华为AgentInfer框架通过协同优化推理架构与系统,端到端提升Agent生产效率2.5倍,在高并发下保持稳定,减少无效token消耗。
原文标题:告别Demo、真正跑进生产,华为新框架把Agent端到端效率拉升2.5倍
原文作者:机器之心
冷月清谈:
怜星夜思:
2、AgentCompress模块中,既要压缩上下文,又要保留推理轨迹,这个平衡是如何把握的?仅仅保留推理轨迹就足够了吗?
3、AgentSAM模块利用后缀自动机进行跨会话投机解码,这个方法听起来很酷,但具体是如何工作的?有没有可能出现投机失败的情况,导致性能下降?
原文内容

大模型 Agent 正在从 Demo 走向生产:多轮推理、工具调用、长上下文记忆、并发会话同时运行…… 但也正是在这些「真实工作流」里,很多看似先进的推理加速在落地时会失效:单步推理快了,端到端却更慢;吞吐更高了,高并发下却开始抖动;压缩了上下文,Agent 反而更容易迷路、回合数暴涨。
华为诺亚方舟实验室、先进计算与存储实验室联合在最新工作中提出了AgentInfer:一个面向工业 Agent 的端到端加速框架,把「推理架构设计」和「推理服务系统」放在一起协同优化。
它不是某个单点技巧,而是一套可拆可合的系统化方案:每个模块单独启用都有收益,组合在一起仍能叠加,并且在高并发、多会话、长上下文的真实负载下依然 work。

-
论文标题:Towards Efficient Agents: A Co-Design of Inference Architecture and System
-
arXiv 链接:https://arxiv.org/pdf/2512.18337
为什么 Agent 的「加速」必须从端到端出发?
在传统 LLM 服务里,我们习惯用 tokens/s、单次延迟来衡量优化。但 Agent 的本质是一个持续运行的 Think–Act–Observe 循环:
-
每次 Think 都要带着越来越长的上下文;
-
Act/Observe 会引入异构工具延迟与并行请求;
-
一旦某一步质量下降,就会触发纠错、重试、冗余搜索,导致回合数上升、总体更慢。
