OpenClaw结合DuckDB,让AI学会电商销售预测。通过自动化数据分析迭代闭环,实现模型自优化,提升预测准确率和效率。
原文标题:OpenClaw Skill × DuckDB:一个会自动进化的电商销售分析预测是怎么炼成的
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到模型自动选择,选择了7种模型中误差最小的,实际业务中,除了预测误差,还有哪些因素会影响模型的最终选择?
3、Skill系统让AI能够按照流程执行任务,那么,如果Skill本身编写错误或者流程存在逻辑问题,有什么机制可以发现并纠正这些错误?
原文内容

一、OpenClaw的操作手册——Skill 系统是什么?
先说一个反直觉的事实:
AI 什么都懂,但什么都"不会做"。
你问 ChatGPT"北京明天天气怎么样?",它答不上来。不是它笨,而是它没法联网查实时数据。它的知识停留在训练数据截止的那一刻。它就像一个博学多才但被关在图书馆里的学者,读了很多书,但看不到窗外是晴天还是下雨。
不只是天气。你让 AI 帮你关灯、帮你查 GitHub 上的 issue、帮你发一条消息,它都做不到。它知道这些事情是什么,但它没有手脚去做。
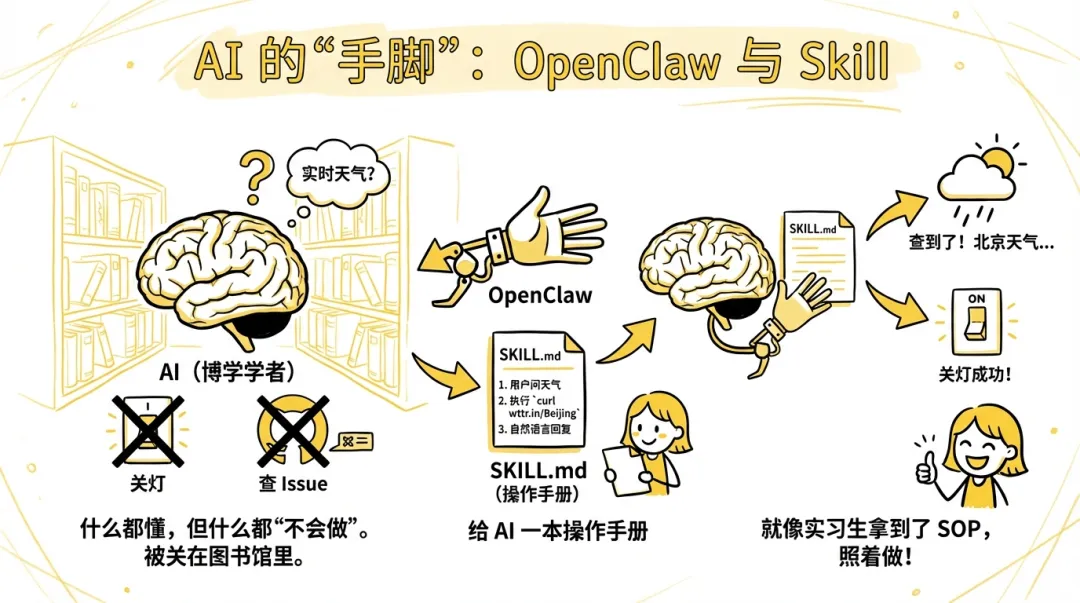
OpenClaw 解决这个问题的方式很巧妙:给 AI 一本操作手册(Skill)。
什么是 Skill?就是一个 Markdown 文件(SKILL.md),里面用人类语言写着操作步骤。比如一本"查天气"Skill,核心内容就几行:
-
用户问天气时,执行 curl wttr.in/Beijing 这个命令
-
拿到结果后,用自然语言回复用户
OpenClaw 读到 SKILL.md 后就会照着做,就像实习生拿到了 SOP,不需要额外培训就能上手。
OpenClaw 内置了 50 多本这样的Skill,覆盖天气查询、GitHub 操作、智能家居控制,甚至"指挥其他 AI 写代码"。但更厉害的是,你可以自己写新的 Skill,教 AI 做任何你想让它做的事。
每本 SKILL.md 从"放进去"到"被 AI 使用",经过 5 步流水线,加上 1 条后台常驻的监听线程:
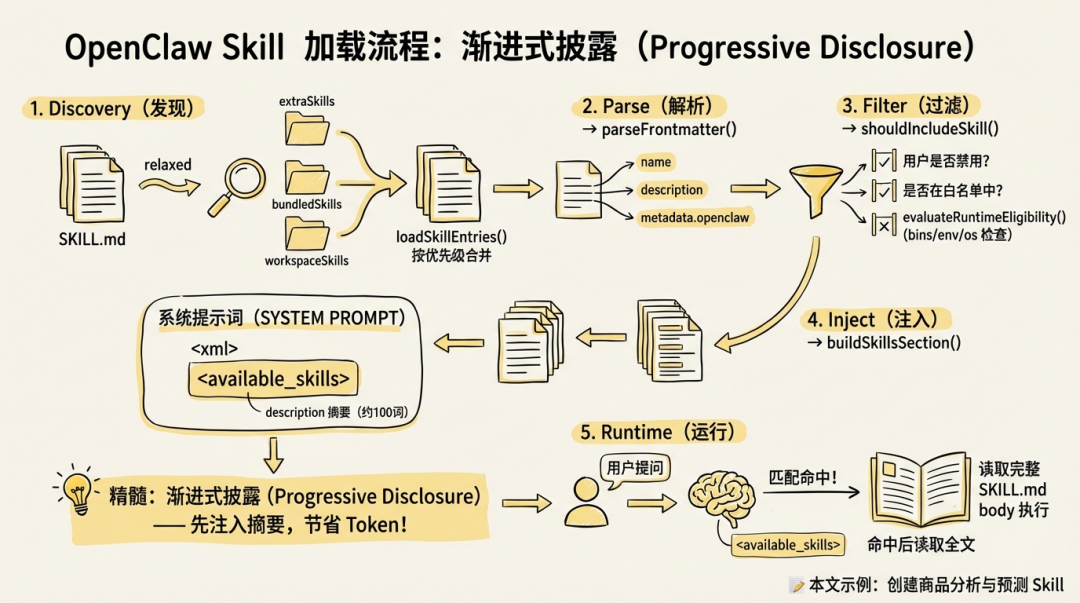
|
阶段 |
在做什么 |
产出 |
|
Discovery |
扫描 6 个目录找到所有 SKILL.md,按优先级合并,自定义的会覆盖内置的 |
|
|
Parse |
读取 YAML 封面,提取名字、描述、依赖条件等结构化信息 |
|
|
Filter |
过三道关:用户禁用了吗?依赖工具装了吗?系统兼容吗?不通过直接丢弃,AI 看不到它 |
过滤后的 |
|
Inject |
把通过筛选的 Skill 打包成一段 XML 塞进系统提示词,每个 Skill 只有摘要,约 100 词 |
|
|
Runtime |
用户提问时 AI 扫描摘要匹配,命中后读取完整 SKILL.md 正文执行 |
— |
|
Watch |
文件保存 → |
新 |
纵向看"产出"那一列:Skill[] → SkillEntry → SkillSnapshot,这就是一条 SKILL.md 在内存里的完整变身路径。
