Li Auto 团队提出 HVO 框架,无需 SFT,7B 模型文本摘要性能媲美 GPT-4,在维度平衡性和简洁性上表现突出。
原文标题:多目标强化学习新突破!给GRPO加上运筹外挂,7B模型硬刚GPT-4
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到 HVO 解决了 GRPO 训练中常见的“长度坍缩”问题,具体什么是“长度坍缩”?HVO 是如何通过引入长度约束奖励来解决这个问题的?
3、HVO 在 CNN/DailyMail 和 BillSum 数据集上都取得了不错的成绩,那么 HVO 是否可以应用到其他类型的文本摘要任务中,例如会议纪要、法律文书等?在不同的应用场景下,HVO 可能需要进行哪些调整?
原文内容

来源:PaperWeekly本文约1500字,建议阅读5分钟
本文介绍了理想团队 HVO 框架,弃用 SFT,摘要性能媲美 GPT-4。
弃用 SFT!Li Auto 团队发布多目标强化学习新框架,文本摘要直接媲美GPT-4。
弃用 SFT!Li Auto 团队发布多目标强化学习新框架,文本摘要直接媲美GPT-4。
文本摘要作为自然语言处理(NLP)的核心任务,其质量评估通常需要兼顾一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)等多个维度。
然而,在实际优化过程中,开发者往往面临"拆东墙补西墙"的窘境:提升了相关性,一致性可能随之下降。
如何让模型在多个目标之间达成完美的"帕累托最优"(Pareto optimal)?
近日,Li Auto 团队一项被 ICASSP 2025 接收的研究提出了 HyperVolume Optimization (HVO)。
