新型GNN架构DYNAMI-CAL GraphNet通过嵌入动量守恒定律,显著提升复杂多体动力系统建模效率,为机器人、航空航天等领域带来福音。
原文标题:这款新 GNN,让物理系统建模守得住守恒定律
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到 Walrus 模型在预训练阶段覆盖了多种物理场景,这种跨领域预训练对于提升模型的泛化能力有什么帮助?是否存在局限性?
3、DYNAMI-CAL GraphNet 和 Walrus 模型都强调了物理信息的重要性,那么,在未来的 AI 研究中,我们应该如何更好地融合物理知识和数据驱动方法?
原文内容

本文约5000字,建议阅读10分钟
本文介绍了融合动量守恒的 GNN 新架构,高效建模复杂多体动力系统。

来自瑞士洛桑联邦理工学院研究人员提出了一种新的模型架构 DYNAMI-CAL GraphNet,通过将线动量和角动量守恒定律直接嵌入模型结构,显式保证这两种守恒。实验结果表明:DYNAMI-CAL GRAPHNET 在需要对复杂多体动力系统进行准确、可解释且实时建模的领域中具有显著优势,例如机器人技术、航空航天工程以及材料科学。
近年来,人工智能在图像识别、自然语言处理等领域取得了巨大突破,但在复杂物理系统建模方面仍面临诸多挑战。许多现实世界问题——例如颗粒材料运动、分子动力学、人类运动以及机械系统模拟——都属于多体动力学系统。这些系统通常具有高度复杂的交互关系,并且需要严格遵守基本物理规律,例如动量守恒和能量守恒。
传统数值模拟方法能够精确描述这些系统,但往往计算成本高昂,特别是在需要长时间模拟或大规模粒子系统时,计算资源消耗巨大;与此同时,机器学习模型虽然可以从数据中学习复杂关系,但往往缺乏对物理规律的约束,导致在长期预测中出现误差累积甚至系统发散。
在此背景下,物理信息机器学习逐渐成为研究热点。其中,基于 Graph Neural Network(GNN)的动力学建模方法近年来受到广泛关注。GNN 能够天然地表示粒子或刚体之间的交互关系:节点代表物体,边代表相互作用。因此,它非常适合模拟多体系统。然而,诸如 GNN 之类的数据驱动方法通常缺乏物理一致性、可解释性和泛化能力。