这套流程的精髓是渐进式披露(Progressive Disclosure),不一次性把所有 SKILL.md 的 body 塞给 AI(那样会超出 token 限制),而是先注入 description 摘要(约 100 词/个),匹配命中后才读全文。
本文中,我们会通过创建一个基于 RDS DuckDB 分析型实例的商品分析与预测 Skill 来详细介绍下 OpenClaw 的 Skill 原理。
二、电商数据分析与预测的烦恼
2.1 先从一个简单的场景说起
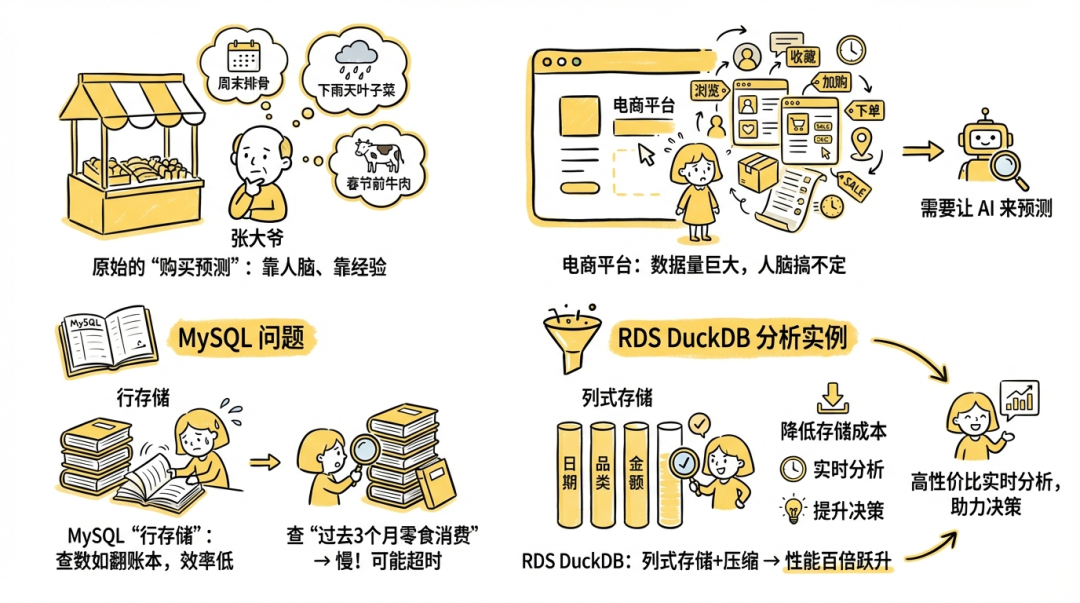
张大爷在菜市场卖了 20 年菜。每天下午他都会想:明天进什么货?
凭经验,他知道:周末排骨好卖、下雨天叶子菜不好卖、春节前牛肉必须多进。这就是最原始的购买预测,靠人脑、靠经验。
但如果张大爷不是一个菜摊,而是一家日均百万订单的电商平台呢?
几千万用户、几十万 SKU,每天产生上亿条浏览、收藏、加购、下单记录,不同地区、不同季节、不同促销活动,规律完全不同。人脑搞不定了。需要让 AI 来当张大爷,翻阅所有人的购买记录,找到规律,预测谁在未来 7 天会买什么。
2.2 但 AI 翻账本存在大问题
电商的交易数据存在 MySQL 数据库里。MySQL 是一个非常优秀的记账员,每秒处理几万笔交易,稳如老狗。但它的存储方式是行存储(一行一行地存),适合写入一笔订单、查一个用户的最近订单这类操作。可如果我们问它"过去 90 天,按品类统计所有用户的购买频次和金额",这需要扫描几亿行数据。MySQL 可能要跑几个小时,甚至直接超时。
行存储就像一本按日期排列的流水账。我们要查"过去 3 个月所有人的零食消费",就得从头到尾一页一页翻,因为零食消费散落在每一天的各种订单里。
而我们可以通过 RDS DuckDB分析实例可以实现了复杂分析查询性能百倍跃升。通过列式存储压缩技术,显著降低存储成本,为企业在海量数据规模场景下提供高性价比的实时分析能力,提升企业数据驱动型决策效能。更多介绍请参考附录 DuckDB分析实例。
三、OpenClaw + DuckDB 完成商品售卖分析与预测
场景描述:
使用 eCommerce behavior data from multi category store 这个公开数据集中的 7 个月的数据,来验证和完成自动进化的商品售卖分析与预测 Skill。在该部分中,我们会根据商品分析与预测 Skill 来剖析 openClaw 的 Skill 能力。
3.1:环境准备
创建并配置 OpenClaw
在 RDS Custom 上简单、快速部署 OpenClaw。详情请参考附录 RDS Custom集成OpenClaw。
1.先学学习Aliyun CLi
2.根据 https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/create-and-connect-to-a-duckdb-based-analytical-primary-instance?spm=a2c4g.11186623.help-menu-26090.d_3_4_0_2.325a17e86coqAu 以及其他官方文档,创建一个规格为 8.0版本、规格为myduck.n2.large.1、磁盘大小为100G的RDS DuckDB分析型实例
3. 创建完成后需要创建高权限账号、数据库以及验证数据库连通性,根据RDS官网自行解决连接不上的问题。
3.2:下载并导入数据
