扩散模型新突破!研究表明,即使使用弱先验和不匹配数据,也能实现高质量图像重建。观测数据充分时,重建由观测驱动而非先验驱动。
原文标题:反直觉!扩散模型「跨界」复原: 只用卧室模型,竟能复原人脸
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到“观测驱动”的重建过程,那么在实际应用中,我们应该如何判断观测数据是否“足够充分”?有没有什么量化的指标可以参考?
3、这项研究对医学影像领域有什么潜在的应用价值?例如,在数据稀缺的情况下,如何利用“弱先验”扩散模型来辅助疾病诊断?
原文内容

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。
这个领域长期以来普遍认为,作为先验的扩散模型必须足够强,且其训练图像分布需要与目标图像分布高度匹配。因此,经典算法通常会采用在目标领域上充分训练的扩散模型来进行图像恢复,否则恢复质量往往会明显下降。
然而,近期来自罗格斯大学、杜克大学和密歇根大学的一项最新研究表明,即使是「弱」扩散先验和完全不匹配的数据分布,也可以实现高质量图像重建。
这篇题为《Weak Diffusion Priors Can Still Achieve Strong Inverse-Problem Performance》的工作不仅展示了这种反直觉的实验现象,还首次从理论和实验层面解释了这种「弱先验依然有效」的机制。

-
论文地址:https://arxiv.org/abs/2601.22443
一个反直觉的实验:卧室扩散模型重构人脸

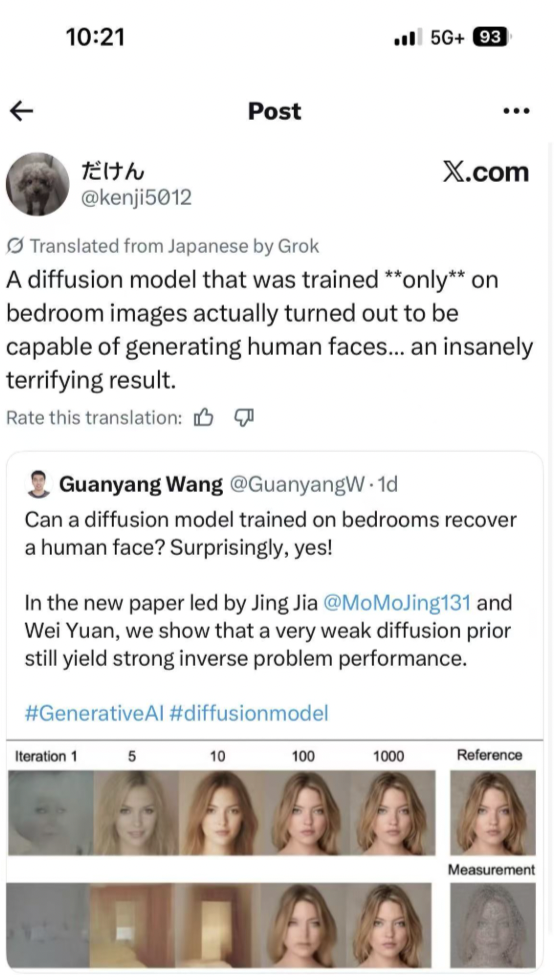
仅使用 3 步 DDIM 扩散模型作为先验进行图像重建:匹配先验(上)与不匹配先验(下)的对比。在底部左图(或底部右图)中,可以看到在卧室图像(或人脸图像)上训练的扩散模型依然能够重建人脸图像(或卧室图像)。从左到右展示的是优化迭代过程中不同阶段的中间重建结果。「Reference」列表示干净的真实图像,「Measurement」列表示带噪声的观测图像。
首先展示一组很有冲击力的实验。如上图左下所示,在优化初始噪声(initial noise optimization)的框架下,使用只在 LSUN-bedroom 数据集上训练的 3 步 DDIM 扩散模型可以重构 CelebA-HQ 数据集中的人脸图像。
扩散模型在初始阶段只能生成模糊的卧室图像,但随着优化不断推进,原本只能生成卧室图像的模型逐渐摆脱了低质量结果和「卧室结构」偏好,最终恢复出清晰且高质量的人脸图像。
同样的,用只能生成人脸的扩散模型,也可以有效重建卧室图像。可以从下面的动图看到这个「卧室变脸」的过程。