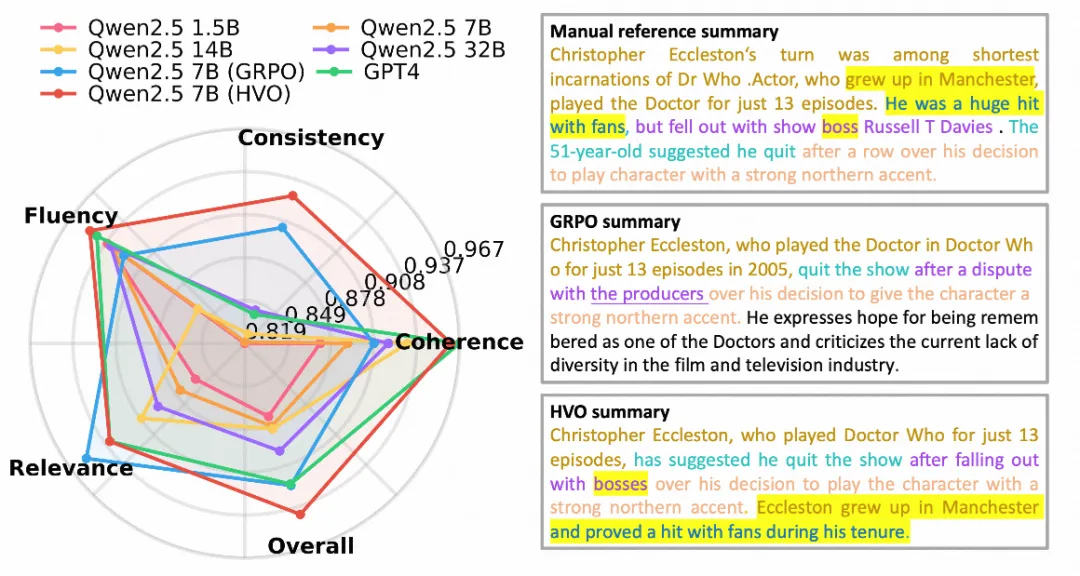
〓 图1. HVO 性能对比雷达图
这是一种全新的多目标强化学习(MORL)策略,它基于 GRPO 框架,无需 SFT 或冷启动,就能让 7B 参数的模型在摘要任务上展现出媲美 GPT-4 的性能,且生成内容更加简洁。

论文标题:
Hypervolume Optimization via Multi-Objective Reinforcement Learning for Balanced Text Summarization
论文链接:
https://arxiv.org/abs/2510.19325
代码链接:
https://github.com/ai4business-LiAuto/HVO
1、研究背景
核心痛点:多目标优化的"不平衡"
文本摘要生成是自然语言处理(NLP)中的一项核心且具有挑战性的任务。为了全面评估生成摘要的质量,研究人员通常会考察多个维度,例如连贯性、一致性、流畅性和相关性。
然而,同时优化这些维度的目标具有挑战性,因为在一个维度上的改进可能会导致其他维度的妥协,从而产生不平衡的摘要。
目前的文本摘要研究多依赖单一奖励信号,难以整合多维度指标。即便采用多维度奖励,通常也只是简单地将各项得分进行加权线性组合(Weighted Linear Combination)。
传统方法的局限性
这种传统做法存在明显局限:
1. 人工依赖:需要繁琐的手动配置权重。
2. 目标冲突:无法有效处理目标间的相互依赖,容易导致优化结果不完整或严重失衡。
此前虽有 MDO 等方法尝试通过梯度投影缓解冲突,但因计算成本过高,难以集成到大语言模型(LLM)中。