-
下载数据:可以通过 附录 中的天池数据集或者 Kaggle 平台进行下载。
-
使用 MySQL 工具 LOAD DATA 导入数据。
-
或者直接让 OpenClaw 帮你编写脚本导入数据到 DuckDB 实例中
通过<该处填写附录中下载地址>下载数据集并解压。编写脚本通过MySQL load data 工具加速导入 csv 文件到<rm-xx该处填写3.1中创建的DuckDB实例名>。
3.3 构建商品分析预测 Skill
先从Aliyun Cli中学习如何调用接口,然后连接<rm-xx该处填写3.1中创建的DuckDB实例名>RDS MySQL 实例,分析下业务与实际数据,最后根据https://github.com/huanjizhou/ecommerce-predictor这个skill做出合适的调整,构建一个能够自动进化的模型能够分析业务并且预测用户行为
name: ecommerce-predictor
description: "电商用户行为时间序列预测。GradientBoosting/Lasso 预测 PV、UV、购买量。
Use when: 预测、时间序列、趋势分析、销量预测、电商预测。
NOT for: 实时风控、中国电商双 11/618、非时序分类问题。"
metadata:
OpenClaw:
emoji: "📈"
requires:
bins: ["python3"]
┌─────────────────────────────── ──────────────────────────────┐
│ 第 1 轮:10 月数据训练 → 11 月验证 → 保存结果 │
│ ↓ │
│ 第 2 轮:10-11 月数据训练 → 12 月验证 → 保存结果 │
│ ↓ │
│ 第 3 轮:10-12 月数据训练 → 1 月验证 → 保存结果 │
│ ↓ │
│ ...每导入新月份数据,就重新训练一次... │
│ ↓ │
│ 模型越来越强!📈 │
└─────────────────────────────── ──────────────────────────────┘
3.4: 自优化的四个关键机制
# 每次用「所有历史数据」训练,不是只用最新数据 train_start = '2019-10-01' # 固定起点 train_end = '2019-11-01' # 动态终点(每月推进) # 下一轮自动变成: train_end = '2019-12-01' # 包含 11 月新数据
-
保留全部历史模式(季节性、节假日、趋势)
-
新数据加入后,模型自动学习新规律
-
不会遗忘旧知识(不是在线学习)
-
但如果历史数据量变得非常庞大(例如几年甚至十年的分钟级数据),每次训练都包含“所有历史数据”会导致训练时长指数级增加。建议增加一个“窗口滑动”或“权重衰减”机制。
# 用下个月的真实数据验证准确性 val_start = train_end # 验证集开始 = 训练集结束 val_end = '2019-12-01' # 验证集结束 # 计算 MAPE、R² 等指标 mape = mean_absolute_percentage_error(y _true, y_pred) * 100
-
PV(页面浏览量)预测误差
-
购买量预测误差
-
黑五/感恩节等特殊节日的预测效果