这个现象在 X 上也引发了讨论。有网友感叹道:「一个只用卧室图片训练的扩散模型竟然能生成人脸,真的太吓人了!」
这些现象进一步引导团队思考这样一个问题:在扩散先验较弱且训练分布与目标分布不匹配的情况下,图像复原成功的机制究竟是什么?
现实问题:强先验并不总是存在
这样的问题并不只是来自一些看起来「反直觉」的实验结果,更有明确的实际背景。在实际应用中,并不总是有一个高质量和数据匹配的先验模型:
-
内存和计算限制使得扩散模型步数被截断;
-
医学成像、遥感成像、科学成像等场景中,目标数据往往稀缺且分布特殊,很难专门训练一个完全匹配的生成模型。
这项研究旨在回答三个问题:
-
When(何时有效):弱 / 不匹配先验在什么条件下仍能实现高质量重建?
-
Why(内在机制): 这种超越分布的鲁棒性源自何处?
-
Limitations(失效边界): 这种能力在何时会达到极限?
核心结论:重建常是观测主导的
当观测数据本身提供足够充足的信息时,重建过程将由观测驱动(observation-dominant)而非先验驱动。因此,模型对先验的强弱和匹配度表现出显著的不敏感性。
简单来说,当观测数据维度高、强可辨识性、有效像素数量多时,后验分布会集中到真实解附近,即便先验较弱,也不会显著影响最终结果。
这一观点与传统「先验决定一切」的观点形成鲜明对比。
多任务实验全面验证
团队在图像复原(inpainting)、高斯去模糊(Gaussian debluring)、超分辨率(super-resolution)、非线性去模糊(nonlinear debluring)等经典图像逆问题上进行了大量的实验,采用的扩散模型和数据集包括 LSUN-bedroom、LSUN-church 和 CelebA-HQ。
实验结果显示:
-
在优化初始噪声的框架下,仅使用 3 步 DDIM 的弱先验扩散模型在 PSNR、SSIM、LPIPS 等各项指标上超过使用 1000 步模型的 baseline 方法;
-
即使模型训练数据领域与图像重建目标领域完全不一样,性能的下降也非常有限,甚至能够超越领域一致和使用 1000 步模型的 baseline 方法。
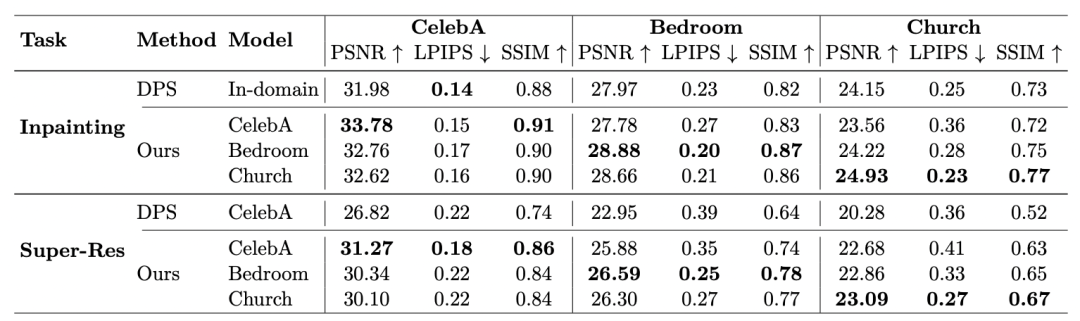
跨数据领域的图像修复与超分辨率结果对比。「Model」表示扩散模型的训练数据来源(即先验的源领域),「CelebA」「Bedroom」「Church」表示被重建图像的目标领域。需要说明的是,baseline 方法 DPS 始终采用与目标数据一致的领域内模型。
理论突破:从贝叶斯后验集中 (Posterior Concentration) 解释现象
为了理解这种现象,团队从贝叶斯视角出发,基于高斯混合模型建立了一个高维逆问题的分析框架,在满足一定的假设条件时:
-
后验分布会以维度的指数级速度集中在最匹配的重建图像附近;
-
当观测数据维度足够高、包含信息足够充分时(例如观测到的像素、边缘、纹理多),即使非常不同的先验分布,都会得到相似的重建图像。
另外,团队在 LSUN-bedroom、LSUN-church 和 CelabA-HQ 等数据集上进行了数据模拟,证明了上述理论分析的假设在实际数据和问题中的有效性。
弱先验模型的失效边界
值得注意的是,弱先验并非万能,团队系统分析了其失败场景。在观测图像信息不充分时,例如大面积连续遮挡(box inpainting)和极端超分辨率(16x super-resolution)这些低信息量任务中,重建图像将重新变得由先验主导(prior-dominant),在这种情况下强先验依然重要。
例如下图最后一列,使用人脸模型重建的教堂图像会出现明显的人脸特征。

上半部分:60% x 60% 连续遮挡;下半部分:16 倍超分辨率。
结论
团队系统地研究了弱先验扩散模型在逆问题中的应用,从实验和理论上证明了其有效性,并展示了其典型的失败模式,指出了清晰的应用边界,避免误用。
这项工作为社区带来的启示可能远超算法本身:
-
在观测数据信息充分的情况下,弱先验比传统认知中更有效。当使用者没有一个非常匹配的强先验时,可以使用弱先验进行图像重建;
-
在未来的研究中,研究者或将更多地关注弱先验,特别是少步数扩散模型先验的相关算法,同时考虑将初始噪声优化和传统算法结合。
作者介绍
本文共同第一作者为罗格斯大学计算机系博士生贾婧、统计系博士生袁伟。
其他作者包括杜克大学刘思繁、密歇根大学申荔月、罗格斯大学王冠扬。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com