研究对比学习在不平衡数据下的训练动态,提出剪枝算法提升模型性能和解决类别不平衡问题。
原文标题:不平衡数据下对比学习的理论分析:从训练动态到剪枝解决方案
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到对比学习在神经元专门学习单一特征时效果最佳,数据不平衡会带来三个相互关联的消极影响。如果我想衡量我的模型是否出现了这三个问题,有没有什么可以量化的指标或方法?
3、文章提出的剪枝方法是在前向传播过程中动态移除幅值较小的神经元权重,反向传播过程中仍保留所有参数为可训练状态。为什么不直接永久性删除这些神经元?这样做有什么考虑?
原文内容

本文第一作者廖海旭为新泽西理工学院数据科学系在读博士生,师从Prof. Shuai Zhang。

-
论文标题:Theoretical Analysis of Contrastive Learning under Imbalanced Data: From Training Dynamics to a Pruning Solution
-
论文链接:https://openreview.net/forum?id=DUXG9E8dEO
一、研究背景
对比学习已成为表征学习中的一种强大范式,能够在不依赖标签的情况下有效利用无标注数据。
在这一框架下,语义相似的样本被视为正样本对,而语义不同的样本被视为负样本对。通过在表征空间中拉近正样本对、拉远负样本对之间的距离,对比学习使得模型能够捕捉到丰富且具有判别性的特征。
该方法在广泛的应用领域中取得了显著成功,尤其在多模态学习中影响深远,推动了早期视觉语言模型发展的重大进展。
尽管对比学习具有诸多优势,但它在现实数据集中常见的类别不平衡的问题下,仍然面临挑战。在这类数据中,多数类主导了样本对的构造,而少数类则代表性不足。这种不平衡会阻碍模型对少数类判别性特征的捕捉,降低表征质量,并导致模型产生偏差行为。
近期的研究开始逐步从理论角度理解对比学习,主要关注其相较于传统生成式方法的优势、数据增强在有效表征学习中的必要性,以及其在降低下游任务样本复杂度方面的能力。然而,这些研究尚未考虑数据分布不平衡所带来的影响,缺乏对这些影响的理论刻画。
总体而言,本文在理论和实践层面都提供了新的洞见,主要理论结论也通过数值实验得到了验证。主要贡献如下:
第一,我们构建了一个理论框架,用以刻画在数据分布不平衡条件下、基于 Transformer 编码器的对比学习训练动态。我们表明学习过程可以分为三个阶段。
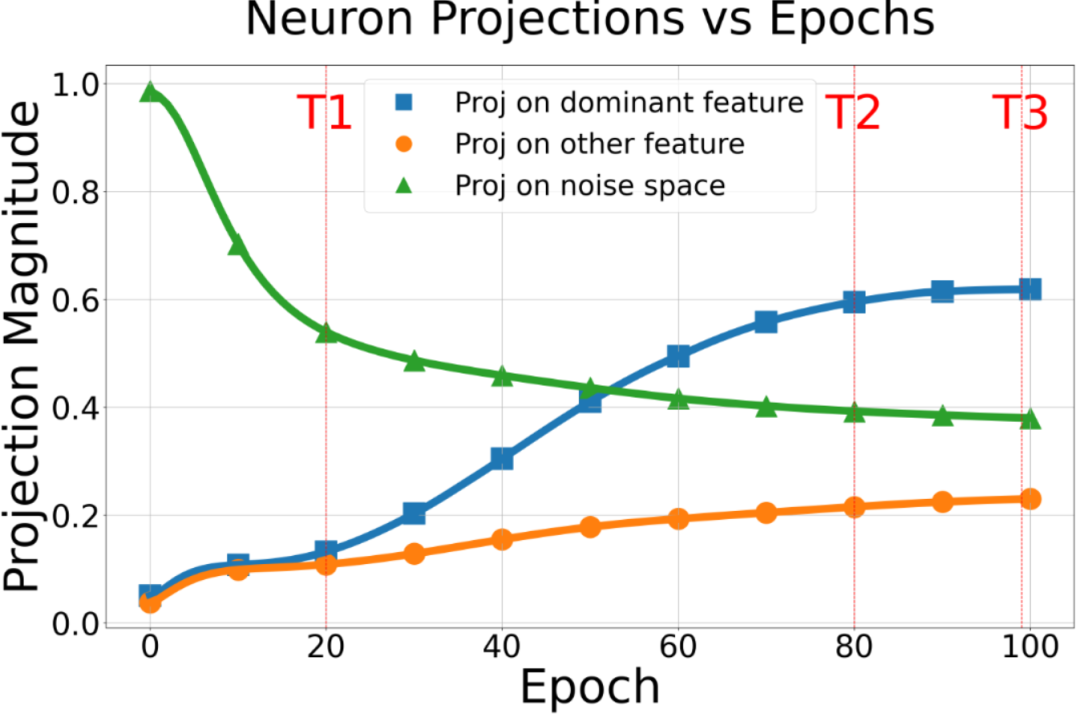
图 1:神经元在训练过程中投影的动态变化。蓝色曲线表示神经元在其主导特征方向上的投影增长情况,橙色曲线表示其在非主导特征方向上的投影,绿色曲线表示其在噪声空间方向上的投影。在第一阶段,神经元主要沿特征方向增长,同时抑制噪声分量。在第二阶段,其在主导特征方向上的投影增长速度快于所有其他特征方向,从而形成明显的分离。在第三阶段,神经元逐渐收敛,其最终表示由所学习的主导特征所主导
