李飞飞团队新作提出“空间智商”测试,揭示大模型在主动探索和认知方面的深层缺陷,为具身智能发展指明方向。
原文标题:李曼玲、李飞飞团队顶会新作:给大模型测「空间智商」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到了“信念漂移”和“信念惯性”这两种现象,你认为它们对AI在实际应用中会产生什么影响?有什么方法可以缓解或避免这些问题?
3、文章最后提到了构建“世界模型”的重要性,你认为一个理想的“世界模型”应该具备哪些特征?它将如何帮助AI更好地理解和适应真实世界?
原文内容

1. 真正的高级智能,在于认知自己的 “无知”
如果把当下最强的大模型(如 GPT-5.2、Gemini-3 Pro)丢进一个从未去过的虚拟房间,让它自己探索并构建地图,它能做到吗?
一直以来,我们评估多模态大模型的标准就像是 “开卷考试”:给一张静态图片,问图里有什么。在这样的标尺下,AI 似乎已经无所不能。然而,在真实的物理世界中,无论是家庭服务机器人还是自动驾驶汽车,面临的都是部分可观测(Partial Observability)的未知环境。
人类在探索未知时,展现出了极高的 “空间智商”:当你发现视野有盲区时,你的大脑会自动预测背后的 “不确定性(Uncertainty)”,并驱使你走上前去一探究竟,从而高效地获取信息(Information Gain)。
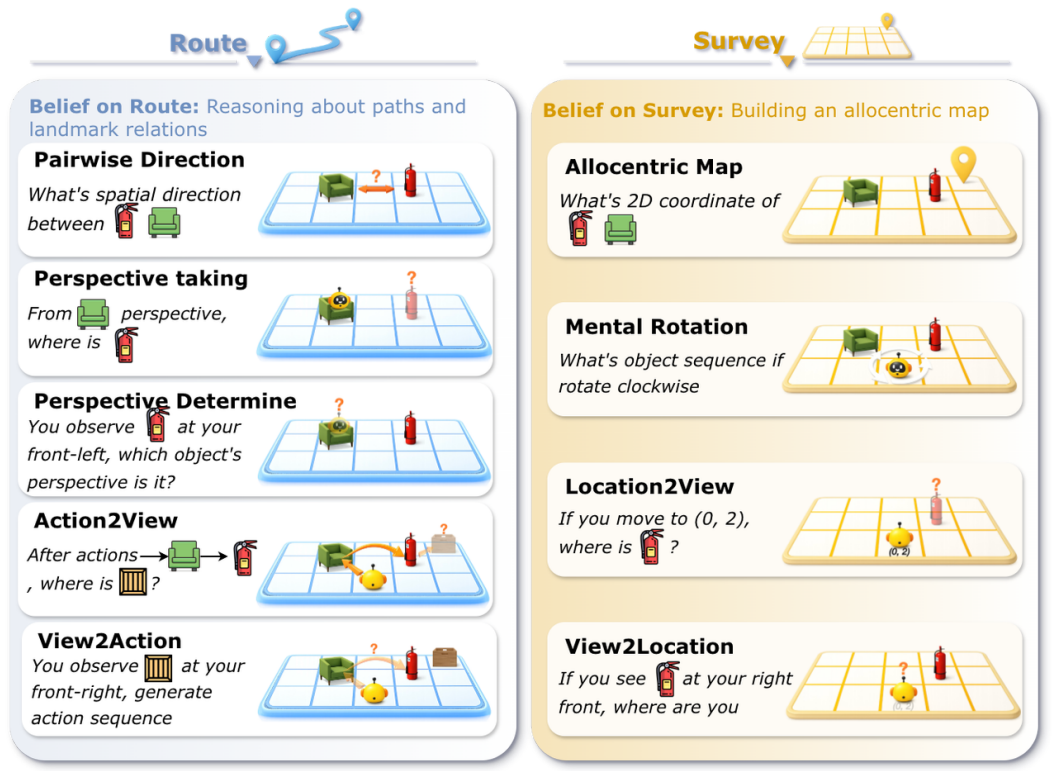
为了探究 AI 是否具备这种人类级别的高阶能力,西北大学李曼玲团队、斯坦福大学李飞飞与吴佳俊团队,以及华盛顿大学 Ranjay Krishna 团队,共同提出了一项针对基础模型的“空间智商测试”—— 空间理论 (Theory of Space)。

Theory of Space:主动探索,信念探测以及任务评估。左侧展示智能体在多房间局部观测下的轨迹俯视图;中间呈现其在文本或视觉环境中的 “移动 - 旋转 - 观测” 闭环,通过第一人称观测实时更新内部信念;右侧则通过空间任务及认知地图探测,对信念的利用与表征进行深度评估。
该研究指出,衡量具身大模型的真正试金石,不在于它能否机械地回答 “看到” 了什么,而在于它能否主动预测并消除环境中的 “不确定性”。这才是通向通用人工智能(AGI)的必经之路。

-
论文标题:Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration?