团队在分析中总结了 Agent 场景的三个典型「工业坑」:
1. 量化陷阱:单步更快但精度更差,触发大量自我修复回路,端到端时间反而上升。
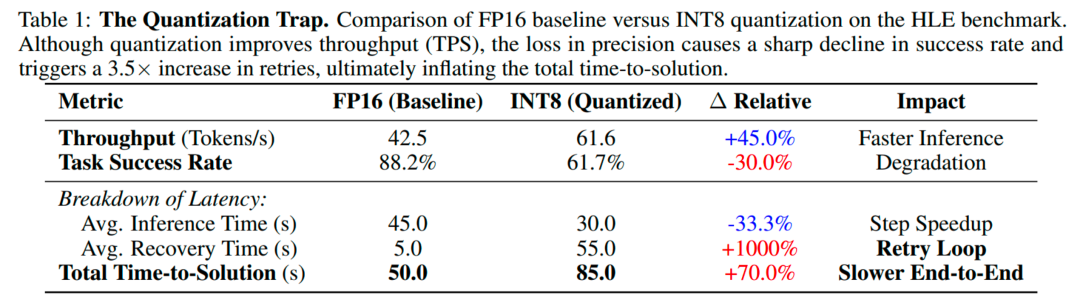
2. 文本总结不靠谱:大量的研究工作展示可以通过对过程信息总结来进行 token 压缩,但是本文的实测发现,很多场景中引入总结后单轮变短了,但是整体轮次变多了,甚至降低了精度。
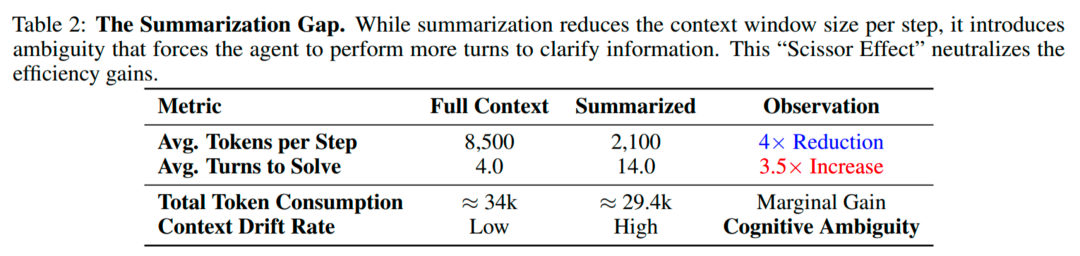
3. 记忆持久性瓶颈(KV-cache):高并发下,常见的短作业优先(SJF)会频繁淘汰长上下文会话的 KV-cache,导致下一轮被迫重算大段 prefill,延迟尖刺明显,系统吞吐和稳定性一起掉。
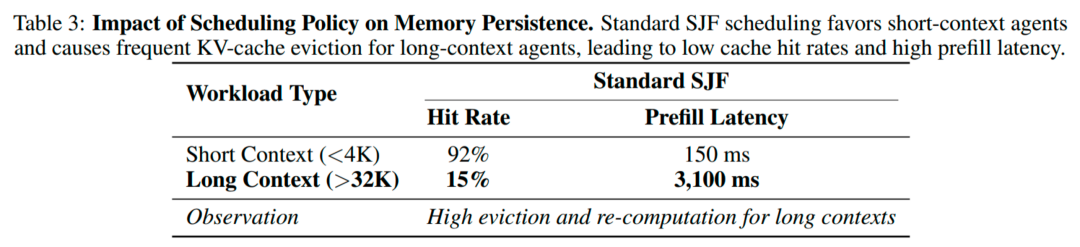
结论很直接:Agent 的效率不是「每步快一点」,而是「更少的无效回合、更少的重算、更高的跨轮次复用」。
AgentInfer:四个可独立部署、可叠加增益的模块
AgentInfer 把 Agent 的端到端瓶颈拆成四类问题,并给出四个互补模块。它们分别作用在不同层次:有的减少「用大模型的次数」,有的控制「上下文变长」,有的提升「并发下的缓存命中」,有的加速「token 级生成」。
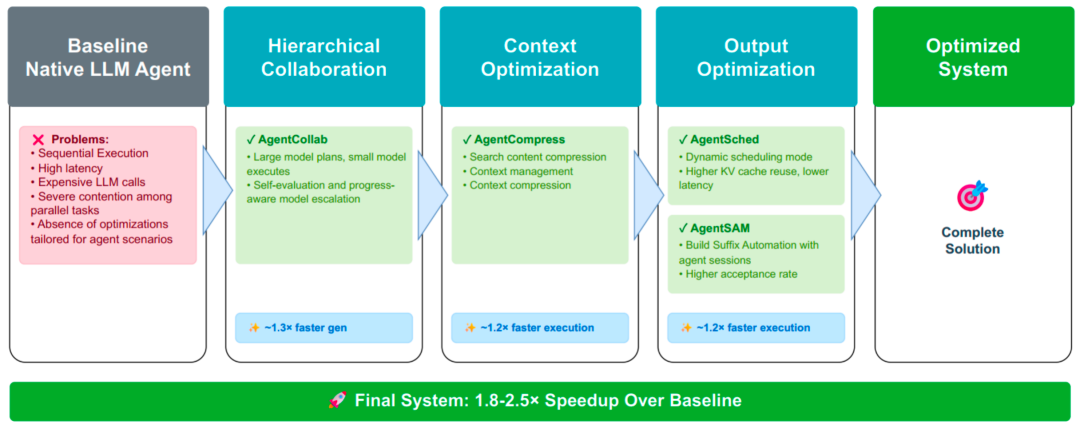
1)AgentCollab:难度感知的大小模型协作(少用大模型,但不掉质量)
核心思路是把常规工作交给小模型,把关键规划与卡住的推理交给大模型。关键不在「静态分工」,而在一个结构化的 Progress Check 自评机制:每一步判断「是否取得实质进展」,若停滞则升级到大模型救场;恢复进展后再降级回小模型继续跑。
这让系统在工业场景里更「像人」:多数时间用便宜模型推进流程,只有在真的困难段落才调用昂贵模型,从而在质量与成本之间更接近 Pareto 最优。
2)AgentCompress:语义压缩与异步蒸馏(压缩不等于删记忆)
