清华联合美团推出3DThinker,让多模态大模型在推理时内在地“想象”三维场景,无需额外标注或工具,显著提升空间理解能力。
原文标题:CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 3DThinker 具备一定的可解释性,可以通过 projector 恢复出 3D 表示。这种可解释性对 VLM 的发展有哪些意义?如果让你来设计,你会如何进一步提升 3DThinker 的可解释性?
3、3DThinker 的核心在于让模型在推理过程中自发“脑补”出三维场景。你认为这种“思维即几何”的设计哲学,对于未来 AI 的发展有哪些潜在的应用价值和影响?
原文内容

大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
为此,清华大学联合美团研究团队推出 3DThinker—— 首个 3D 版的「think with image」!

-
论文地址:https://arxiv.org/pdf/2510.18632
-
代码地址:https://github.com/zhangquanchen/3DThinker
接下来,就来看看 3DThinker 是如何做的。
从「think with image」到「think with 3D」
多模态大模型的推理能力提升一直以来是研究的重点和热点。人类往往能够根据几张拍摄的 RGB 图像中推断空间关系,而当前多模态大模型在空间理解任务上表现较弱。背后的核心原因在于多模态大模型缺乏对图像中几何信息的提取能力。
为解决此问题,之前的方法可以分为两类:
-
依赖纯文本或二维视觉线索的强推理(例如进行认知图的推理),这类方法往往依赖于繁琐的数据标注;
-
通过输入增强(例如引入深度图、点云等先验信息),这类方法往往依赖于外部工具调用,不是内蕴的模型能力,且推理存在负担。
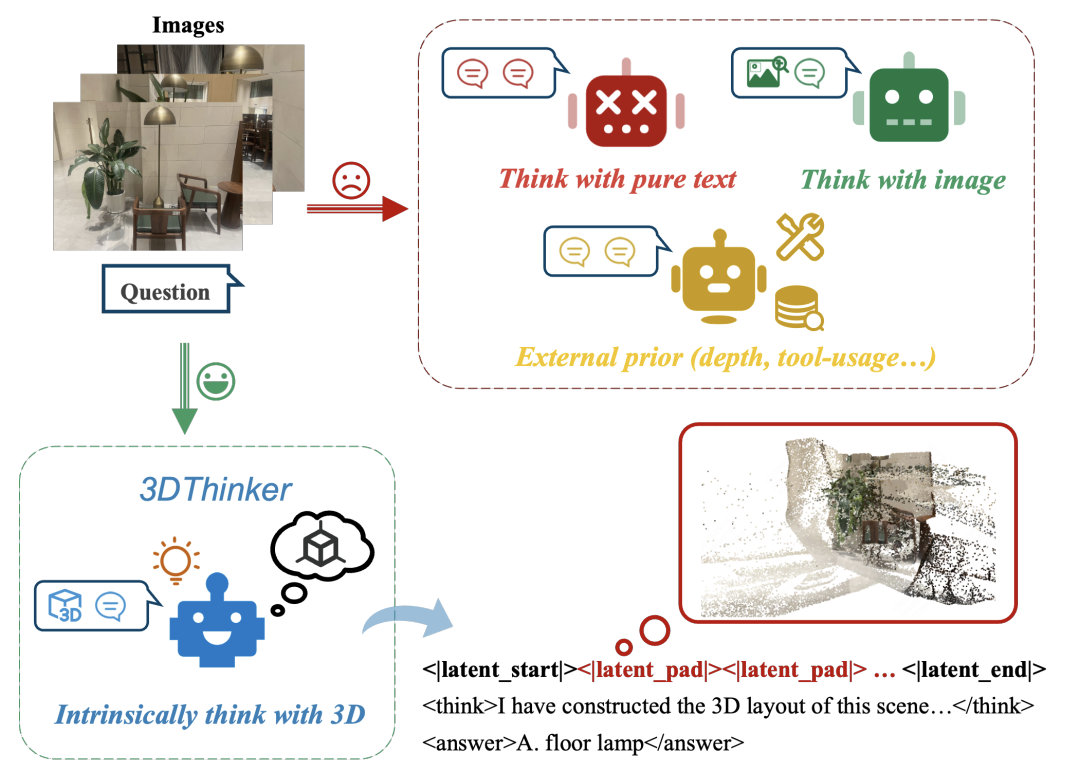
而 3DThinker 提出了一种全新的思路,在无需 3D 标注(例如点云)、无需外部工具的情况下,让模型在推理过程中内蕴地「想象」三维场景。
具体来说,该框架让模型在生成推理链时,自动插入一段紧凑的隐变量,作为其脑内构建的三维场景表征,这段生成的表征通过蒸馏 3D 基础模型(VGGT)来获得。
核心思路:二段式学习用 3D 思考
3DThinker 提出了双阶段的训练策略来完成潜空间对齐,包括:(i) 监督训练过程中,将预训练的 3D 特征蒸馏进入模型推理路径,实现模型从二维数据的几何信息提取,而不依赖于任何先验;(ii) 强化训练过程中,在保持 3D latent 稳定的同时,仅仅依赖结果信号优化整个采样轨迹,从而实现模型的能力飞跃。
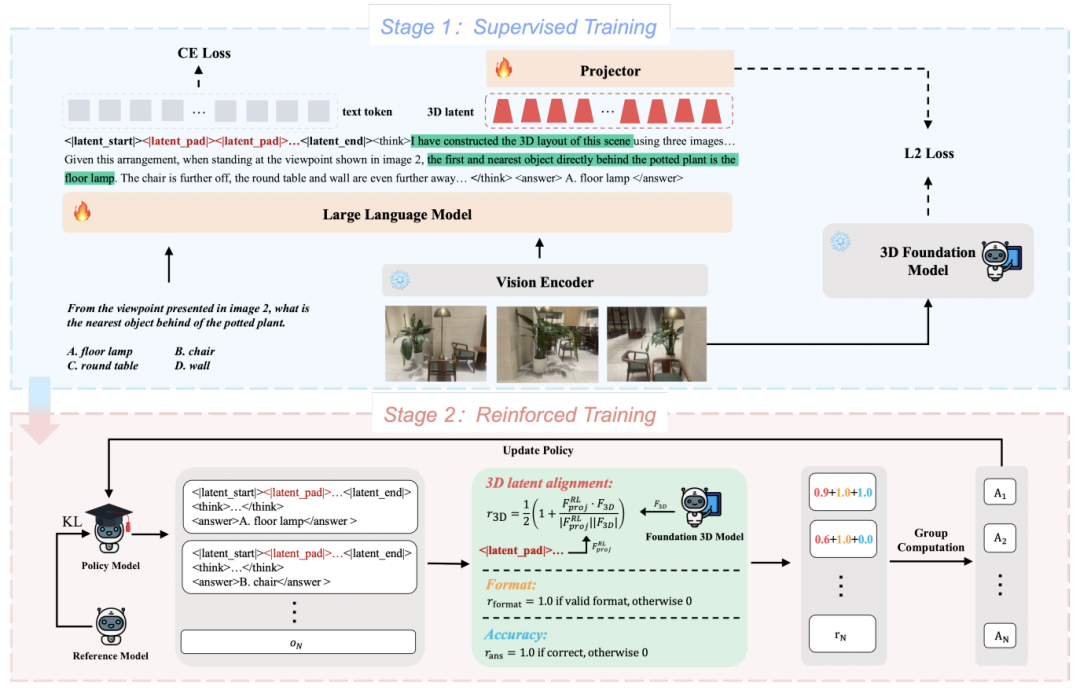
S1:以 3D 基础模型为指导,建立模型推理行为