-
论文链接: https://arxiv.org/abs/2602.07055
-
代码: https://github.com/mll-lab-nu/Theory-of-Space
-
项目主页: https://theory-of-space.github.io/
-
数据集: https://huggingface.co/datasets/MLL-Lab/tos-data
2. 一场史无前例的 “空间 IQ 大考”
为了全方位、无死角地测量大模型的空间智商,研究团队精心打造了一个基于程序的 “多模态平行测试宇宙”。这个宇宙同时包含了象征纯粹逻辑推理的纯文本房间,以及基于 ThreeDWorld 引擎渲染的视觉房间。
模型只被赋予了几项最基础的本能动作:“移动”、“多角度旋转” 和 “就地观察”。它必须像一个真正的勘探者一样,在有限的试错成本下,自主规划探测路径,并判断何时已经获取了足够的信息来终止探索。
为了层层剥开 AI 空间认知的底色,这一测试系统从三大核心维度对其展开了步步紧逼的 “拷问”:
-
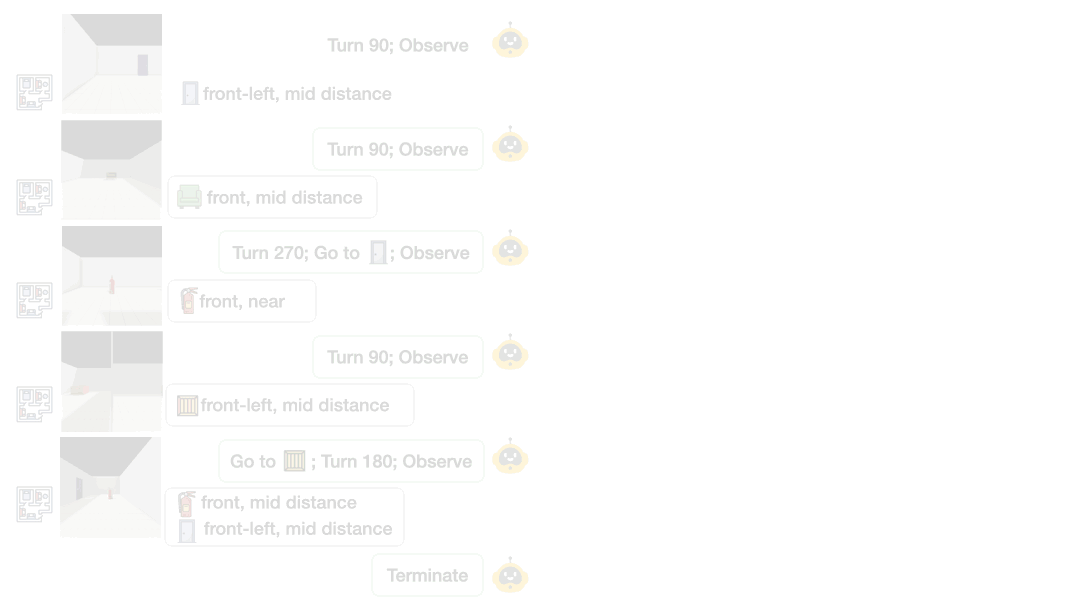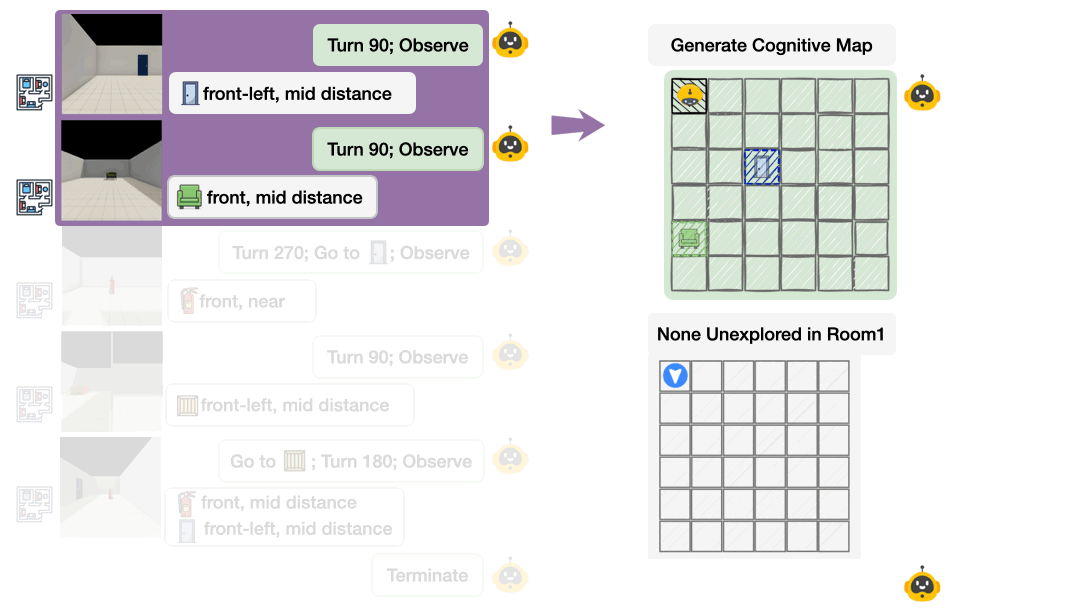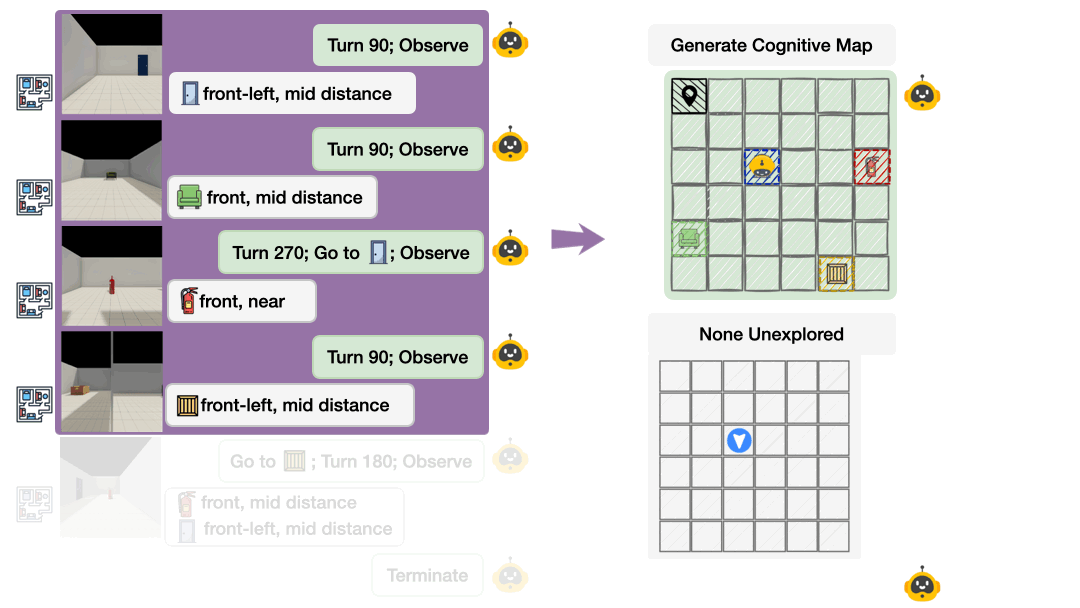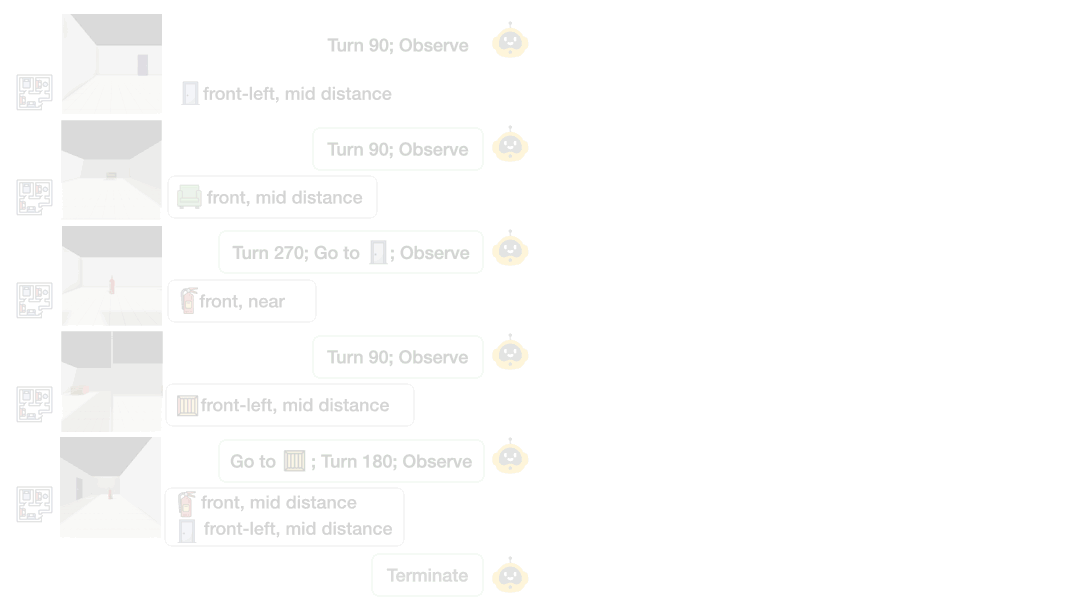
寻找未知(Construct): 面对 “盲人摸象” 般的局部碎片视野和极具挑战的 3D 渲染光影,模型能否克服感知迷雾,主动、高效地搜集信息,在脑海里无缝连结出一张全局的 “认知地图”?