2、方法介绍
创新方案:引入超体积指标 HVO
为了解决上述问题,研究者将多目标优化中的超体积(Hypervolume)概念引入到了强化学习的奖励结构中。
基于 GRPO 框架
借鉴了类似 DeepSeek-R1-Zero 的训练范式,HVO 直接在基础模型上应用组相对策略优化(GRPO),无需经过监督微调(SFT)。
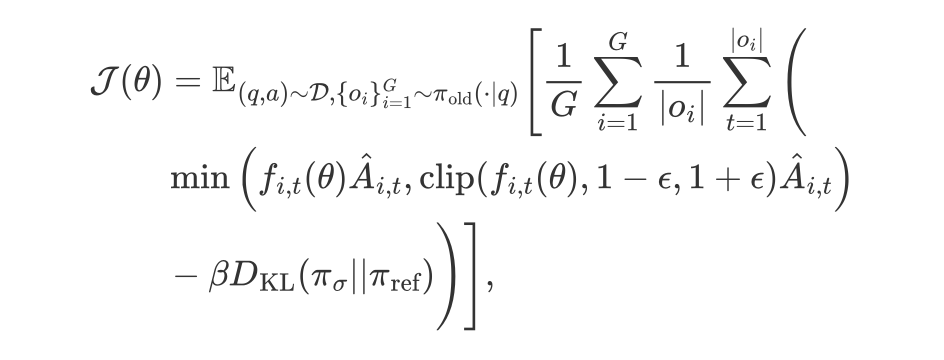
其中:
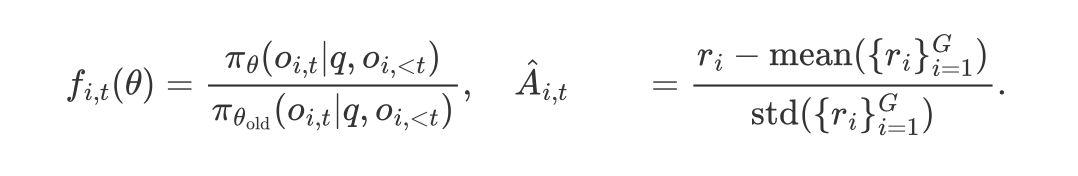
动态调整得分
HVO 利用超体积方法,在强化学习过程中动态调整不同得分组之间的权重,引导模型逐步逼近帕累托前沿。
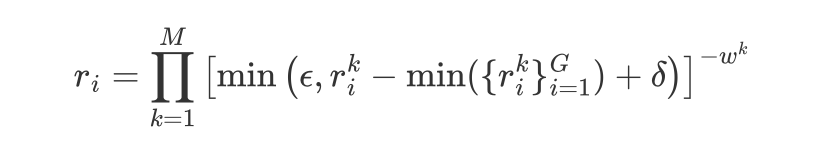
长度约束机制
为解决 GRPO 训练中常见的稳定性不足和"长度坍缩"问题,HVO 提出了一种新的长度约束奖励( ),通过控制压缩比确保模型在简洁的同时保持稳定收敛。
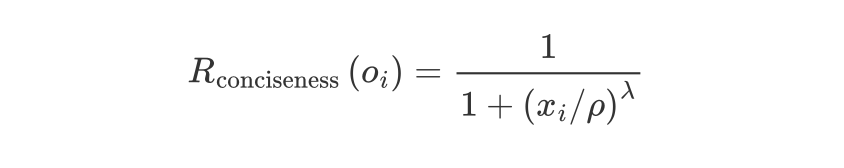
整体流程示意图:
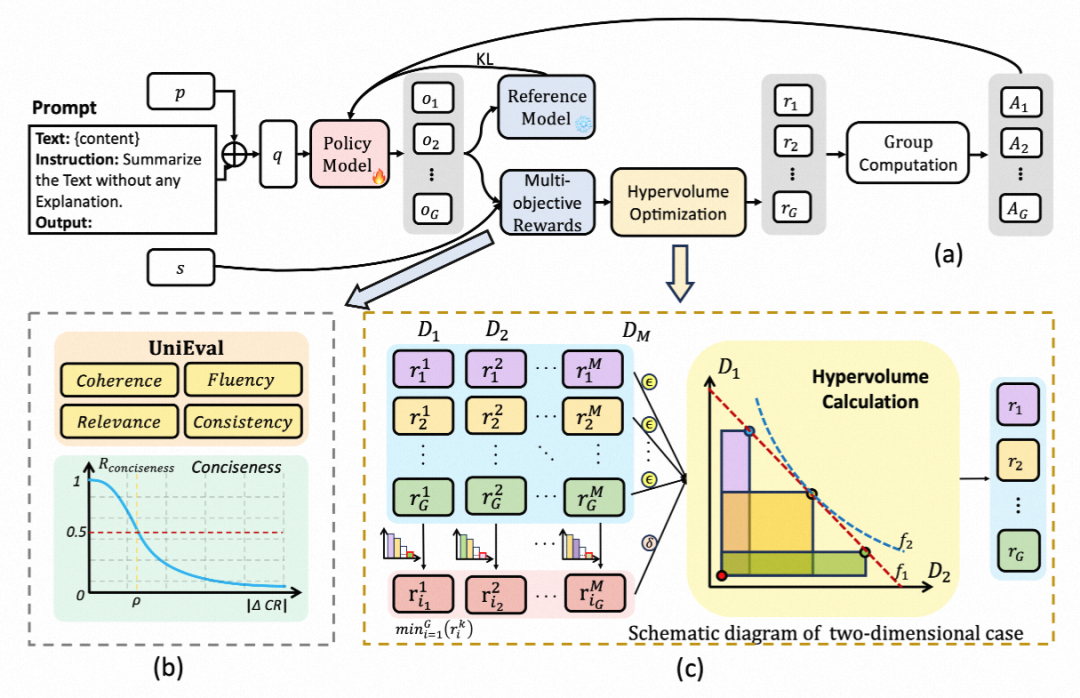
〓 图2. HVO 整体流程示意图。通过超体积计算替代简单的加权求和,使模型倾向于选择各维度表现更均衡的解。
3、实验结果:7B 模型的"降维打击"
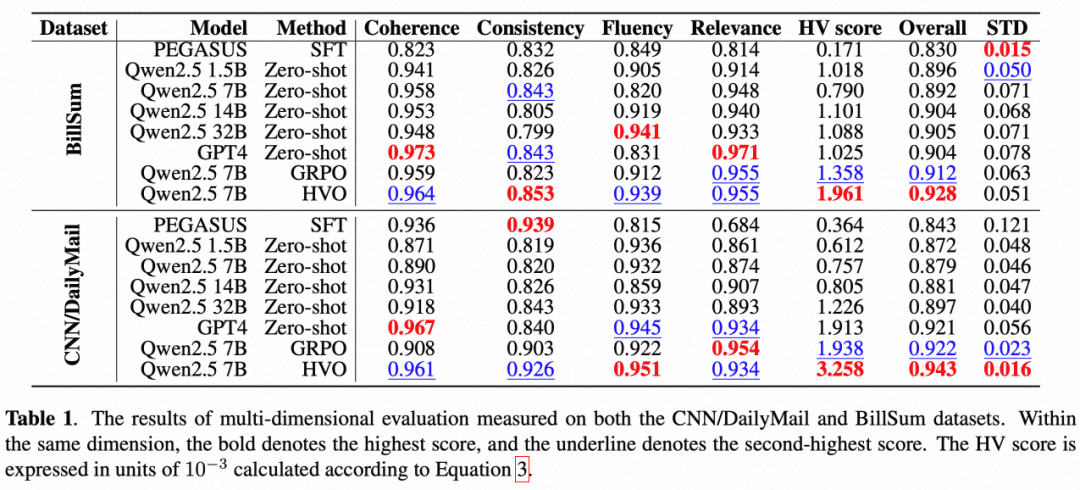
研究团队在 CNN/DailyMail(新闻类)和 BillSum(法律类)两大基准数据集上对 HVO 进行了验证。实验基座采用 Qwen 2.5-7B-Instruct。