为了解决这一问题,来自瑞士洛桑联邦理工学院研究人员提出了一种物理信息驱动的 GNN 新型架构 DYNAMI-CAL GraphNet,它将 GNN 的学习能力与基于物理的归纳偏置相结合,通过将线动量和角动量守恒定律直接嵌入模型结构,显式保证这两种守恒。
实验结果表明,DYNAMI-CAL GRAPHNET 在需要对复杂多体动力系统进行准确、可解释且实时建模的领域中具有显著优势,例如机器人技术、航空航天工程以及材料科学。通过提供符合基本守恒定律的物理一致且可扩展的预测能力,该方法能够推断系统中的力和力矩,同时高效处理异质交互和外部作用力。
相关研究成果以「A physics-informed graph neural network conserving linear and angular momentum for dynamical systems」为题,已刊登 Nature Communications。
研究亮点:
* DYNAMI-CAL GRAPHNET 在等变 GNN 架构中,通过在内部成对相互作用层面强制执行牛顿第三定律,将线性动量和角动量守恒直接融入网络结构
* 该方法即使在复杂的非中心相互作用、耗散作用等情况下也能给出物理一致的预测,并且适用于多种系统
* 该架构在控制系统设计、机械过程优化以及自然与工程系统中动态行为分析等方面具有重要价值
论文地址:

https://www.nature.com/articles/s41467-025-67802-5
四类截然不同的动力学系统数据集
为了验证模型的通用性,研究团队在 4 类截然不同的动力学系统数据集上进行了实验。这些数据集涵盖了从物理模拟到真实世界数据的多种场景。其中:
颗粒 6-DoF 碰撞数据集
研究团队构建了六自由度颗粒碰撞系统。在该系统中,每个颗粒不仅可以进行平移运动,还可以发生旋转运动,因此具有六个自由度(6-DoF)。
训练数据集由 5 条轨迹组成,每条轨迹包含 60 个相同的球体,这些球体被限制在一个长方体封闭空间中运动。初始线速度随机赋值,其速度大小在 1–2 m/s 的范围内进行均匀采样,每条轨迹包含 1500 个时间步,数据采样间隔为 10⁻⁴ 秒,而底层物理仿真的时间步长为 10⁻⁶ 秒;在每一个时间步中,都会记录每个球体的以下状态信息:位置(position)、线速度(linear velocity)、角速度(angular velocity)。
