Meta最新研究表明,多模态预训练是打破大模型瓶颈的关键。研究从视觉表示、数据组合、世界建模和架构设计等多方面进行了探索,为未来大模型发展指明了方向。
原文标题:多模态预训练,才是大模型的下一条路?Yann LeCun、谢赛宁参与
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到了MoE架构在多模态学习中的应用,MoE是如何实现“专家专门化”的?这种架构相比于传统的共享参数模型有哪些优势和劣势?
3、文章最后提到了一种“扩展不对称性”,即视觉任务对数据规模的需求高于语言。你认为这种不对称性会对未来的多模态模型发展产生什么影响?我们应该如何应对这种不对称性?
原文内容
基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
借用柏拉图《洞穴寓言》的比喻:语言模型已经非常擅长描述洞穴墙壁上的影子,却从未真正看到投射这些影子的实体。它们能够很好地捕捉符号,但却难以理解物理世界中高保真的物理规律、几何结构以及因果关系。
在这种哲学层面的局限之外,还存在一个更现实的天花板:高质量的文本数据是有限的,而且正逐渐接近枯竭。
相比之下,视觉世界拥有几乎无限的信号来源,那些洞穴之外的信息,记录着现实世界最原始的动态变化,而这些恰恰是语言所无法完整表达的。
因此,未来的发展路径需要走出影子的世界,直接去建模现实本身。
为此,来自 Meta、纽约大学的研究者转向统一的多模态预训练(unified multimodal pretraining):不再把视觉信号当作一种辅助输入,而是将其与语言一样,视为模型中的一等公民(first-class citizen)。

-
论文地址:https://arxiv.org/pdf/2603.03276v1
-
论文标题:Beyond Language Modeling: An Exploration of Multimodal Pretraining
本文一作为 Shengbang Tong(童晟邦)、Divid Fan 和 John Nguyen。著名研究者 Yann LeCun 和谢赛宁亦有参与。
当前,统一多模态预训练的科学研究版图仍然相当不清晰。尽管近期的一些研究已经开始尝试超越纯语言预训练,但整个设计空间仍充满了各种相互干扰的变量。
与从零开始同时学习视觉和语言不同,目前大多数方法仍然依赖以预训练语言模型为初始化。这种范式的核心目标,是尽量保留原有的语言能力,同时逐步让模型适应多模态任务。
然而,这些预训练语言模型中已经包含的大量知识,会对实验结果产生干扰,使研究者难以判断模型能力究竟来自统一多模态训练本身,还是来自语言预训练阶段继承的能力。因此,视觉与语言之间最基础的学习机制以及它们的扩展关系(scaling relationship)至今仍缺乏清晰理解。
本文试图为这一领域提供更清晰的实证认识,将研究重点放在预训练阶段,因为模型的大部分核心能力正是在这一阶段形成的。
在实现方法上,他们从零开始训练一个统一模型,并采用 Transfusion 框架:
-
对语言使用 next-token 预测;
-
对视觉使用扩散建模。
训练数据涵盖文本、视频、图文对,以及带有动作条件的视频数据。
同时,本文还设计了一系列可控实验来逐一隔离关键变量,并在一个全面的任务体系上进行评估,任务范围从语言能力评测、视觉理解与生成,一直延伸到世界模型中的规划能力(planning)。
具体而言,本文从以下几个维度展开研究:
视觉表示:论文评估了多种视觉表示方式,范围从变分自编码器(VAE)、语义表示(semantic representations)到原始像素。研究结果表明,表示自编码器(Representation Autoencoder,RAE)是最优的视觉表示方式。(第 3 节)
数据:论文研究了多种数据组合方式,从纯文本和视频数据到图文对数据以及带动作条件的视频数据。实验发现,不同模态之间的相互干扰非常小,在某些情况下甚至会产生正向协同效应。(第 4 节)
世界建模:论文将评测扩展到导航世界模型(Navigation World Model, NWM)场景,并将动作直接表示为文本 token。实验表明,模型的物理预测能力主要来自通用的多模态预训练(如视频数据),而不是依赖特定领域的数据。(第 5 节)
架构设计:他们在统一多模态框架下研究了 MoE 架构的设计选择,并观察到模型在训练过程中会自然形成模态分离与统一并存的结构。(第 6 节)
扩展规律(Scaling Properties):通过 IsoFLOP 实验推导了统一预训练过程中视觉与语言的扩展规律(scaling laws)。结果发现存在一种扩展不对称性:视觉任务对数据规模的需求明显高于语言。同时发现 MoE 架构能够有效弥合这种差距。(第 7 节)
统一多模态预训练中的视觉表示
这一小节研究了三类视觉编码器:
VAE 系列,包括 Stable Diffusion 的 SD-VAE 以及 FLUX.1;
语义编码器,既包括语言监督训练的编码器,也包括自监督编码器;
最后,本文还研究了直接使用原始像素作为输入的方案。相关实验结果见图 4。