# 每次验证结果保存到 JSON 文件 validation_history.json ├── versions: [ │ ├── version: "v20260309_134100" │ ├── train_days: 31 │ ├── best_model: "Lasso" │ ├── pv_mape: 17.50% │ └── purchase_mape: 11.63% │ ├── version: "v20260309_152600" │ ├── train_days: 61 │ ├── best_model: "GradientBoosting" │ └── pv_mape: 8.15% │ ...
-
对比不同版本的性能
-
观察模型是否随数据增加而提升
-
发现过拟合/欠拟合问题
# 训练 7 种模型,自动选最佳 models = { 'Ridge': Ridge(alpha=1.0), 'Lasso': Lasso(alpha=0.01), 'RandomForest': RandomForestRegressor(...), 'GradientBoosting': GradientBoostingRegressor(...), 'XGBoost': xgb.XGBRegressor(...), ... } # 自动选择 PV 预测误差最小的模型 best_model = min(val_results.keys(), key=lambda x: val_results[x]['pv_mape'])
-
不同数据量适合不同模型(小样本用 Lasso,大样本用 GradientBoosting)
-
自动适配数据特征,不需要人工调参
3.5:第一次预测:
我们来简单看下预测结果。在第一次预测中,RDS MySQL 分析型实例中存了 eCommerce behavior data from multi category store 这个公开数据集中的前两个月的数据。让它基于 19 年 10 月的数据构建模型,并且用 19 年 11 月的数据进行验证。
在数据洞察、迭代验证、策略调整阶段,需要连接 RDS DuckDB 实例进行查询。对比普通 MySQL 实例,DuckDB 能够加速约 700 倍。
/skill ecommerce-predictor 预测下个月的PV\UV\Purchase\Cart
|
指标 |
数值 |
说明 |
|
PV MAPE |
26.92% |
平均绝对百分比误差 |
|
购买量 MAPE |
11.39% |
购买量预测误差 |
|
黑五误差 |
45% |
黑色星期五期间误差(未考虑节假日) |
|
训练天数 |
31 天 |
2019-10-01 ~ 2019-11-01 |
|
验证天数 |
30 天 |
2019-11-01 ~ 2019-12-01 |
|
特征数 |
5 个 |
基础时间特征 |
|
模型 |
指数平滑 |
Baseline 模型 |
问题: 黑五预测误差 45%,因为模型不知道 11 月 29 日是黑色星期五。
1. 未考虑节假日 - 黑五误差 45%
2. 基线建立 - 后续版本可以对比改进
3. 特征太少 - 只有 5 个基础特征,需要增加
可以看到商品预测 Skill 不仅可以分析当前的数据、预测数据,更重要的是,能根据预测结果来优化自身的模型从而使准确率越来越高。
3.6 第二次到第六次预测