验证集包含 1 条未参与训练的轨迹,系统同样由 60 个球体组成,共 200 个时间步,其初始速度大小仍在训练范围内,但速度方向与训练数据不同,用于检验模型的泛化能力。
插值测试集的设置与验证集相同,但轨迹长度为 500 个时间步,用于评估模型在训练分布范围内的长期预测能力。
受约束N体系统
针对经典的受约束 N 体动力学问题,为了评估模型在混合相互作用类型和结构约束系统中的适用性,研究人员使用文献提出的 Constrained N-Body 数据集。该数据集在 Thomas Kipf 等人提出的三维带电粒子模拟基础上进行了扩展,通过引入刚性杆(sticks)和铰链(hinges)形式的完整约束来构建系统。
人体运动捕捉数据
第三个数据集来自真实世界的人体运动数据 CMU Motion Capture Database。该数据集记录了人体骨骼关节在运动过程中的三维位置变化,例如:行走、跑步、跳跃在实验中,研究人员选取了其中一位受试者的「行走」数据,并将人体骨骼关节建模为图结构,其中节点表示关节,边表示骨骼连接。这一实验主要用于验证模型在真实世界复杂运动系统中的表现。
蛋白质分子动力学
最后一个数据集来自蛋白质分子动力学模拟。研究人员使用 apo 腺苷酸激酶(AdK)平衡轨迹数据集,通过 MDAnalysis 工具包获取,该数据集记录了蛋白质在显式水分子与离子环境中的原子级运动。
DYNAMI-CAL GraphNet:一种物理信息驱动的 GNN 新型架构
DYNAMI-CAL GraphNet 的核心思想是将物理守恒定律直接嵌入神经网络结构中,其整体架构如下图所示,可以分为三个关键阶段:
① 图表示;
② 具有线性动量与角动量守恒的标量化–向量化方案;
③ 时空消息传递。
DYNAMI-CAL GRAPHNET 模型整体架构与数据流
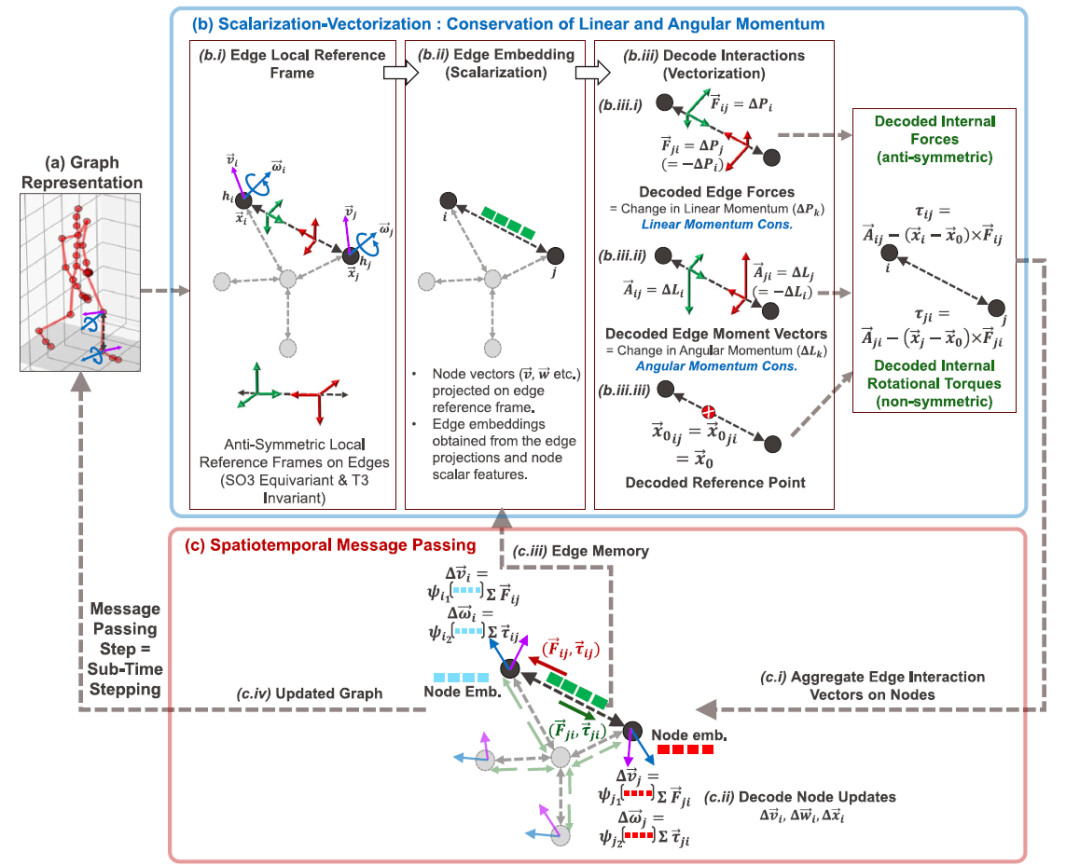
第一阶段:图表示(Graph Representation)
首先,研究人员将多体系统表示为一个图:节点代表物体或粒子,边代表物体之间的相互作用。每个节点包含多种特征,例如:位置、速度、角速度、物体属性(质量、电荷等);而边则表示两个物体之间的相对位置和交互关系。
第二阶段:标量化–向量化(Scalarization-Vectorization)
* 标量化(Scalarization)