-
敏锐纠错(Revise): 如果视线之外的房间格局被暗中调换(这对动态物理世界再常见不过),模型在重新路过时能否立刻警觉,并果断修改大脑里的旧数据?
-
高阶推演(Exploit): 建好地图不是终点,关键在于能否经受住应用层面的极致考验。研究团队精心设计了 9 大核心空间推理任务,既有考察第一人称代入感的 “路线级推理(Route-level)”(如视角转换、根据连续动作推演最终视野),也有高度抽象的 “全局级推理(Survey-level)”(如挑战脑海里的 360 度动态心智旋转、构建上帝视角的绝对坐标构图)。
任务套件总览图
给大脑做 “X 光透视”:认知地图显式探测
过去的研究往往只能通过动作对错来猜测 AI 的思路。而在 Theory of Space 中,研究团队创造性地引入了 “认知地图显式探测(Cognitive Map Probing)” 机制。
在模型每走一步时,都强制要求它以 JSON 格式默写出脑海中的虚拟地图分布,甚至直接在地图上选出 “尚未探索过的盲区”。这使得 AI 对不确定性的建模过程彻底透明化!
3. 成绩单出炉:面对不确定性,基础模型四大底层缺陷尽显
研究团队将 GPT-5.2, Gemini-3 Pro, Claude-4.5 Sonnet, GLM-4.6V, Qwen3-VL 等主流大模型送入考场。结果令人震撼:当 AI 面临 “自主求解不确定性” 的任务时,看似强大的它们集体迷失,暴露出令人担忧的四大深层病理。
缺陷一:毫无章法的试错陷阱,主动探索得分暴跌
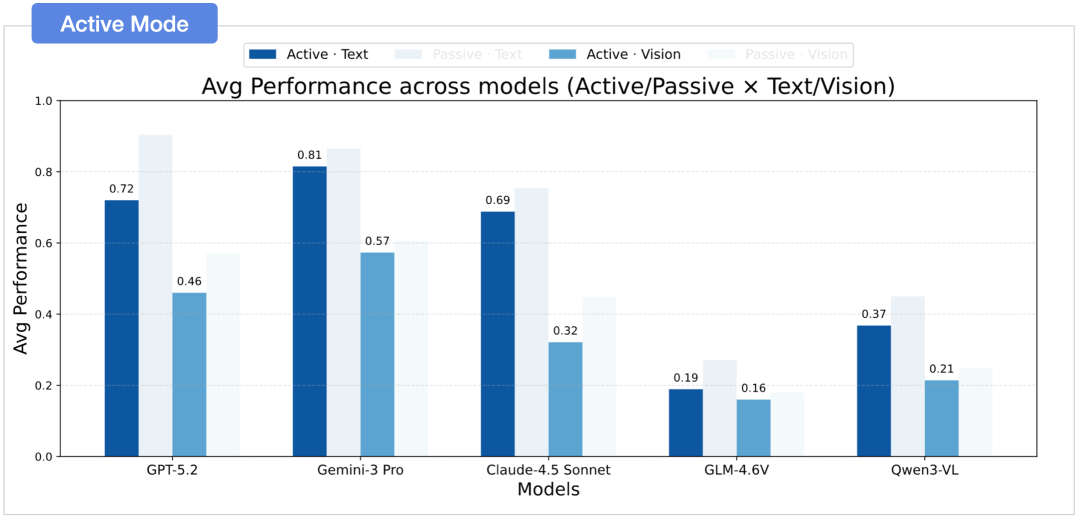
为了设立标尺,研究者先用了一个 “策略脚本代理(Proxy Agent)” 去执行探索,也就是被动探索模式,发现只需平均约 9 步就能完全掌控整个房间结构;而大模型自主行动时,却往往耗费 14 到 20 步以上,并且不停地在已安全观测的区域里打转。
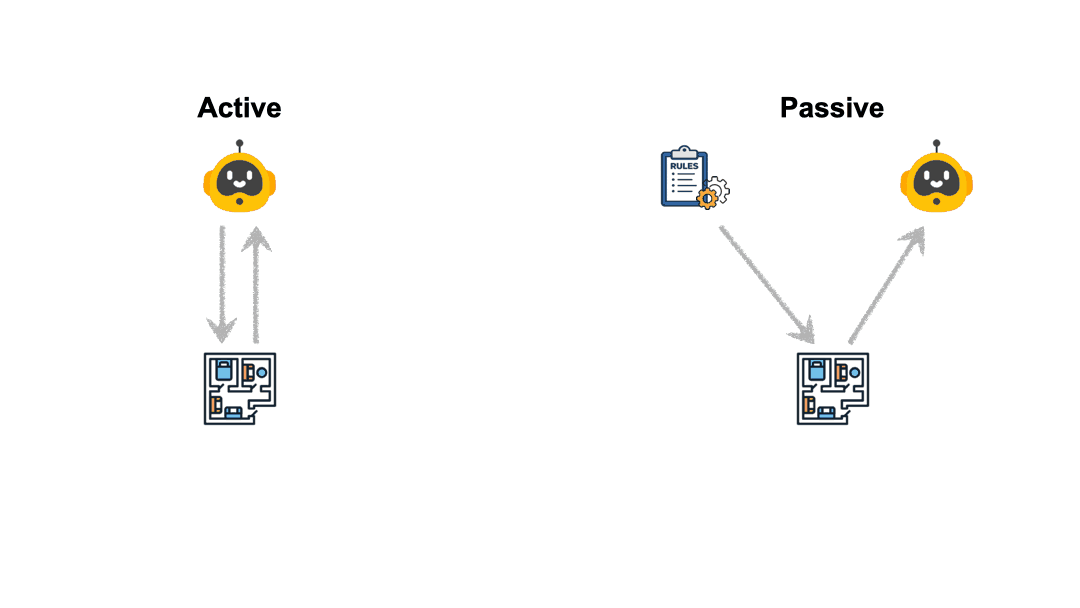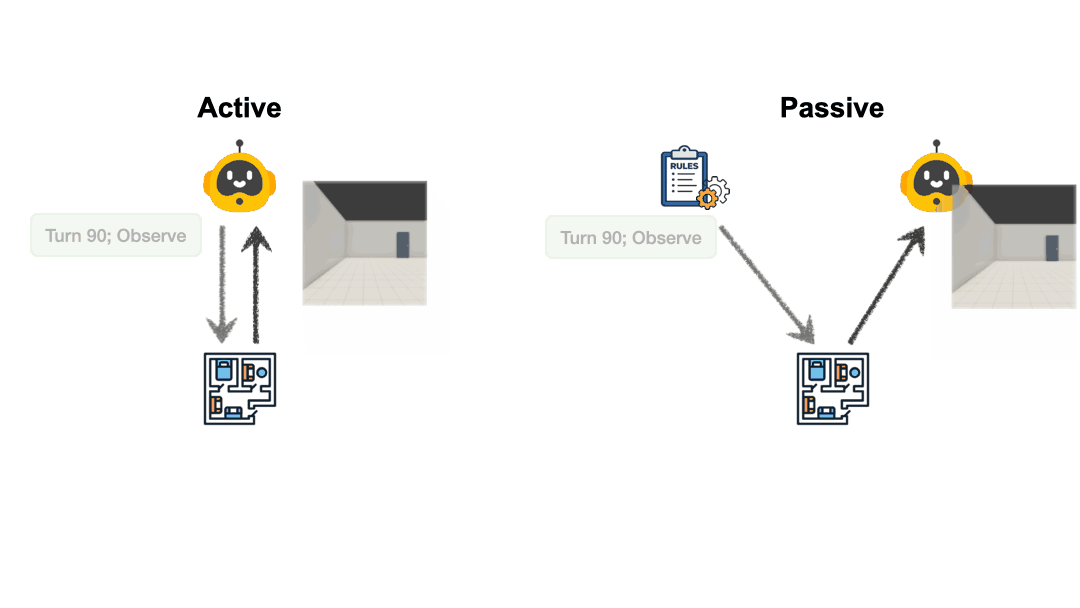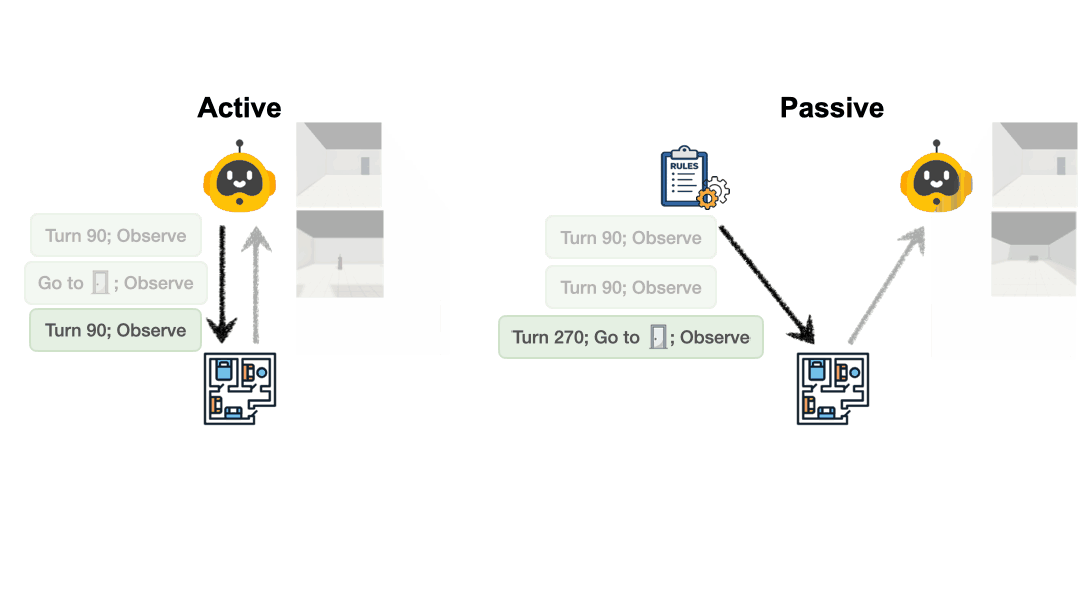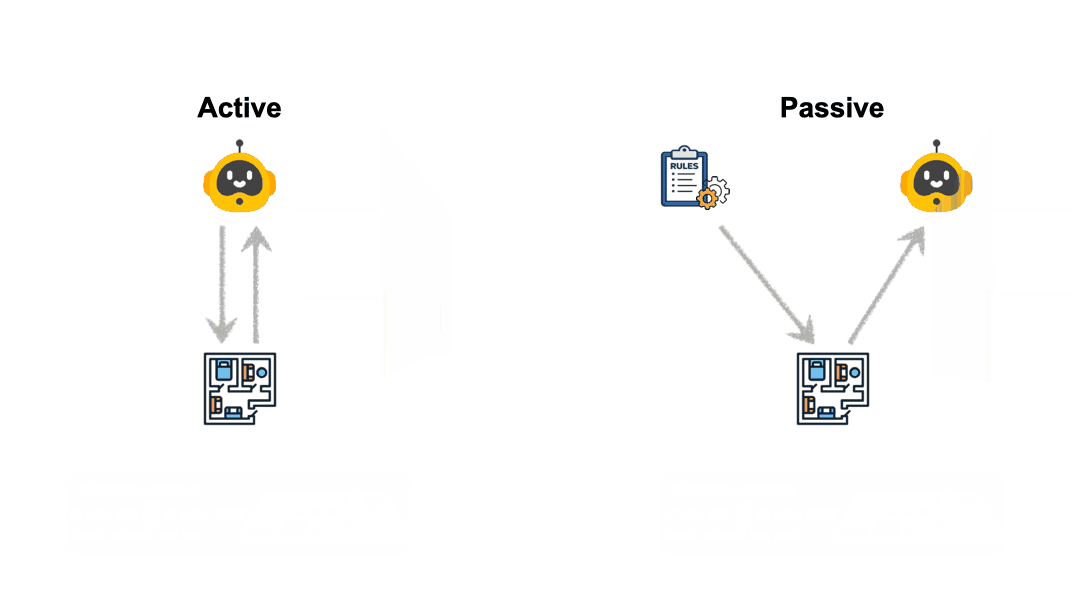
这种 “无头苍蝇” 式的探索,导致最终构建的地图质量严重受损。例如,面对同样的视觉宇宙,GPT-5.2 的动作准确率从被动接收信息的 57.1% 大幅下滑至主动探索的仅 46.0%。
症结在于:大模型无法形成一种高效、有条理的探索策略,并且不能很好地感知自身知识的边界,无法非常有效地标出哪些区域是未知的。
