LongHorizonUI通过增强感知、深度反思决策与补偿式执行,显著提升GUI智能体在长链路任务中的成功率,并在LongGUIBench基准测试中表现出色。
原文标题:ICLR 2026 | LongHorizonUI:让 GUI 智能体不再"半途而废"——面向长链路任务的统一鲁棒自动化框架
原文作者:机器之心
冷月清谈:
怜星夜思:
2、LongHorizonUI在游戏场景中的表现也很亮眼,但游戏环境通常比通用应用更复杂多变。你认为LongHorizonUI在游戏自动化方面还有哪些潜在的应用场景和发展方向?
3、LongHorizonUI框架中的深度反思决策模块(DRD)通过三级闭环推理来保证决策的准确性。你认为这种反思机制在其他AI应用中是否也适用?如果适用,可以应用在哪些领域?
原文内容

在移动端和桌面端的日常使用中,许多操作并非点一下按钮就能完成。预订一场会议、在游戏商城中购买并装备一件道具、又或者在多个应用之间完成一组连贯的工作流 —— 这些任务通常需要十几步甚至几十步的连续交互。近年来,基于多模态大语言模型(MLLM)的 GUI 智能体在自动化操作上取得了不少进展,但一个很现实的问题始终存在:当任务步数超过 10–15 步,智能体的成功率会出现断崖式下跌。
为解决这一问题,来自中国科学院大学、佐治亚理工学院、南开大学与腾讯互娱 Turing Lab 的研究人员共同提出了 LongHorizonUI,一个面向 GUI 智能体长链路任务的统一鲁棒自动化框架。该成果已被 ICLR 2026(The Fourteenth International Conference on Learning Representations)接收。论文提出了增强感知、深度反思决策与补偿式执行三大核心模块,并构建了首个专注于长链路场景的评测基准 LongGUIBench,系统地推动了 GUI 自动化在复杂真实场景中的可靠落地。

-
论文标题:LongHorizonUI: A Unified Framework for Robust Long-Horizon Task Automation of GUI Agent
-
论文链接:https://openreview.net/pdf?id=BK7Mk5d4WE
-
主页:https://kane2kang.github.io/LongHorizonUI/
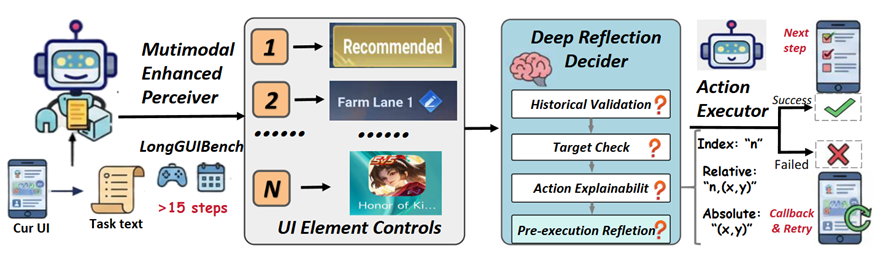
长链路场景下,智能体为何 "撑不住"?
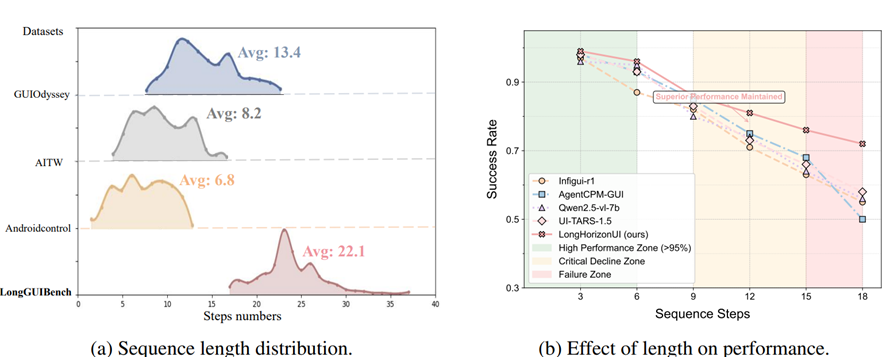
研究团队首先在 AndroidControl 基准上对多个主流方法做了按步长分段的性能评估。结果很直观:当操作序列在 5 步以内时,各方法的平均成功率超过 90%;但一旦序列长度超过 10 步,成功率便跌破 75%;到了 15 步以上,平均仅剩约 60%。
这种非线性的性能衰减说明,现有方法在长链路中无法有效捕捉跨步状态依赖,感知漂移、定位偏差和决策误差逐步叠加,最终导致整个流程崩溃。既有的公开基准大多聚焦于短任务(典型不超过 10 步),也难以充分暴露这一问题。
于是研究团队提出了一个核心问题:如何让 GUI 智能体在长步骤操作序列中始终保持上下文一致性与决策准确性?
覆盖应用及游戏的长链路场景评测方案
为了在长链路场景下开展系统性评测,研究团队构建了一个新的基准,所有任务的操作步数均不低于15 步,平均为 22.1 步。
数据集包含两大类场景。通用应用场景涵盖了 Gmail、YouTube 等 15 款主流应用,共 147 条端到端任务链,平均步数 19.5,涉及多级菜单导航、实时输入验证等典型交互行为。游戏场景则由专业测试人员在 13 款热门游戏 APP 中录制,共 207 条高复杂度链路,平均步数 23.7,最长可达 37 步,覆盖装备管理、活动参与等核心游戏机制。
每条任务同时提供两级指令标注:High-Level 指令描述宏观目标(如 "在游戏商城购买 XX 道具"),Low-Level 指令则分解为原子操作序列(如 "点击商城按钮"→"选择购买")。所有操作步骤均配有精细的 UI 语义标注,包括控件类型、bbox 坐标和状态属性。全部数据合计 4508 张截图,经 6 位专业人员跨模态对齐和人工去噪后生成标准化标注。
核心方法:三大模块协同工作
LongHorizonUI 的核心设计理念是将 "语义决策" 到 "物理执行" 之间的不确定性做分层处理。框架由三个模块组成,形成感知 — 决策 — 执行的完整闭环。
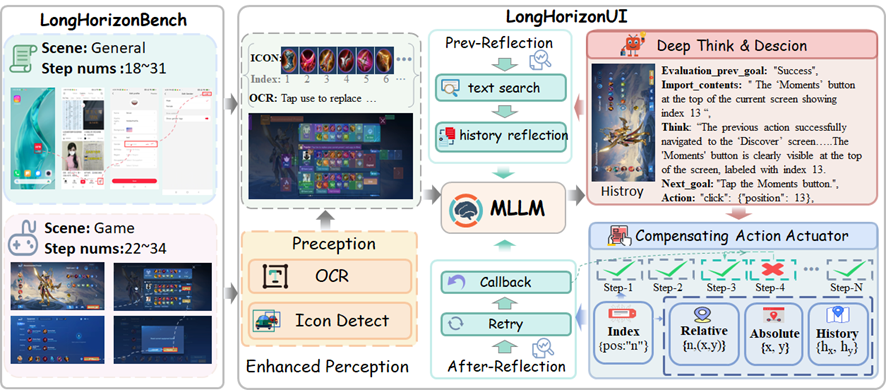
多模态增强感知模块(MEP) 并行运行控件检测器与 OCR 识别模块,为屏幕上每个 UI 元素分配唯一的空间索引 ID,作为后续所有环节的稳定锚点。为了解决 "图标 + 文字" 这类复合控件的歧义问题,MEP 引入了基于 IoU 的语义绑定机制 —— 当图标检测框与 OCR 文本框的交并比超过设定阈值时,将二者关联为同一语义实体。此外,针对弹窗关闭按钮等容易漏检的关键元素,MEP 在高优先区域设置了模板匹配修复机制,确保不会因漏检而卡住整个流程。
深度反思决策模块(DRD) 通过严格定义的 JSON Schema 输出格式,强制模型进行三级闭环推理。第一级是历史验证,检查上一步操作是否成功执行,UI 状态转换是否符合预期;第二级是目标检查,提取当前屏幕的关键信息并与任务目标进行一致性比对;第三级是动作可解释推理,要求模型在给出执行指令之前先说明当前界面状态、定位依据和操作理由。在执行前,DRD 还会校验目标元素是否确实存在于当前屏幕上、动作语义是否与任务描述匹配,不满足条件的动作会被拒绝并触发修正。
补偿式执行器(CAE) 负责将决策层输出的动作指令映射到屏幕上的物理坐标。执行时按优先级依次尝试三种定位策略:首先通过元素索引定位到控件质心点击;若失败则在检测框内随机采样一个点进行相对定位点击;仍然失败则回退到屏幕绝对坐标并添加微小扰动以应对边缘遮挡情况。每次点击后,MLLM 会对新截图进行验证判断操作是否成功。当所有候选方案均失败时,系统触发局部重规划;若依然无法恢复,则回滚到上一个成功快照继续执行。
实验结果
在 LongGUIBench 上,LongHorizonUI 展现出对长链路任务的显著优势。在通用场景中,低级指令的步骤成功率达到 85.3%,高级指令达到 52.3%,分别较 UI-TARS-1.5 提升了 6.1% 和 30.5%。在游戏场景中同样保持明显领先,低级指令 SR 达 83.9%,高级指令 SR 达 52.1%,整体平均 77.3%。
在 ScreenSpot 跨平台 UI 元素定位基准上,LongHorizonUI 以 90.4% 的平均准确率超越此前所有开源方法,在 Mobile、Desktop、Web 三个平台上均表现稳健,尤其在 Icon 类元素上优势突出,验证了 IoU 语义绑定策略的实际效果。
消融实验进一步证实了各模块的必要性:移除控件检测器使步骤完成率下降 6.1%,移除 OCR 模块导致 2.3% 的下降并在复合控件上频繁出错,仅使用索引定位的任务完成率为 81.4%,叠加补偿策略后逐步提升至 85.3%。
此外,在 OSWorld 的 50 步长链路设置中,LongHorizonUI 达到 29.4% 的成功率,较 UI-TARS-72B 的 24.6% 提升了 4.8 个百分点,进一步验证了框架在超长链路场景下的鲁棒性。
下图展示了 LongHorizonUI 在真实任务中的逐步执行可视化,包括感知标注、决策推理和动作执行的完整过程:

总结
LongHorizonUI 为长链路 GUI 自动化任务提供了一套完整的解决方案。通过索引化感知、结构化反思决策和多级补偿执行的协同设计,它有效缓解了长步骤操作中的误差累积问题,在多个基准上取得了一致的性能提升。同时构建的 LongGUIBench 基准也为该领域后续研究提供了标准化的评测平台。
作者介绍
温少国,本科、硕士均毕业于北京邮电大学,现任腾讯高级算法研究员。长期从事计算机视觉、多模态大模型、智能体(Agent)等领域的研究与工程实践,在相关方向拥有多年技术积累与研发经验。
康斌,中国科学院大学成都计算机应用研究所博士研究生(同时在哈尔滨工业大学(深圳)联合培养),导师为陈斌研究员和田倬韬教授,研究方向聚焦于多模态视觉感知与交互,研究成果发表于:ICLR、ACMMM、CVPR、AAAI、ICME 等国际会议与期刊。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com