第二,我们定量刻画了少数特征的存在如何影响神经元的学习能力,进而影响整体表征学习。我们的分析表明不平衡会从多个方面削弱表征性能。
第三,基于幅值的剪枝能够增强对少数特征的学习,恢复因数据不平衡而退化的性能。我们的结果显示,剪枝可以加强沿少数特征方向的梯度更新,鼓励更多神经元专门学习少数特征,从而获得更加稳健且更均衡的表示。
二、剪枝算法
为了解决数据不平衡问题,我们在前向传播过程中动态移除幅值较小的神经元权重,而在反向传播过程中仍保留所有参数为可训练状态。
具体而言,二值掩码初始设为全 1,表示训练开始时不进行任何剪枝。在每一个训练周期中,我们剪除幅值最小的一部分神经元,并相应更新二值掩码。在前向传播阶段,使用掩码后的参数对输入进行编码。在反向传播阶段,梯度是基于剪枝后的模型计算,但更新作用于完整的参数集合。
需要注意的是,该过程并不会为了提高效率而永久性地删除任何神经元,尽管可以观察到一定程度的计算成本下降。
三、关键发现的核心洞见
在介绍正式理论结果之前,我们首先总结分析所得的关键洞见。我们的研究表明,神经元在训练过程中会分阶段逐步学习特征表示。具体而言,我们得到以下结论:
(K1) 基于 Transformer-MLP 框架的对比学习训练动态。我们的理论将学习过程划分为三个阶段。
-
在第一阶段中,神经元权重沿特征方向增长,增长速率由特征频率决定,神经元在非特征方向上的分量则被抑制。
-
在第二阶段中,幸运神经元进一步和它学习的主导特征方向对齐;而普通神经元则被这些幸运神经元所界定并保持受控,从而使所学习的特征更加纯净,同时非特征分量继续受到抑制。
-
在最终阶段,训练收敛,每个神经元都会与某一特定特征集合对齐,每个神经元在一个或多个特征方向上强对齐,在其他特征方向上弱对齐,并在非特征方向上保持较小幅度。
(K2) 特征频率比率决定神经元专门化程度。在收敛时,每个神经元主要由某一特定特征集合中的特征主导,而来自其他方向的贡献可以忽略。
-
首先,越稀有的特征学习得越弱。
-
其次,该特征集合的大小由特征频率比率决定:较小的特征频率比会扩大该集合,导致特征混合;较大的特征频率比则会缩小该集合,使神经元学习到的特征更加纯净,这对于对比学习而言是更好的。
-
最后,专门学习单一特征的神经元数量与也由特征频率比率决定,并且随着特征频率比的增大而减少。
由于对比学习在神经元专门学习单一特征时效果最佳,数据不平衡会带来三个相互关联的消极影响:
-
少数特征以较小幅度被学习。
-
神经元倾向于学习混合的多个特征而非保持与单个特征对齐。
-
专门学习单一特征的神经元的总数减少。
这些因素共同削弱了表征质量,并要求更大的模型规模才能学习所有特征。