综合素质超越 GPT-4
在多维度评估工具 UniEval 的测试中,经过 HVO 增强的 7B 模型表现惊人:
✅ 在两个数据集上的 HV 得分和总分均优于所有基准方法;
✅ 对比 GPT-4:虽然 GPT-4 在连贯性和相关性上有微弱优势,但 Qwen 2.5 7B (HVO) 在整体性能和维度平衡性上与 GPT-4 旗鼓相当。
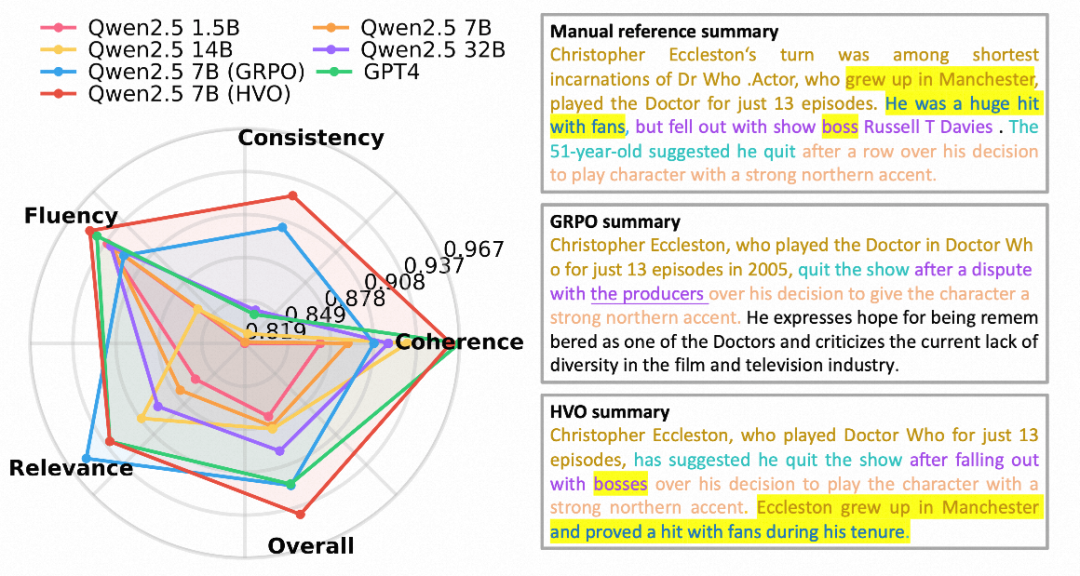
更均衡的雷达图表现
对比 GRPO 发现,GRPO 在训练早期会过度追求流畅性和相关性,从而限制了一致性的提升。而 HVO 能够均匀地优化各项指标,在雷达图上展现出更饱满、更稳定的覆盖区域。
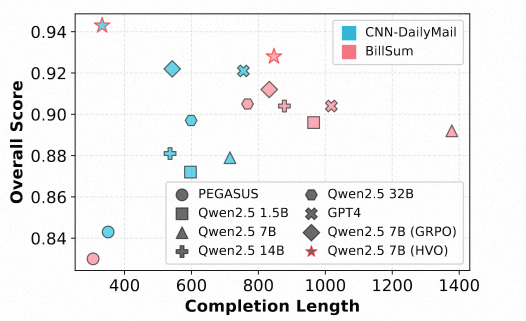
拒绝"废话",更加简洁
散点图分析显示,HVO 在保持最高总分的同时,生成的摘要长度更短,展现了极佳的简洁性(Conciseness)。
4、结语
本文介绍了超体积优化强化学习方法(HVO),这是一种用于文本摘要的多目标强化学习框架,可在高维目标空间中直接优化超体积指标。
通过平衡多个评估指标,HVO 实现了更稳定、更高效地向帕累托前沿逼近的轨迹。
在 CNN/DailyMail 和 BillSum 上的实验表明,HVO 取得了最先进的超体积和整体分数,优于现有方法,且可与 GPT-4 相媲美,无需监督微调或冷启动初始化。
这些结果证实了 HVO 在处理复杂权衡和生成高质量摘要方面的有效性,为多目标文本摘要提供了一个稳健的解决方案。它证明了通过科学的优化策略,较小规模的开源模型完全有潜力在特定任务上对标顶尖闭源大模型。
研究团队表示,未来将探索:
