滑铁卢大学&可灵联合提出UniVideo,统一视频理解、生成与编辑,无需特定设计即可泛化,性能优异,代码已开源。
原文标题:ICLR 2026|滑铁卢大学联合可灵提出UniVideo:统一视频理解、生成、编辑多模态
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、UniVideo 宣称可以泛化到未见过的视频编辑指令和新的任务组合。这种泛化能力是如何实现的?除了文中提到的联合多任务训练和统一多模态框架,是否还有其他关键因素?
3、UniVideo 在视频编辑方面表现出色,那么,你认为它在哪些领域具有潜在的应用价值?例如,在影视制作、教育、电商等领域,它可能带来哪些变革?
原文内容

来源:机器之心本文约2000字,建议阅读5分钟实验结果表明,UniVideo 在多项定量评测中优于任务特定的单任务方法,并在多数设置下达到或超过当前最优水平。
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。
滑铁卢大学与快手可灵团队提出 UniVideo,一个在统一框架下同时支持视频理解、生成与编辑的多模态生成模型。
UniVideo 采用双流架构,将多模态大语言模型(MLLM)的指令理解与推理能力,与多模态扩散 Transformer(MM-DiT)的高质量视觉生成能力相结合。不同于以往依赖任务特定设计或受限于单一模态的方法,UniVideo 能够理解多模态指令、区分不同任务类型,并在多项基准上取得接近或超过现有最优方法(SoTA)的性能。