在一阶段的监督训练中,首先构造了携带 3D special token 的 cot 数据,基于该数据进行监督训练,训练过程中,3DThinker 将对所有 special token 所对应的 3D latent(last layer hidden state)通过 projetor 映射到 VGGT 的潜空间,并将两者的对齐作为第一项损失函数:
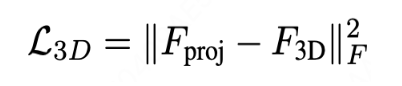
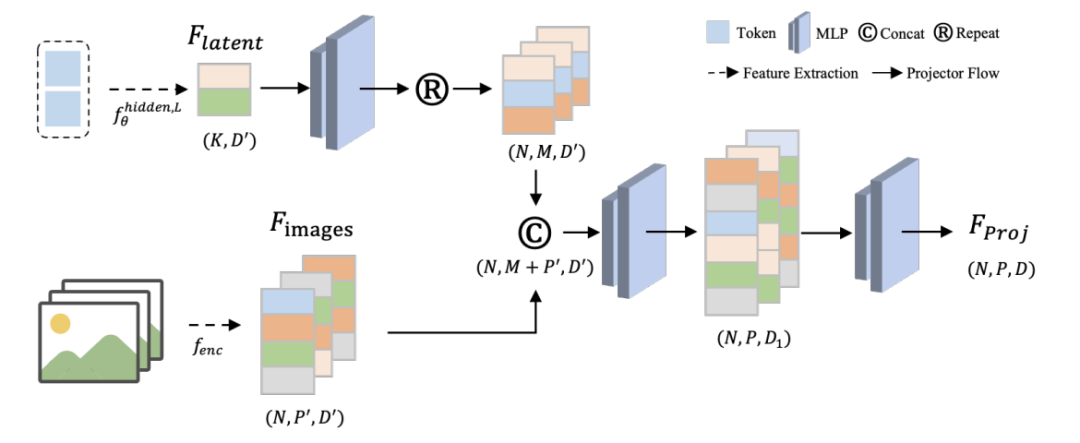
其中,projector 基于堆叠 6 层 MLP 实现三次特征维度映射,具体框图如下:
而第二项损失函数是除去 special token 后的文本交叉熵损失:
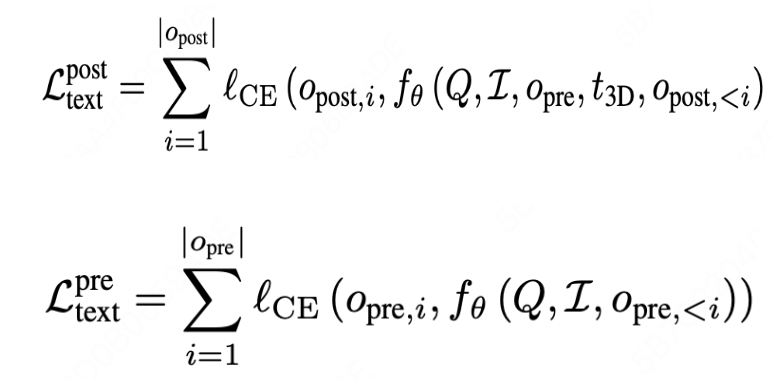
其中,第一项损失函数在于保证 3D latent 的表征对齐;第二项在于保证自然语言的连贯性嵌入。
S2:以结果信号为基础,优化含 3D 意象的轨迹
在一阶段后,已经初步实现了模型 think with 3D 的表征对齐;接下来,基于强化学习,在只有结果信号的情况下,优化整条采样轨迹,包括其中的 3D latent。
具体来说,3DThinker 设计了一个 3D latent 对齐的奖励:
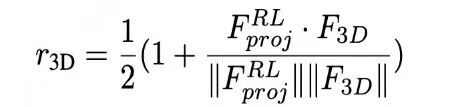
也就是说,3DThinker 会提取自回归生成的 3D latent,并于 VGGT 特征保持一致性,从而保证 RL 采样过程中不丢失几何表达。