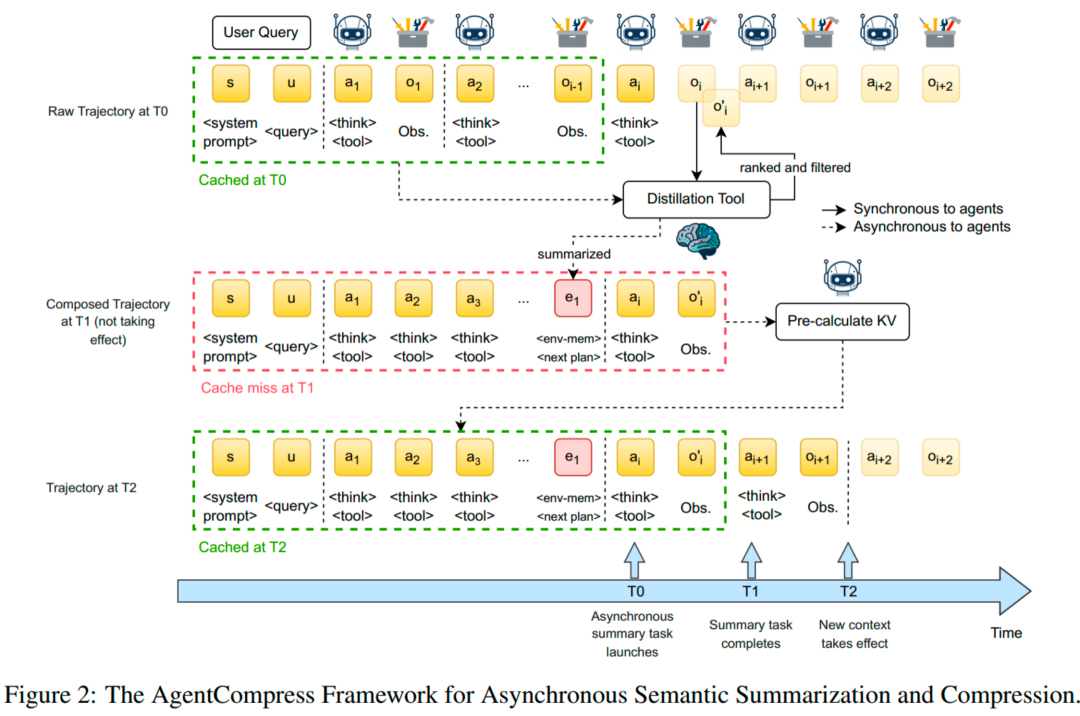
真实的深度研究 / 搜索型 Agent,上下文很快被搜索结果、网页内容、工具输出撑爆,序列长度飙升带来注意力成本激增。AgentCompress 做两件事:
-
搜索结果过滤排序:先用轻量模型把 URL / 摘要排序剪枝,减少无关内容进入后续爬虫与文档问答,降低并行工具调用压力。
-
异步上下文蒸馏:压缩工具输出等「环境交互记忆」,但关键是保留推理轨迹(reasoning memory)。团队观察到:只保留压缩后的环境信息会让 Agent 「失忆」,无法判断是否完成任务,导致回合数暴涨;保留推理轨迹才能维持认知连续性,压缩才真正带来端到端收益。
这也是工业落地里非常实用的一点:压缩必须服务于「少走弯路」,而不是只追求「prompt 变短」。
3)AgentSched:KV-cache 感知的混合调度(高并发下依然稳定)
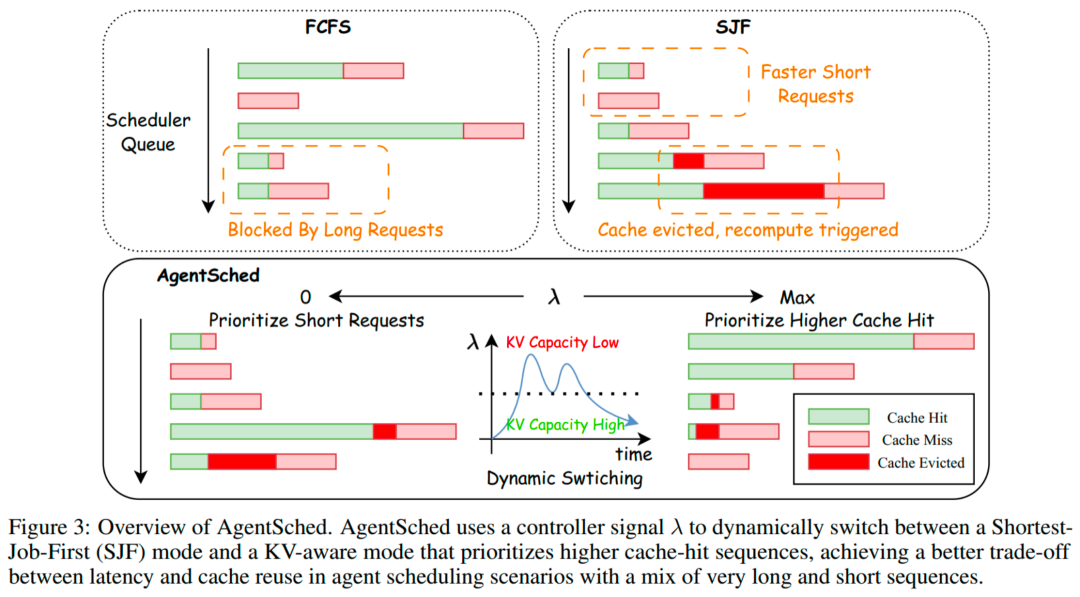
在多会话并发中,短请求和超长上下文请求会同时出现。纯 FCFS 会被长请求阻塞,纯 SJF 又会牺牲长会话的 KV-cache 持久性,导致反复重算前缀、延迟尖刺。
AgentSched 引入一个可解释的控制信号(shadow-price),在「优先短请求低延迟」和「优先高 KV 复用」之间自适应切换:
-
缓存宽松时更像 SJF,快速响应短请求;
-
缓存紧张时更偏 KV-aware,保护长会话上下文,减少昂贵 prefill 重算。
这解决的是「工业高并发下仍然 work」的关键:不是某一次跑得快,而是在压力上来时系统不抖、不崩、吞吐还能上去。
4)AgentSAM:跨会话投机解码(把「重复模式」变成真加速)
Agent 推理中常出现高重复:同一任务多轮反复提问、相似用户请求复用模板、检索证据被多次引用。AgentSAM 用后缀自动机(SAM)把当前会话与语义相似的历史会话组合起来,为投机解码提供更高命中率的草稿;同时用异步构建避免长上下文下 SAM 构建阻塞首 token 延迟,并带有自适应开关:当 batch 太大、投机收益变差时自动回退,避免「为了投机而投机」。