在标量化阶段,模型会将节点和边的向量信息转换为高维标量嵌入。一个关键创新是:每条边都会分配一个局部正交参考坐标系,其性质包括:对 3D 旋转 SO(3) 等变,对平移 T(3) 不变,在节点交换时反对称——在实际应用中,这意味着当边方向反转时,三个基向量都会改变符号,从而保证所有后续投影和相互作用计算都满足反对称性。
在标量化步骤中,节点向量特征(例如速度和角速度)被投影到这些边局部坐标系中,从而得到标量分量。这些标量随后与其他节点标量特征结合,形成对节点顺序不敏感的边嵌入。这种方法在保持系统对称性的同时,同时编码了局部相互作用的方向信息和标量信息。
* 向量化(Vectorization)
在向量化阶段,模型会从边的嵌入向量中解码出内部作用力以及旋转力矩,这些力随后被聚合到节点上,用于更新粒子的线速度、角速度和位置。由于模型设计中强制保证力和力矩满足反对称关系,因此系统天然满足线动量守恒和角动量守恒。
第三阶段:时空消息传递(Spatiotemporal Message Passing)
在每条边上计算出物理一致的内部力和力矩之后,模型会执行 DYNAMI-CAL GRAPHNET 的时空消息传递机制。
首先将解码得到的边级内部力和旋转力矩在连接节点上进行聚合,从而得到每个节点所受到的合力和合力矩;随后,这些向量会乘以由节点标量嵌入得到的系数,从而更新节点的线速度和角速度,接着使用隐式欧拉积分计算更新后的位置,这一过程构成了 DYNAMI-CAL GRAPHNET 的一个消息传递层。
在下一轮边编码中,这种逐步演化的表示会作为每条边的潜在记忆(latent memory)保留下来,因此该模型能够实现真正的时空推理。
这种设计使 DYNAMI-CAL GRAPHNET 能够在多个时间尺度上捕捉系统的动态行为,同时在每一步计算中保持基于物理规律的归纳偏置。
实验结论:稳定性与泛化能力显著提升
研究人员在 4 个基准任务上评估 DYNAMI-CAL GRAPHNET 的性能,这些任务涵盖了模拟物理系统和真实世界物理系统。在多个数据集上的实验表明,DYNAMI-CAL GraphNet 在多个指标上优于现有方法。
颗粒 6-DoF 碰撞基准(Granular 6-DoF collision benchmark)
在一个长方体容器中对 60 个球体的 6 自由度(6-DoF)运动进行滚动预测实验,下图展示了 DYNAMI-CAL GRAPHNET 与 GNS 的比较:
受限颗粒碰撞的长时序滚动预测
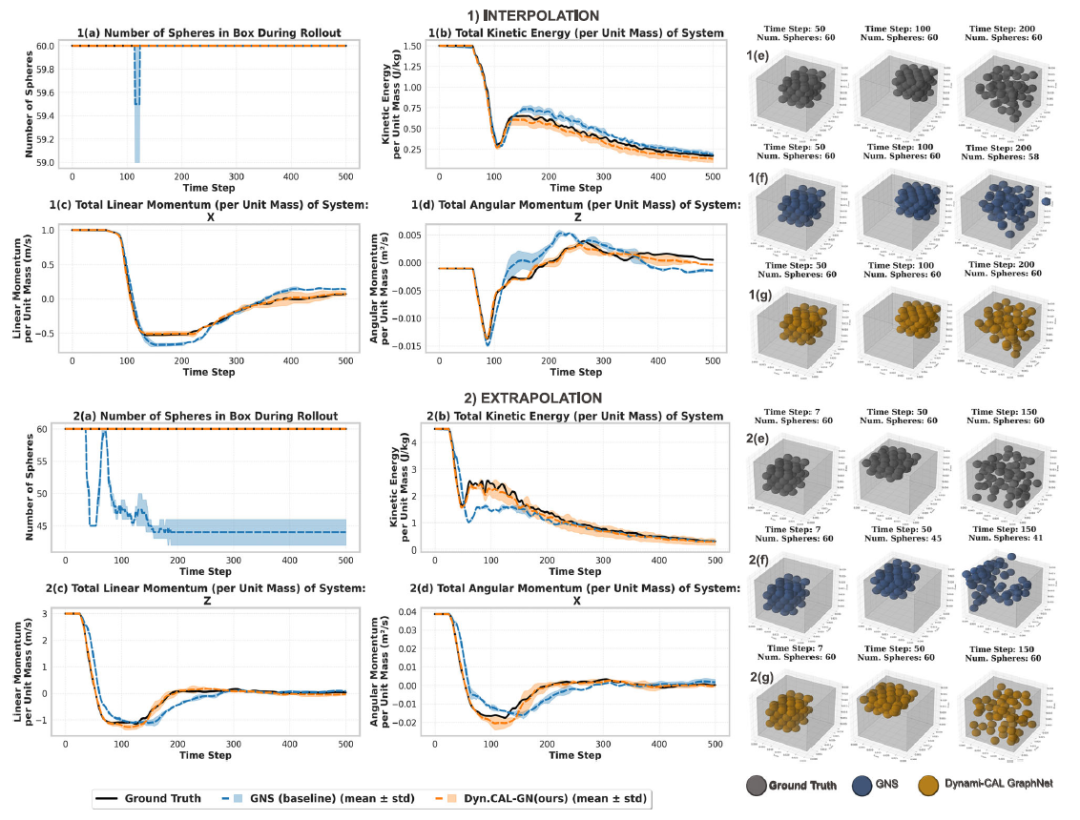
DYNAMI-CAL GRAPHNET成功保留所有粒子,准确跟踪动能衰减,在 500 步预测中保持动量演化一致,在不同随机种子下方差很小。与之相比,GNS 在外推场景中较早发生发散,且出现粒子逃逸。原因是在高动量条件下,碰撞速度增加,需要准确计算冲量接触力才能维持系统约束,而 GNS 无法很好泛化,即使是未逃逸的粒子,其预测也逐渐偏离真实物理行为。
这些结果表明:DYNAMI-CAL GRAPHNET 在建模耗散型、接触密集的 6-DoF 动力系统方面具有更强的鲁棒性与泛化能力。
受约束的 N 体动力学(Constrained N-body dynamics)
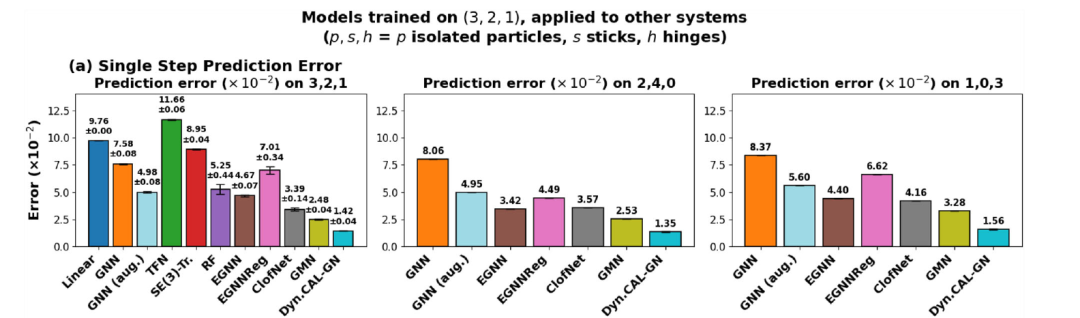
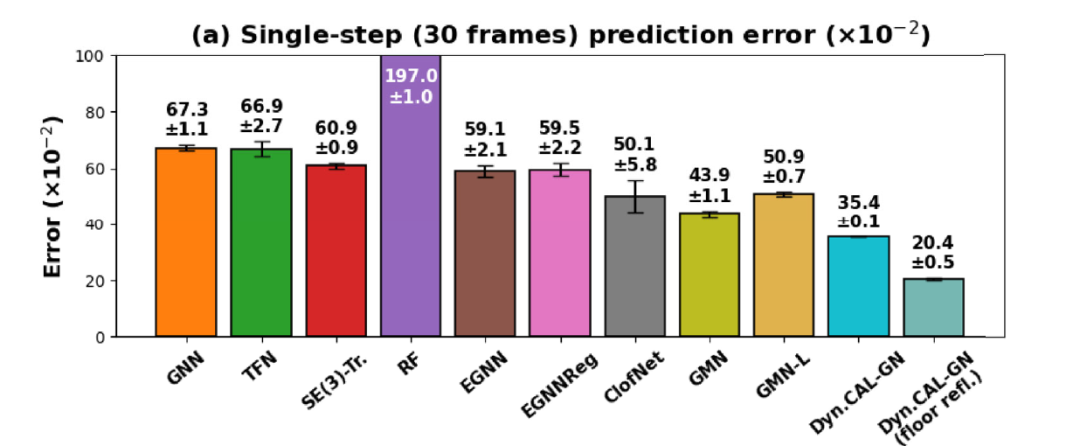
总体而言:DYNAMI-CAL GRAPHNET 在单步预测和多步预测任务中均优于所有基线模型。
在下图 a 中,DYNAMI-CAL GRAPHNET 在各种梗配置下都取得了最低单步预测误差,性能均优于 GMN、EGNN 和 ClofNet。随后,研究人员引入随机旋转和平移增强显著提高了非等变 GNN的性能,并缩小了与等变模型之间的差距。然而,即使数据量增加,且模型显式接触几何对称性,GNN (aug.) 仍然在所有测试配置中落后于最简单的等变模型 EGNN 和 DYNAMI-CAL GRAPHNET。
这表明:架构中的归纳偏置(inductive bias)对于泛化受约束的物理动力学仍然至关重要。
约束 N 体基准测试中的性能表现(单步预测误差)
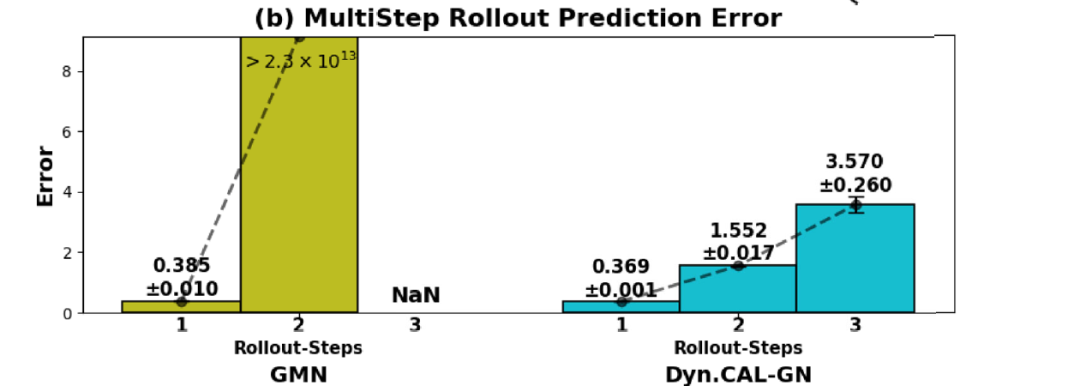
对于多步滚动预测(multi-step rollout prediction),下图 b 将 DYNAMI-CAL GRAPHNET 与 GMN 进行了比较。结果表明,在最长 4 步的多步滚动预测(其中 1 步 = 10 帧 = 1000 次仿真步)中,DYNAMI-CAL GRAPHNET 能够保持稳定的长期预测精度;而 GMN 的预测误差则会随着时间逐渐累积并显著增大。
约束 N 体基准测试中的性能表现(多步滚动预测)
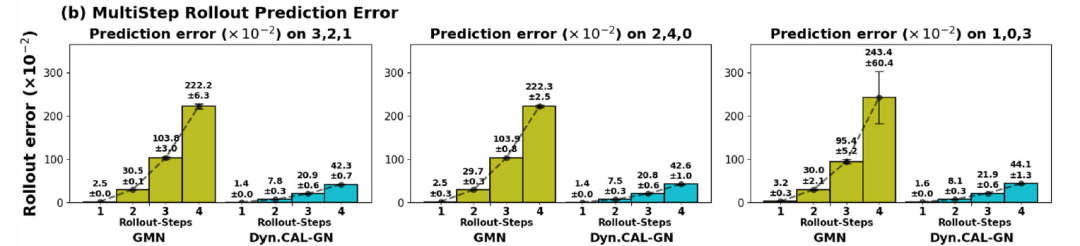
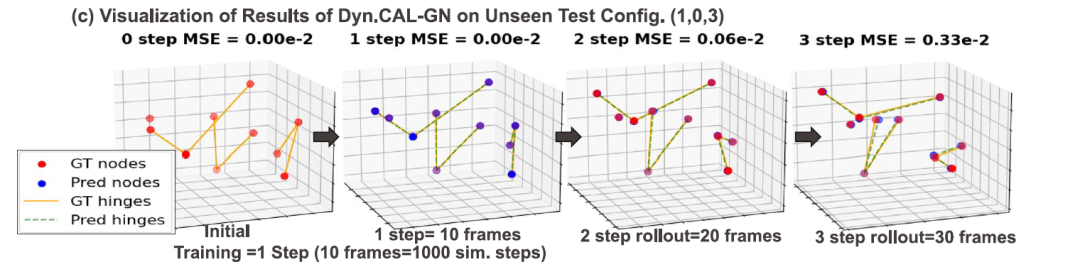
下图 c 展示了在未见过的 (1, 0, 3) 结构配置上的定性滚动预测结果。尽管模型仅在不同拓扑结构的数据上通过单步监督进行训练,研究提出的方法仍然能够准确捕捉受约束系统的动力学行为。
约束 N 体基准测试中的性能表现(定性滚动结果)
人体运动预测
在人体运动捕捉数据上,尽管模型只使用单步监督训练,但在多步预测中仍能保持稳定轨迹,这表明模型成功学习到了人体运动中的时空动力学结构。
下图 a 展示了 CMU 人体步行基准上的单步预测精度,结果表明:DYNAMI-CAL GRAPHNET 在所有方法中取得最低误差,它优于 GMN。GMN 使用 19 个关节表示人体骨架,并通过 6 条人工定义的刚性连接,再通过手工设计的正向运动学模块(Forward Kinematics, FK)强制执行约束。
CMU 运动捕捉基准测试(受试者 #35,步行)的性能表现(单步预测误差)
下图 b 表明:尽管模型仅使用单步监督进行训练,DYNAMI-CAL GRAPHNET 在多步滚动预测中仍能保持稳定精度,而 GMN 很快出现发散。
CMU 运动捕捉基准测试(受试者 #35,步行)的性能表现(多步滚动预测误差)
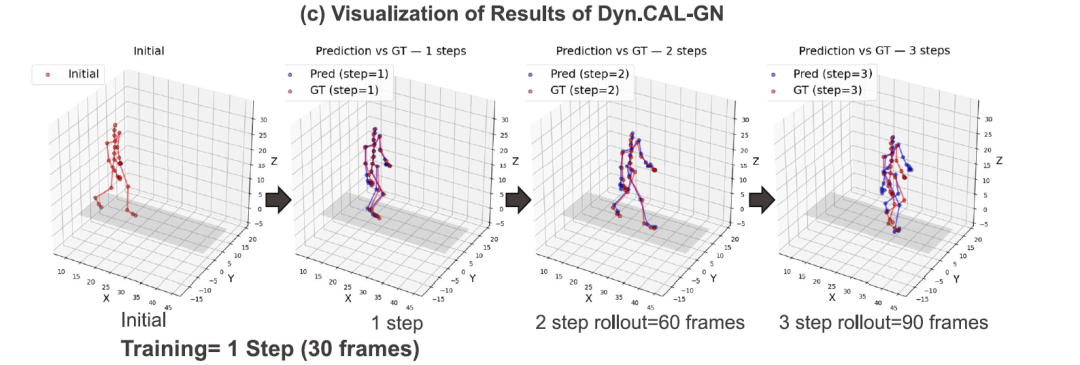
下图 c 的定性结果进一步说明:预测得到的关节轨迹连续一致,物理上合理,且与真实运动高度一致,在 90 帧未来预测中仍能保持稳定。
CMU 运动捕捉基准测试(受试者 #35,步行)的性能表现(定性滚动预测结果)
蛋白质动力学
最后,研究人员还评估了模型对复杂、由热扰动驱动的蛋白质动力学的建模能力。结果表明:DYNAMI-CAL GRAPHNET 在复杂细粒度系统(如蛋白质)中具有卓越的动力学建模能力,其不仅能够捕捉到微观结构振动,还能够预测大尺度构象变化,其预测精度超过多种基线方法。
从物理模拟到具身智能的世界模型
随着人工智能技术的发展,一个新的研究方向正在迅速升温——具身智能(Embodied AI)。与传统人工智能主要处理文本或图像不同,具身智能强调智能体与真实物理世界的交互能力,机器人、自动驾驶系统以及智能制造设备,都属于具身智能的重要应用场景。在这些系统中,智能体不仅需要感知环境,还需要预测环境变化,并据此制定行动策略。这意味着它必须具备一种能力:理解和预测物理世界的动态行为。