之后每导入一个月的数据,Skill 会自动完成“分析-预测-自优化”的三个步骤。
来看 HISTORY.md 中记录的数据:
|
版本 |
训练天数 |
最佳模型 |
PV 误差 |
购买量误差 |
发生了什么 |
|
v1.0 |
31 天 |
指数平滑 |
26.92% |
11.39% |
基线模型,黑五误差 45% |
|
v2.0 |
61 天 |
RandomForest |
8.15% |
23.17% |
✅ 训练数据翻倍 |
|
v3.0 |
92 天 |
GradientBoosting |
2.73% |
42.28% |
✅ PV 预测历史最优 |
|
v4.0 |
123 天 |
GradientBoosting |
2.73% |
42.28% |
✅ 正式 v1 |
|
v5.0 |
152 天 |
Ridge |
29.99% |
36.99% |
⚠️ 撞上美国疫情爆发 |
|
v6.0 |
183 天 |
GradientBoosting |
10.03% |
12.65% |
✅ 购买量预测最优 |
PV 预测(每日页面浏览量)
|
|
指标 |
v1.0 |
v6.0 |
改进 |
|
PV 预测 |
平均误差 |
26.92% |
10.03% |
↓ 62.7% |
|
黑五误差 |
45% |
- |
完全解决 |
|
|
R² |
- |
0.78 |
模型解释力优秀 |
|
|
购买量预测 |
平均误差 |
11.39% |
12.65% |
优秀水平(<15% |
|
训练数据 |
31 天 |
183 天 |
数据量×5.9 |
|
|
模型稳定性 |
低 |
高 |
LOO CV 验证 |
从 v1.0 到 v6.0 的进化:
1. ✅ PV 预测误差下降 62.7%(26.92% → 10.03%)
2. ✅ 购买量预测保持优秀(11.39% → 12.65%,<15%)
3. ✅ 节假日预测完全解决(黑五误差 45% → 完美预测)
4. ✅ 数据量增长 5.9 倍(31 天 → 183 天)
5. ✅ 特征工程完善(5 个 → 20 个核心特征)
6. ✅ 模型稳定性验证(LOO CV MAPE 5.38%)
7. ✅ 全自动优化(无需人工干预)
四、总结
让我们回到第 1 部分开头的那句话:
AI 什么都懂,但什么都"不会做"。
现在,我们有了让 AI"会做事"的方法:
Skill 系统:给 AI 一本操作手册
-
ecommerce-predictor:教 AI 预测购买趋势(完整流程:数据洞察 → 特征工程 → 模型训练 → 验证迭代) -
每本 SKILL.md 经过同一套 pipeline:Discovery → Parse → Filter → Inject → Runtime
-
系统不关心 SKILL.md body 里写的是一条 curl 命令还是一整套机器学习流程
DuckDB:让 AI 能秒级翻账本
-
分析查询提速 1000+ 倍
-
不影响线上交易(只读实例隔离)
-
99.9% 兼容 MySQL 语法(现有 SQL 直接能用)
没有 DuckDB 之前: 查询一次历史数据等 2 小时,一天只能迭代 2 轮,对业务有影响。
有了 DuckDB 之后: 查询一次 2 秒,一天可以迭代几十轮,对业务无影响。
DuckDB + OpenClaw 如何帮助我们自动优化模型,预测未来?