工业可用性的证据:高并发下 QPS 仍能持续提升
在 BrowseComp-zh / DeepDiver 深度研究型 Agent 基准上,我们把四个模块集成到同一套服务栈中进行端到端评估。
结果显示两点:
1)它不是实验室「单请求优化」,而是高并发下依然能跑的系统
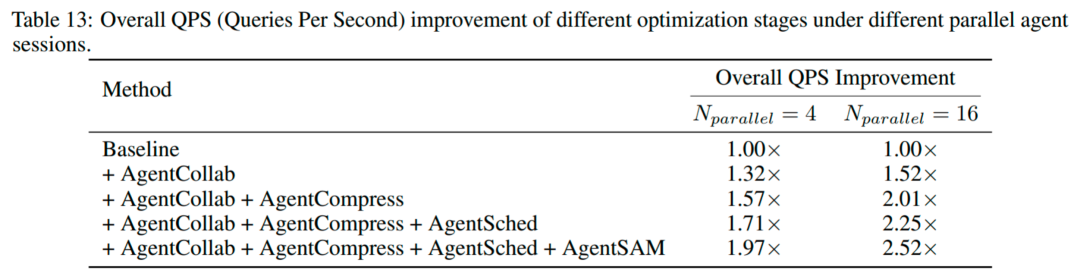
在并发会话数提升时(例如从 4 提升到 16),系统仍然能稳定获得收益,QPS 提升可达 2.52×。这意味着优化不仅对单次推理有效,更能在资源争用、缓存压力、长短请求混合的真实负载里保持稳定。
2)它不是「只能全套上」,而是模块化、可组合、增益可叠加
团队做了逐步叠加实验:
-
只上 AgentCollab 就有提升;
-
再加 AgentCompress、AgentSched,收益继续增长;
-
最后加 AgentSAM,整体进一步提升(并且在高并发下会根据收益自动启停投机,避免副作用)。
这正是 AgentInfer 的设计目标:每个组件解决一类确定的工业瓶颈;组合起来仍能协同增益,而不是相互抵消。
写在最后:Agent 的效率问题,本质是「系统问题」
AgentInfer 想强调的并不是「把某个指标卷到极致」,而是一个更现实的工程结论:
真正能落地的 Agent 加速,必须同时优化推理架构与推理系统,并且以端到端任务完成为目标。
团队在实验中观察到:AgentInfer 能将无效 token 消耗降低 50%+,实现 1.8×–2.5× 的端到端加速,同时保持任务准确率稳定。
当 Agent 进入生产环境,决定体验的往往不是单步 tokens/s,而是「少走弯路、少重算、抗并发」。这也是我们把 AgentInfer 定位为一套 Self-Evolution Engine(自演进引擎)的原因:它让 Agent 在长周期任务与高并发环境中,依然保持效率与认知稳定。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com