另一方面,3DThinker 也参照先前方法的 outcome-based RL 保持了结果的二值化奖励以及格式奖励,最后基于 GRPO 进行优化。
提升到新高度的结果
论文在多个空间理解的 BMK 上验证了 3DThinker 的效果。
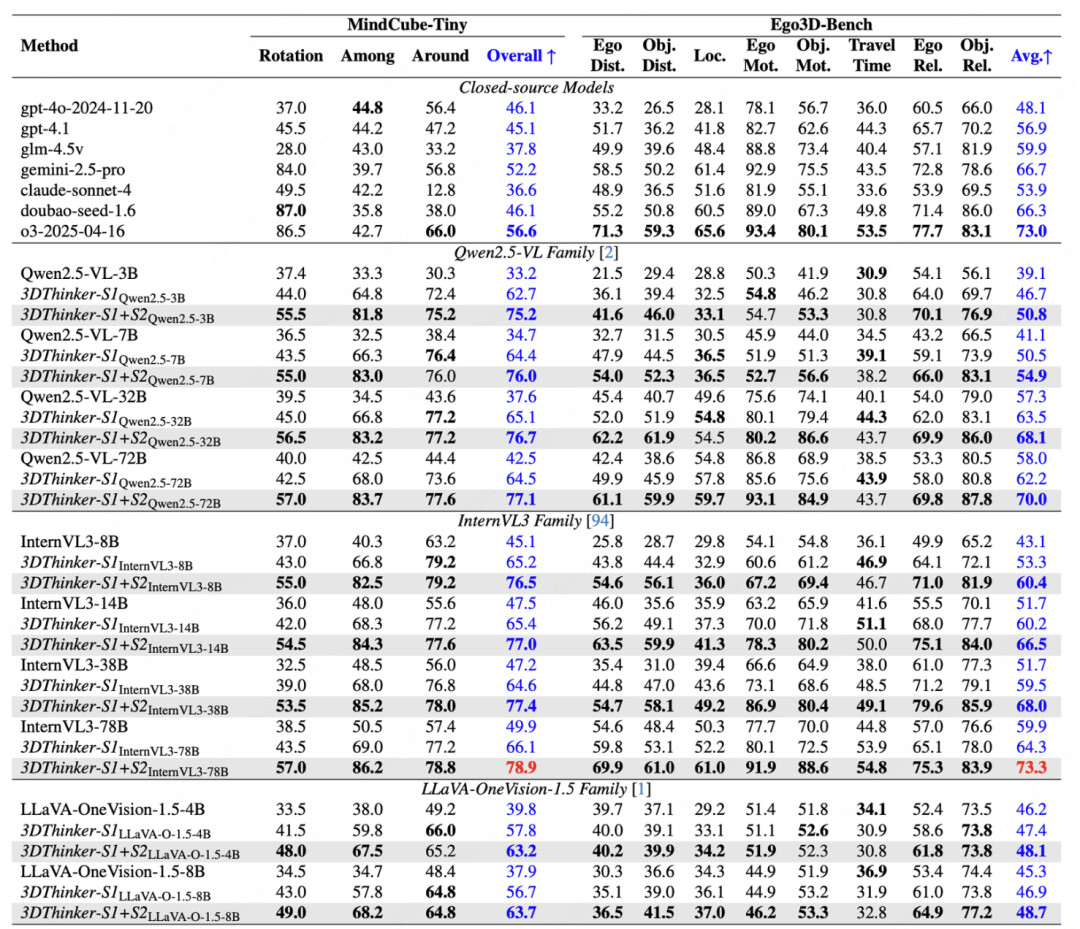
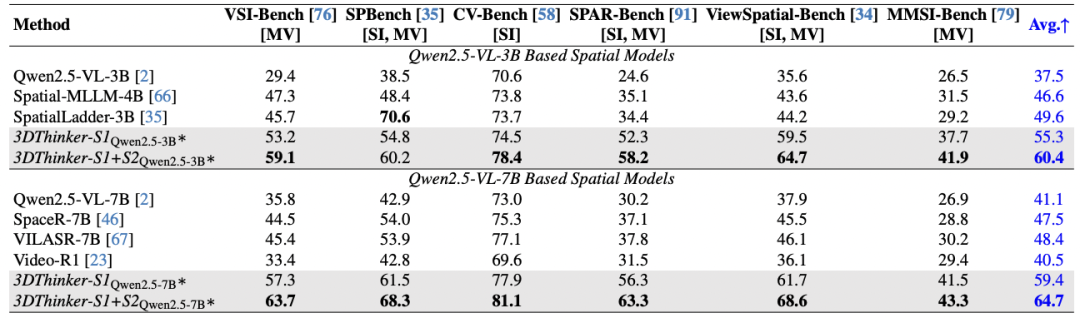
方法首先在 MindCube 的 10K 数据上构造了带有 3D special token 的推理链数据,并基于两个阶段进行训练,下表报告了训练后的模型效果,在 MindCube-Tiny 上,针对不同尺寸的模型,相比 base 整体提升了 51.8% 到 108.8%;在 Ego3D-Bench 上,则提升了 18.1% 到 36.9%。
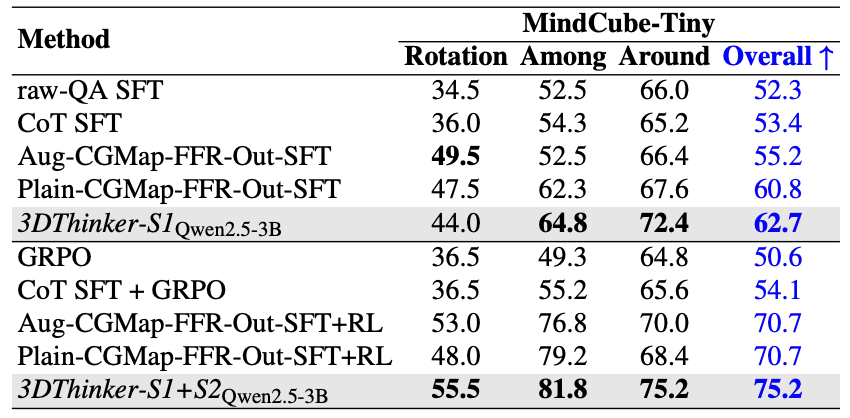
以 Qwen2.5-VL-3B 基础模型为例,在监督训练上,模型相比需要 CGMap 标注的训练超过了 + 1.9 pp (62.7 vs. 60.8);加入强化学习后,3DThinker 也获得了 + 4.5 pp (75.2 vs. 70.7) 的提升,彰显了 3DThinker 训练方法的有效性。
另一方面,以自制的大规模训练数据为基础,模型进一步在更多全面的测试基准上进行了评估。