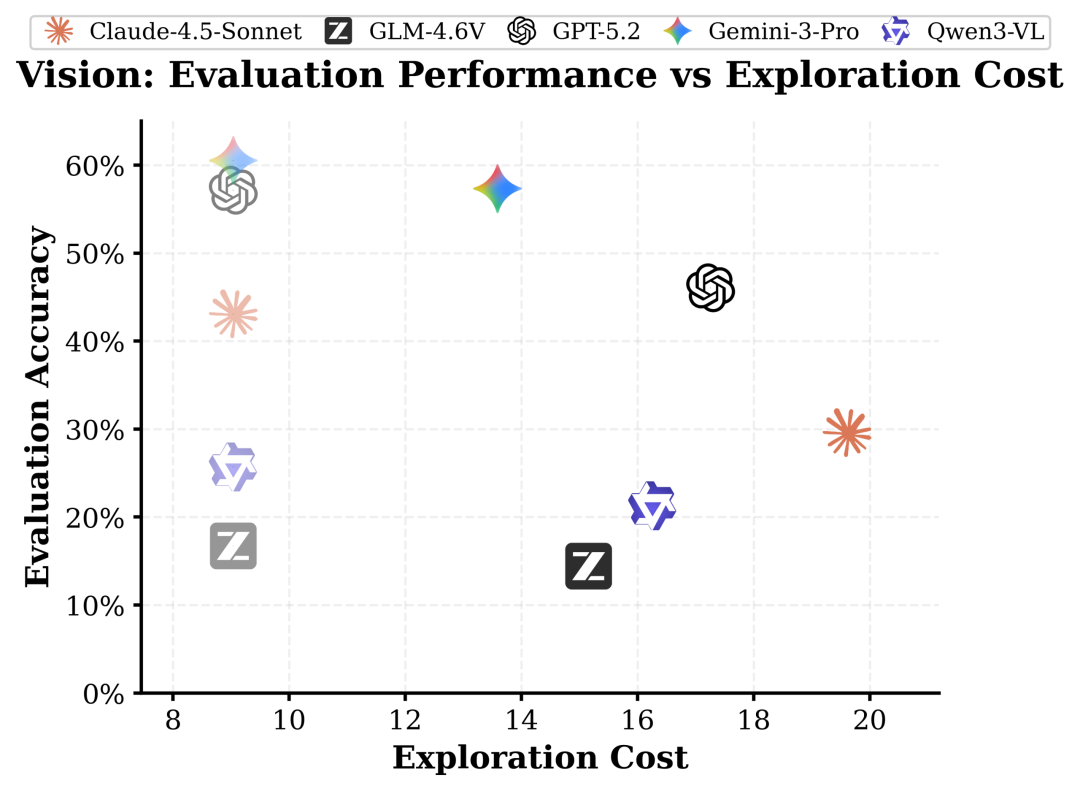
任务准确率 vs. 主动探索开销,灰图标代表被动探索模式
视觉模态下,主动探索与被动探索存在鸿沟
缺陷二:脆弱的记忆与 “信念漂移”
通过给大模型做 “认知透视”,研究者发现其内部的空间信念呈现出极强的脆弱性。模型可能在第一眼准确记住了一个沙发的坐标,但随着它转身去探索另一侧的门,先前对沙发的 “信念” 就会迅速退化模糊,甚至被稍后收到的无关信息无端覆盖。这种无法维持长效、稳定认知地图的缺陷,被称为极其致命的“信念漂移”。
缺陷三:细思极恐的 “信念惯性(Belief Inertia)”
在 “纠错” 能力的测试中,研究人员复刻了心理学著名的 “错误信念” 实验:等模型探索完一圈后,悄悄挪动了几个关键物体的位置或朝向。
极其具有戏剧性的一幕出现了:当大模型再次路过并亲眼看到物体已经不在原地时,它对物体位置的预测,居然仍固执地偏向了老地方!数据显示,GPT-5.2 在视觉模型中的 “信念惯性” 高达 68.9%。这说明当前的 AI 缺乏认知可塑性,极难用眼前的视觉新证据去推翻脑海中陈旧的语言先验。

缺陷四:难以跨越的 “模态鸿沟(Modality Gap)”
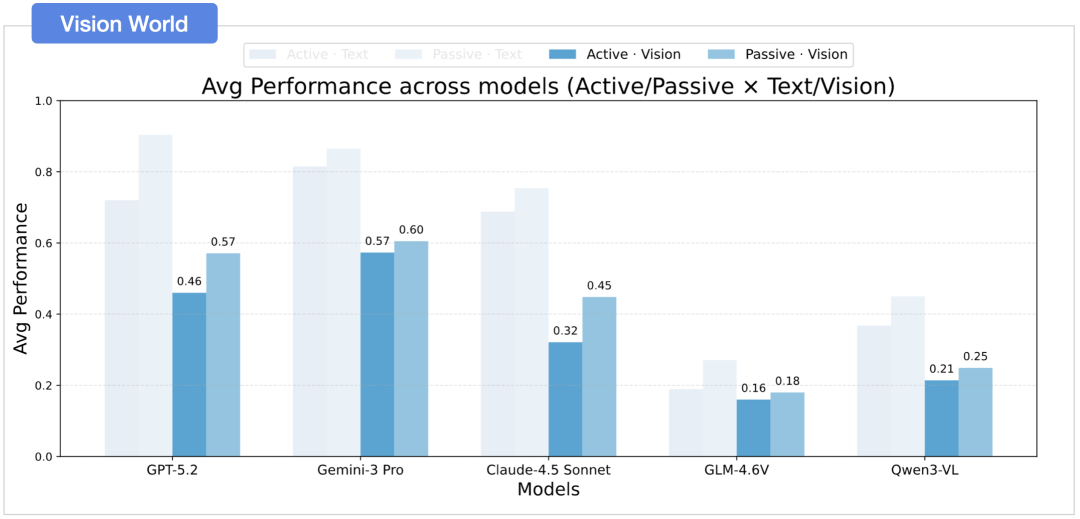
最终的统计数据指出了一条鸿沟:模型虽然在纯文本构建的虚拟房间中表现尚可(得益于长文本里强大的符号与语言逻辑),但一旦进入基于 3D 渲染的视觉世界(Vision World),面对必须依靠像素感知来推断深度的双重压力,得分直线下滑。
形成鲜明对比的是,人类在相同的视觉测试中,即使面对复杂布局,借助简单的工具也能轻松达到 99.0% 的超高准确率。总体来看,AI 在这方面仍与人类存在明显差距。
主动探索下视觉与文本存在巨大性能落差
4. 迈向下一代具身智能:从 “死记硬背” 到构建 “世界模型”
Theory of Space 这场大考绝不只是单纯的找茬挑刺,它更像是一份详尽的诊断书,指出了当下大模型在走向真实场景(如家用机器人、自动驾驶)时,亟待填补的能力空白。要孕育出真正能在复杂现实中自如穿梭的通用人工智能(AGI),未来的研究必须在以下方向寻求根本性突破:
突破一:培育具有强可塑性的 “空间长时记忆”
现有的多模态模型一旦转移视线,记忆往往如流沙般流失(信念漂移);亦或是对陈旧的先验固执己见(信念惯性)。未来的 AI 需要构建类似人类海马体般灵活的回溯机制,既能稳固地锁定绝对空间结构,又能根据即时的视觉线索精准剔除 “过期报废” 的错误记忆。
突破二:引入内在 “好奇心” 驱动的强化探索