更重要的是,UniVideo 无需额外的任务特定设计,即可泛化到未见过的任务及新的任务组合。这意味着,视频生成与编辑不必再被拆分为多个孤立模型,统一建模本身就带来了更强的扩展性。
目前,该工作已被 ICLR 2026 接收,代码已开源。

-
项目主页:https://congwei1230.github.io/UniVideo/
-
论文地址:https://arxiv.org/abs/2510.08377
-
开源代码:https://github.com/KlingTeam/UniVideo
-
开源模型:https://huggingface.co/KwaiVGI/UniVideo
效果展示

模型架构
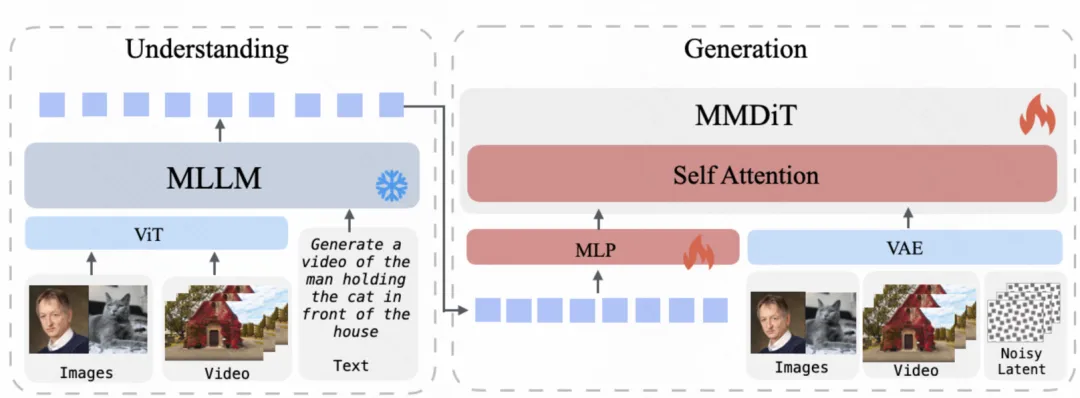
UniVideo 由两个核心组件组成:多模态大语言模型(MLLM) 和 多模态扩散 Transformer(MM-DiT)。
-
MLLM 负责多模态指令理解与语义推理,能够接受文本、图像和视频输入,并生成高层语义表示或文本响应。
-
MM-DiT 专注于视觉内容生成,在潜空间中进行条件图像 / 视频建模。
UniVideo 从 MLLM 的最后一层隐藏状态中提取多模态语义特征,这些特征编码了丰富的跨模态语义信息。通过可训练的 MLP Connector,将其对齐并注入到 MM-DiT 的理解流(understanding stream)中,用于高层语义条件建模。同时,视觉信号通过 VAE 编码后输入至 MM-DiT 的生成流(generation stream),以保留细粒度的视觉信息。
这种双流设计同时具备强语义基础与高保真视觉重建能力,对于视频编辑以及需要保持身份一致性的上下文生成任务尤为关键。
统一 10 个多模态任务
UniVideo 将多种视频生成与编辑任务统一到单一的多模态指令范式中,并通过 MLLM + MM-DiT 的双流架构实现灵活的任务调度与生成。
-
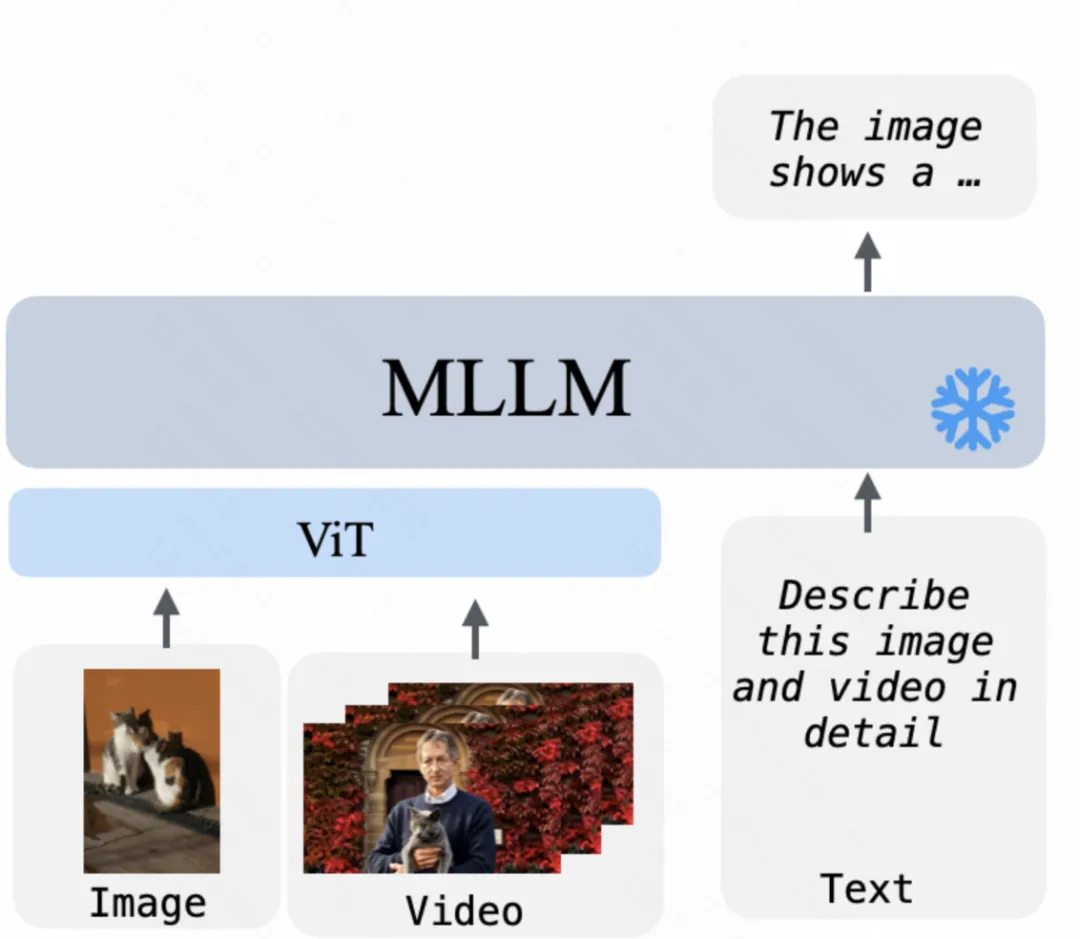
多模态理解(Image / Video → Text,I/V2T)
图像或视频输入由 MLLM 直接处理,并生成对应的文本输出。
-
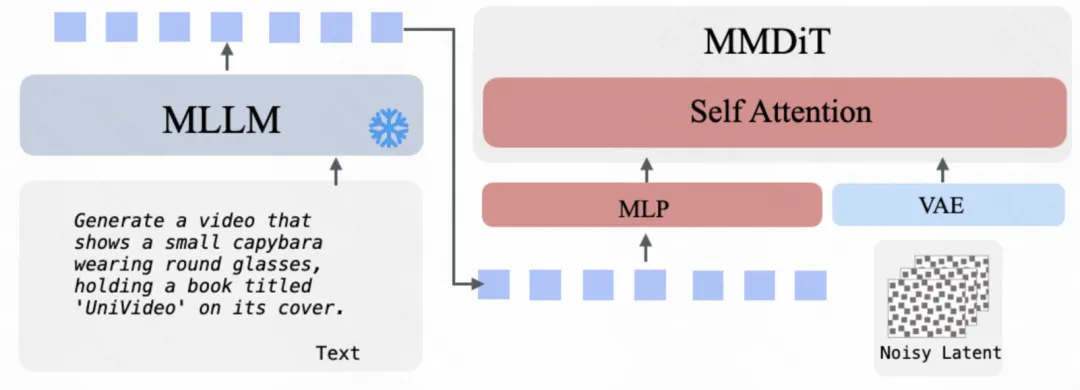
文本到图像 / 视频生成(Text → Image / Video,T2I / T2V)
文本指令由 MLLM 编码为语义表示,并作为条件输入,引导 MM-DiT 生成图像或视频内容。
-
图像到视频生成(Image → Video,I2V)
输入图像与文本指令由 MLLM 联合理解并生成语义条件;同时,图像的视觉信息与视频潜变量一同输入 MM-DiT,以约束并引导视频生成过程。
-
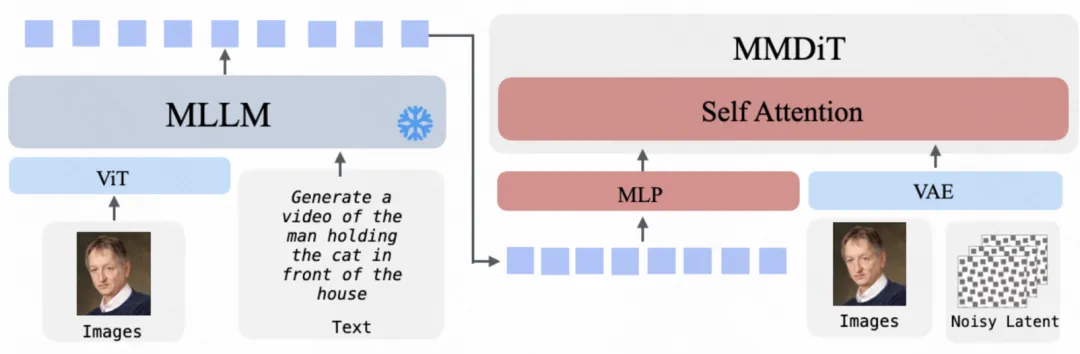
图像 / 视频编辑(Image / Video Editing,I2I / V2V)
输入图像或视频及编辑指令由 MLLM 解析为语义条件,MM-DiT 在保持原始内容结构的基础上完成条件编辑生成
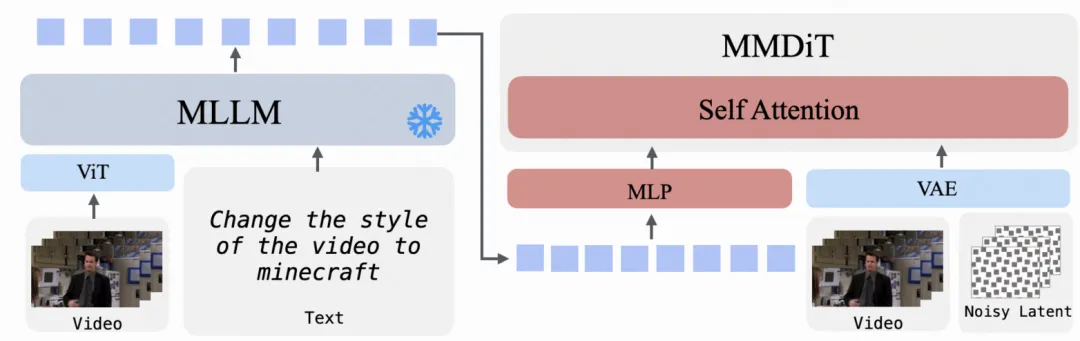
-
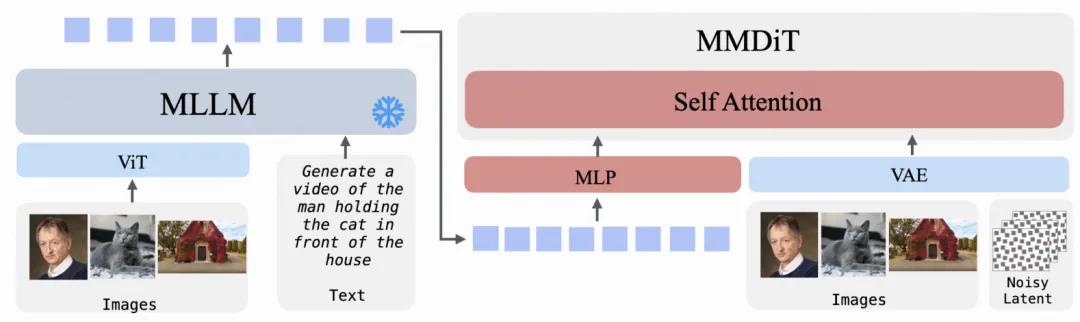
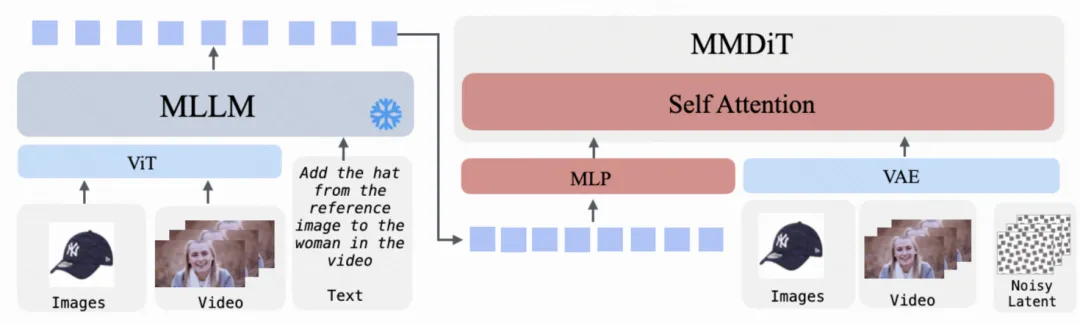
上下文图像 / 视频生成与编辑(Multi-ID2I / Multi-ID2V / ID-I2I / ID-V2V)
在这类任务中,通常存在多个视觉条件(如多张参考图像或参考视频)。所有视觉信号经 VAE 编码后统一填充至相同形状,并沿时间维度拼接,通过自注意力机制进行融合,从而支持 ID 保持和跨上下文生成与编辑。
实验结果
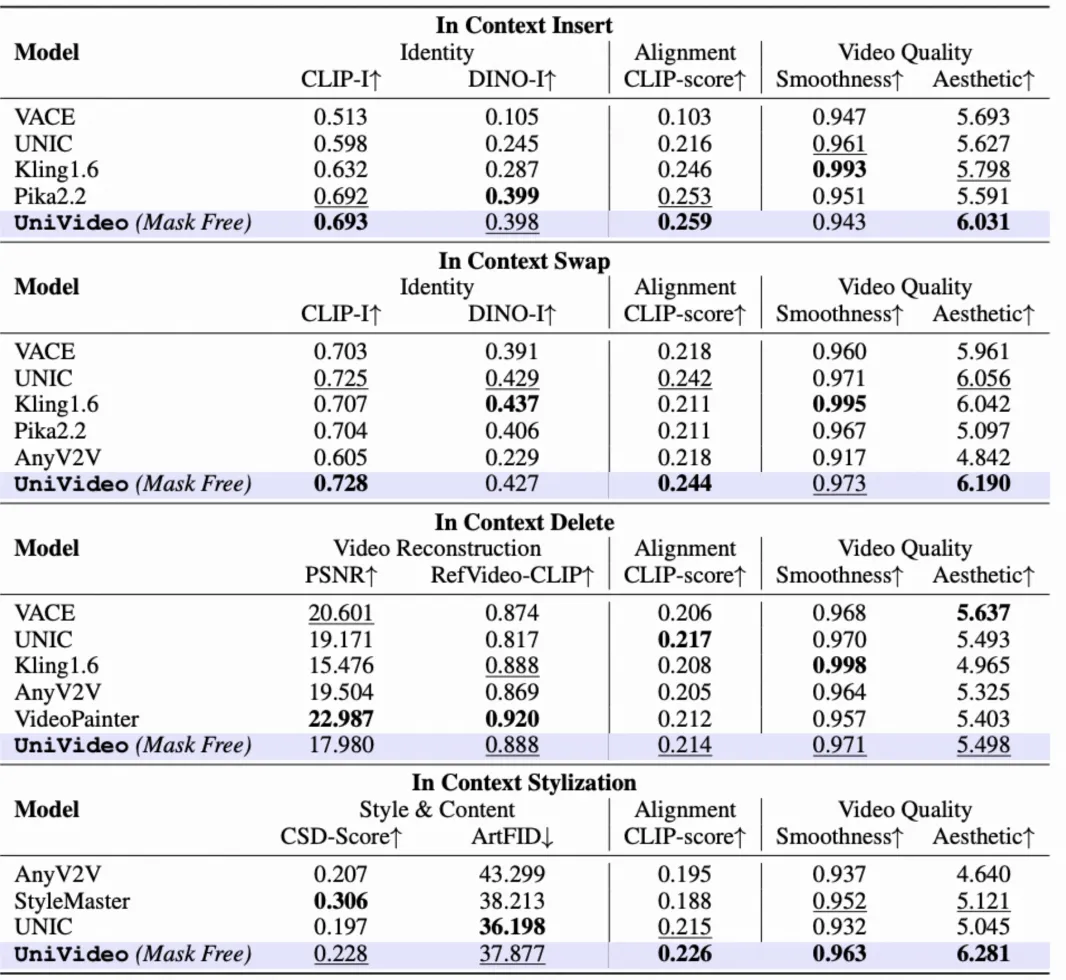
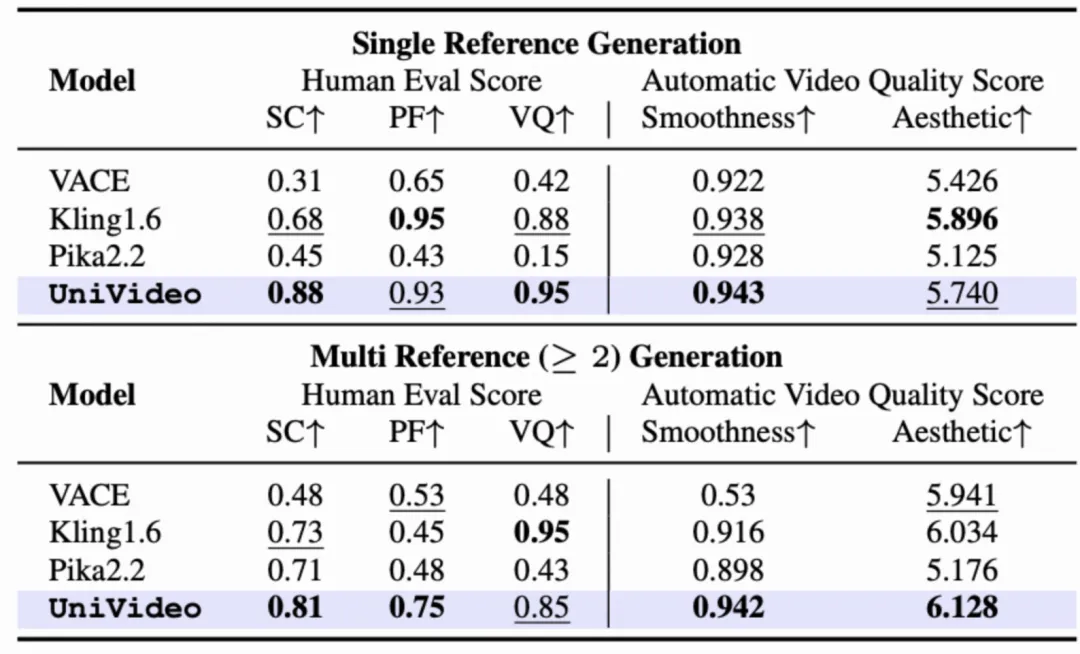
在定量评测中,UniVideo 在各项评测指标上均优于任务特定(task-specific)的基线方法,并在多数实验设置下达到或超过当前最优方法(SoTA)。
下图展示了 UniVideo 在上下文生成与编辑任务上的定量对比结果。
Key Insight:统一模型具备良好的泛化能力
团队从两个方面验证了 UniVideo 统一架构的泛化能力:
(1)对未见视频编辑指令的泛化能力:
尽管 UniVideo 未在 free-form 视频编辑指令数据上进行训练,但通过联合多任务训练,模型成功将图像编辑能力迁移至视频领域,实现了对 free-form 视频编辑指令的泛化。
(2)对新任务组合的泛化能力:
即使在训练阶段未显式包含相关任务组合,UniVideo 仍能够自然泛化到新的任务组合设置,展现出统一多模态框架在组合泛化方面的显著优势。
下图给出了 UniVideo 泛化到视频风格化与环境编辑任务的定性示例:

总结
UniVideo 通过统一的多模态指令范式与双流架构,实现了视频理解、生成与编辑任务的统一建模。实验结果表明,UniVideo 在多项定量评测中优于任务特定的单任务方法,并在多数设置下达到或超过当前最优水平。
更重要的是,UniVideo 可泛化到未见过的视频编辑指令和新的任务组合。这表明,统一多模态建模不仅可行,而且可能是一条更具扩展性的方向。
作者介绍
本文第一作者魏聪,滑铁卢大学博士三年级在读,导师为陈文虎教授。
-
个人主页:https://congwei1230.github.io/
编辑:文婧