(K3) 剪枝增强少数特征的学习。
-
学习少数特征的神经元会获得更强更新;而学习非少数特征的神经元仅获得的更新较弱。
-
在收敛时,学习少数特征的神经元的系数可以达到与多数特征同阶的规模,从而缓解由数据不平衡带来的性能下降。
直观来看,由于少数特征神经元的幅值较小,它们更容易被剪枝;这种机制在梯度更新中放大了包含少数特征样本的贡献。因此,剪枝强化了少数特征,使其与其他成分明显区分开来,并推动更多神经元专门化学习该特征,从而提升表示学习的鲁棒性。
四、理论结果
理论分析结果的完整内容请参考文章,此处我们给出精简的概括。
理论一:在第一阶段的训练中:
-
所有神经元都会沿着特征方向增长,而非特征方向则被忽略。
-
在每个特征方向上的增长速率取决于该特征的出现频率。
理论二:在第二阶段的训练中:
-
幸运神经元:与单一特征强烈对齐。
-
普通神经元:其在特征上的分量受幸运神经元的约束。
理论三:当学习收敛时,在没有剪枝的情况下,对比学习中神经元和特征的对齐情况如下:
-
每个神经元都会与一个或多个特征强对齐,与其他特征弱对齐,并在非特征方向上保持较小幅度。
-
每个神经元倾向于学习多个特征的混合表示,将学习更大规模的混合特征集合。
-
专注于学习单一特征的神经元数量更少,对于每个特征,至少有
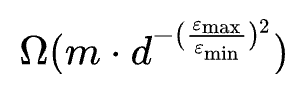 个神经元专门学习该特征。
个神经元专门学习该特征。
理论四:在引入剪枝的情况下,对比学习中神经元和特征的对齐情况如下:
-
沿少数特征方向的神经元更新得到增强。少数特征对应的神经元权重增长更快。非少数特征对应的神经元权重增长缓慢。
-
更多神经元专注于学习少数特征。对于每个特征,至少有
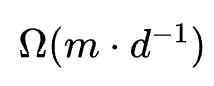 个神经元专门学习该特征。
个神经元专门学习该特征。
五、实验结果
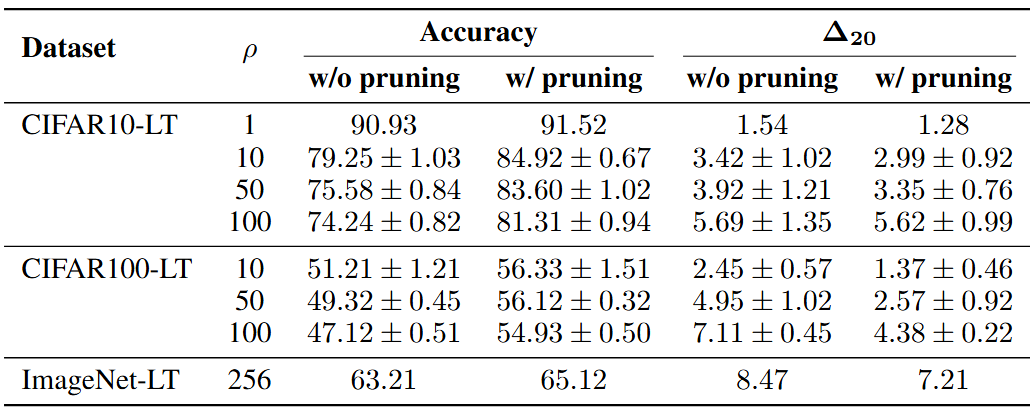
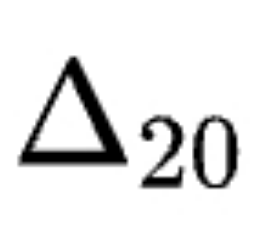
表 1 展示了在长尾分布设置下,对 CIFAR10-LT、CIFAR100-LT 和 ImageNet-LT 进行线性探测评估,对比了不使用剪枝与使用剪枝的结果。不平衡比例![]() 定义为多数类与少数类样本数量之比,数值越大表示不平衡程度越严重。
定义为多数类与少数类样本数量之比,数值越大表示不平衡程度越严重。
实验结果表明,剪枝在所有数据集上均持续提升准确率,并且随着不平衡程度加剧,性能提升更加显著。此外,剪枝也改善了头部类别与尾部类别之间的性能不平衡。这些结果表明,剪枝不仅提升了下游任务的整体性能,同时也缩小了头部类别与尾部类别之间的性能差距。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com