以 Qwen2.5-VL-3B 为例,该方法相比之前的 SOTA +10.8 pp(49.6->60.4);以 Qwen2.5-VL-7B 为例,该方法相比之前的 SOTA +16.3 pp(48.4->64.7)。结果显示,3DThinker 提升到一个新的水位,在各类基准上均出现了显著提升的迹象。
可解释性
3DThinker 的另一个显著特征在于某种程度上具备可解释性。
这意味着,3D latent 通过设计的 projector 可以直接恢复出 3D 表示,从而使模型推理不再完全「开黑盒」。有趣的是,3DThinker 观察到,和 prompt 高度相关的区域点云密度往往更高。

写在最后
从「看图说话」到「看图想空间」,3DThinker 打开了 VLM 推理一种新的思路。
3DThinker 巧妙之处,在于它找到了一条「无监督蒸馏」的路径:不需要昂贵的 3D 标注数据,也不依赖外部深度传感器,而是让模型在推理过程中自发「脑补」出三维场景。
这种「思维即几何」的设计哲学,某种程度上复刻了人类的空间认知本能。当 3D 想象与具身智能结合,当空间推理可以实时反馈修正,或许正在接近一个能真正「看懂」物理世界的 AI。
作者简介
本文第一作者为陈樟权,清华大学数据科学和信息技术博士在读。研究方向为多模态大语言模型推理、强化学习、三维视觉。在 CVPR、ICCV、ICLR 等人工智能顶级会议或期刊上发表论文近 10 篇。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com