近年来,越来越多研究者提出一个概念——世界模型(World Model)。所谓世界模型,是指一个能够模拟环境动态变化的内部模型,使智能体可以在「脑海中」预测未来。然而,构建真实可靠的世界模型并非易事。现实世界中的物体运动通常受到复杂的物理规律约束,例如动量守恒、摩擦力以及碰撞动力学,如果模型无法准确刻画这些规律,预测结果很容易在多步推理中逐渐偏离现实。在这一背景下,像 DYNAMI-CAL GraphNet 这样的物理信息神经网络,为具身智能的发展提供了一种新的技术思路。
除此之外,业界在高效、精确地预测复杂物理系统的演化方面也有重要进展。物理系统往往跨越多个时间尺度和空间尺度演化,而多数学习模型通常仅在短期动力学上进行训练,一旦被用于长时间尺度预测,误差便会在复杂系统中不断累积,导致模型不稳定。
在此背景下,来自 Polymathic AI 协作组的研究团队引入了一系列新方法来应对上述挑战,他们提出了一个拥有 13 亿参数、以 Transformer 为核心架构、主要面向类流体连续介质动力学的基础模型 Walrus。Walrus 在预训练阶段覆盖了 19 种高度多样化的物理场景,涵盖天体物理、地球科学、流变学、等离子体物理、声学以及经典流体力学等多个领域。实验结果表明,无论在下游任务的短期预测还是长期预测中,Walrus 均优于此前的基础模型,并且在整个预训练数据分布范围内都展现出更强的泛化性能。
* 论文标题:Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
* 论文链接:https://arxiv.org/abs/2511.15684
物理 AI 模型的构筑,一方面,可以帮助科学家更高效地模拟复杂系统,例如分子动力学、材料科学以及气候模型;另一方面,它也能够为智能机器人提供更真实的世界理解能力。从某种意义上说,让人工智能真正理解物理世界,也许正是迈向通用人工智能的重要一步。
参考文献:
1.https://www.nature.com/articles/s41467-025-67802-5
2.https://mp.weixin.qq.com/s/fElxywueQ_an44rXkbjZ1A
