中。
自适应激活值交换:针对 LLM 推理中动态膨胀的 KV Cache,系统通过动态水位线监控机制自动触发交换协议。即便面对超长上下文的极端显存压力,也能通过细粒度的张量换入换出确保业务“不断档”,极大提升了单节点能承载的模型规模。
图驱动规划: “被动调度”到“全局规划”
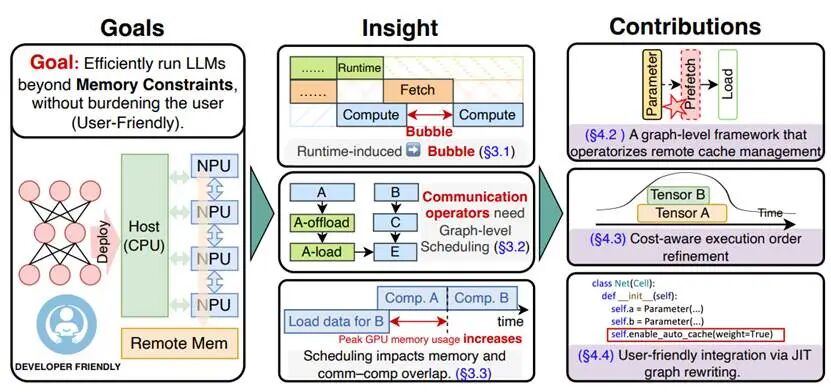
不同于传统的运行时被动触发,HyperOffload 引入了创新的编译驱动图化管理策略。它利用 MindSpore 的静态图编译技术,将资源管理从“滞后的响应”进化为“确定的预演”,具体优化如下:
1. 静态图语义增强:构建“上帝视角”
在编译阶段,HyperOffload 引擎会对 MindIR 静态图进行深度语义扫描,开展全局张量生命周期分析。系统会在计算流水线中精准定位内存峰值点,并提前在图中显式植入 SwapIn 与 SwapOut 原语。这意味着在推理启动前,整场“数据物资调度”的路线图已完全确定,消除了运行时频繁申请/释放内存带来的碎片化和系统开销。
2. 算力与带宽的深度重叠:实现“无感通信”
利用昇腾(Ascend)硬件的异步并行能力,HyperOffload实现了近乎完美的无感通信掩盖:
· 全局预判:系统根据计算图的进度,精准预判下一阶段的张量需求,提前下达搬运指令。
· 提前预取:依托“粮草先行”逻辑,当 NPU 的计算核心(Cube/Vector)正在处理当前层任务时,下一层的权重或 KV Cache 已异步从 DDR 换入显存。
· 通信遮掩:这种深度重叠将昂贵的数据迁移开销完全掩盖在计算任务的执行周期内。实验表明,该策略极大提升了超节点的整体算力利用率,使系统在不增加硬件成本的前提下,实现了吞吐量的阶跃式提升。
产学研深度合作:加速 AI 工业化进程
HyperOffload 的发布,标志着上海交通大学科研团队与华为 MindSpore 团队在 AI 基础设施领域的合作迈向新阶段。目前,该方案已在多个大规模商用项目中落地,为万亿参数模型的轻量化部署提供了成熟的工业级参考。
未来,双方将继续深耕超节点架构下的性能优化,构建更具弹性的端到端推理框架,为生成式 AI 的规模化应用夯实底座。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com