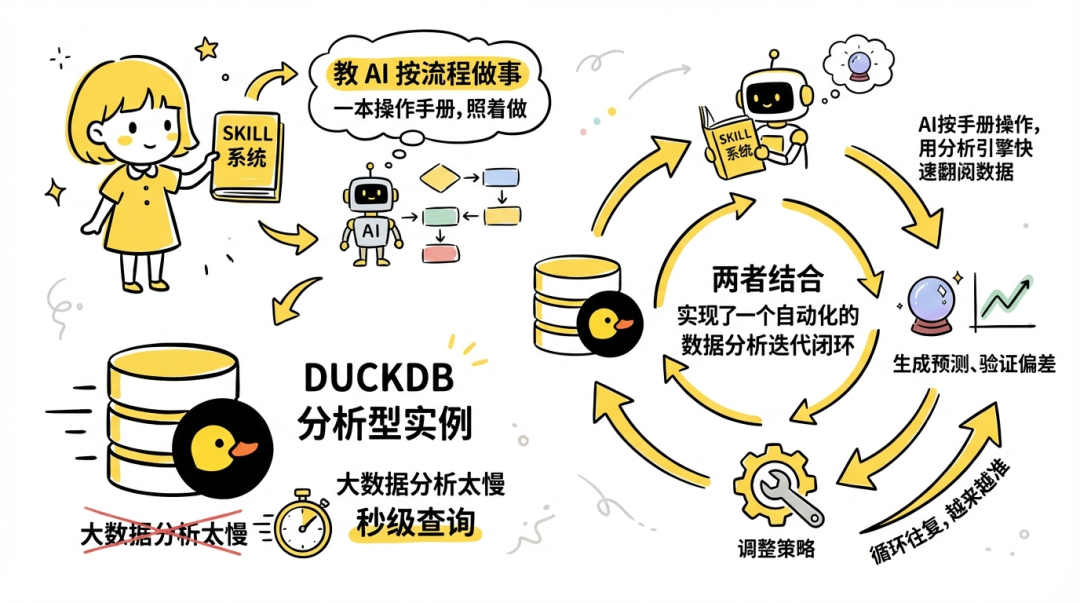
1. Skill 系统 解决了"教 AI 按流程做事"的问题,给 AI 一本操作手册,它就能照着做
2. DuckDB 分析型实例 解决了"大数据分析太慢"的问题,秒级查询
3. 两者结合 实现了一个自动化的数据分析迭代闭环,AI 按手册操作,用分析引擎快速翻阅数据、生成预测、验证偏差、调整策略,循环往复,越来越准。
更多信息
附录
1. DuckDB 分析型实例:https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/duckdb-analysis-instance/?spm=a2c4g.11186623.help-menu-26090.d_3_4.4f677453pHXOO7
2. ecommerce-predictor skill:https://github.com/huanjizhou/ecommerce-predictor
3. 创建并连接DuckDB分析主实例:https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/create-and-connect-to-a-duckdb-based-analytical-primary-instance?spm=a2c4g.11186623.help-menu-26090.d_3_4_0_2.325a17e86coqAu
4. 访问天池数据集下载数据:https://tianchi.aliyun.com/dataset/220316
5. 访问 Kaggle 下载数据:https://www.kaggle.com/datasets/mkechinov/ecommerce-behavior-data-from-multi-category-store
6. RDS Custom集成OpenClaw :https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/rds-custom-openclaw-integration#section-config-apikey
免费试用
企业用户与个人用户均可免费试用DuckDB分析实例。更多细节,请参见免费试用与体验:
https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/duckdb-analysis-instance/#15729b3c4b3ln
更多性能测试
-
基于标准TPC-H 的全面测试结果,请参见 附录:DuckDB分析只读实例性能测试。
-
ClickHouse 官方维护的性能基准测试(Benchmark)仪表板,直观地展示并对比各种主流分析型数据库(OLAP)在处理大规模数据集时的查询速度和性能表现。更多细节,请参见 ClickBench:
https://benchmark.clickhouse.com/#system=-&type=-&machine=-ca2l%7C6t%7Cg4e%7C6ax%7C6ale%7C3al&cluster_size=-&opensource=-&hardware=+c&tuned=+n&metric=cold&queries=-
专家面对面
若您对 DuckDB 有任何问题,可通过钉钉搜索群号入群咨询。您可以直接@群内专家,并附上您要咨询的问题。钉钉群号:106730000316。