当前的 AI 大部分仍处于 “你提问、我回答” 的被动反应模式中。而破局的关键,在于引入对 “不确定性” 的感知与博弈(Uncertainty-Awareness)。智能体应当能够主动评估哪些区域存在信息盲区,在内在 “好奇心” 的奖励驱动下,规划出信息增益最大化的探测轨迹。
突破三:真正拥抱 3D 物理法则的 “世界模型(World Models)”
如今的视觉语言模型依旧停留在 2D 像素层面的表面模式匹配,并未真正理解真实三维空间中的几何刚体法则。一个强大的 “世界模型” 不仅仅是一张扁平的数据表,它应该天然内蕴了物体的恒存性特征、视角变换间的物理恒等式。只有当大模型能够闭上眼睛,在脑海里无缝推演 “我向前走两步再右转最终会看到什么” 时,它才算真正获得了通关物理世界的通行证。
学会认知自身盲区,并主动向不确定性出击。这场以 “空间 IQ” 为坐标的试炼,彻底穿透了常规刷题基准下大模型虚增的表面分数。预测未知,拥抱未知,这不仅是具身大模型打破瓶颈的起点,更是未来 AGI 构筑真实物理世界闭环的必由之路。
(本研究已被 ICLR 2026 接收为录用论文,欢迎访问项目主页获取完整的论文、代码与数据集。)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com