文本性能。无论使用哪种视觉表示,模型的文本困惑度(perplexity)都与纯文本训练的基线模型相当,有时甚至略好,其中原始像素输入表现最好。不过,这种差异非常有限,说明多模态预训练并不会显著影响模型的语言能力,无论使用哪种视觉表示,其语言能力都与仅使用文本训练的模型基本一致。
视觉生成与理解。语义编码器在视觉理解和视觉生成两类任务上都持续优于基于 VAE 的编码器。例如,SigLIP 2 不仅在 VQA 上优于 FLUX.1,在图像生成基准测试(如 DPGBench 和 GenEval)上也表现更好。
这一结果呼应了 RAE 的研究发现:高维视觉表示在生成任务上的效果至少与低维 VAE 潜表示相当,甚至更好。这说明,一个统一的视觉编码器就足以同时支持视觉理解和生成任务。后续实验中将 SigLIP 2 作为默认视觉编码器。
建议 1:采用单一的基于 RAE 的视觉编码器(例如 SigLIP 2),可以同时在视觉理解和视觉生成任务上取得优异表现,从而简化模型架构,并且不会损害模型的文本性能。
理解数据的影响
预训练数据组成统一多模态预训练的前提是利用所有可用数据。然而,目前尚不清楚每种数据类型对最终模型是起到贡献作用还是干扰作用。为了更好地理解这一点,团队研究了三种具有代表性的混合数据:
-
文本 + 视频(不带文本注释的原始视频);
-
文本 + MetaCLIP(图像 - 文本对);
-
文本 + 视频 + MetaCLIP + 动作(上述所有内容 + 动作条件视频)。
所有多模态模型均在约 1 万亿个 token 上进行训练(5200 亿文本 + 5200 亿多模态数据),并与在 5200 亿文本 token 上训练的纯文本基准模型进行比较。
结果如下图所示,团队发现「文本 + 视频」组合在 DCLM 验证集和内部 Notes 语料库上均取得了所有混合数据中最佳的困惑度。在 DCLM 上,「文本 + 视频」甚至超越了纯文本基准模型,这表明:视频数据与语言建模至少是兼容的,甚至可能是有益的。这也意味着视觉本身并不是导致模态竞争的主要原因。
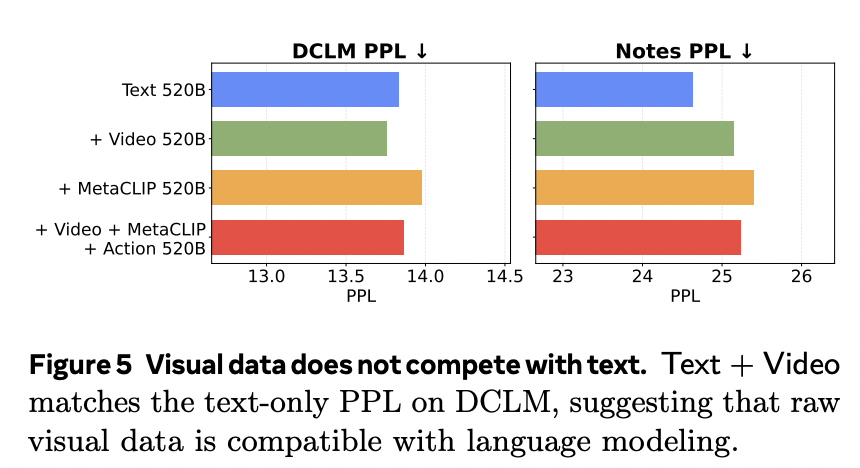
另一方面,「文本 + MetaCLIP」在所有混合数据中表现出的困惑度最差。而「文本 + 视频 + MetaCLIP + 动作」相比纯文本基准模型仅有轻微退化,这表明:视频 + 动作轨迹与文本也是互补的。
团队推测,文本性能的退化源于引入图像说明导致的文本分布偏移。
其次,团队还观察到,在所有混合数据中,相对于纯文本基准模型,在分布外(OOD)程度更高的 Notes 语料库上困惑度均有所下降,但相对趋势保持一致。这表明多模态预训练可能会在文本泛化能力上引入微小的权衡(Trade-off)。
建议 2:在训练中使用多模态数据(例如视频、图文对等)。视觉数据不会降低语言建模能力,而多样化的预训练数据还能为下游任务带来协同效应,例如世界建模(world modeling)和 VQA 等任务。
迈向统一多模态模型中的世界建模
基于这样一个观察:语言与视觉是互补的,且多模态预训练能够显著提升视觉问答(VQA)能力,团队进一步探索:在不对模型架构做任何修改的情况下,多模态模型是否可以扩展到「世界建模(world modeling)」任务。
团队采用 Navigation World Model(NWM)的设定,其中任务是:在给定当前上下文状态和导航动作的条件下,预测下一视觉状态:
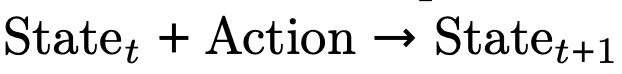
不过,与 NWM 将导航动作(如平移与旋转增量)编码为专门设计的连续向量不同,团队直接将动作表示为标准文本 token。
这样一来,该任务就可以被统一表述为:
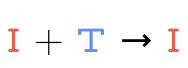
即「图像 + 文本 → 图像」的预测任务,并在统一多模态模型中完成。如下图所示,与 NWM 不同,团队没有引入任何动作专用适配器,也没有修改模型架构。

世界建模能力来自多模态预训练
团队一直在思考一个问题:有效的世界建模能力,究竟主要来自特定领域的导航数据,还是来自更广泛的多模态能力?
为了验证这一点,团队对以下模型进行了比较:
-
模型 A:基于 500 亿(50B)NWMtoken 和 500 亿多模态数据(文本、MetaCLIP、带文本注释的视频或纯视频)训练的多模态模型;
-
模型 B:仅基于 500 亿 NWM 数据训练的基准模型。
结果如下图所示,将特定领域的 NWM 数据从 500 亿扩展到 1000 亿 token 时,虽然在 ATE 和 RPE 上带来了一定的改善,但多模态预训练的效果更好。
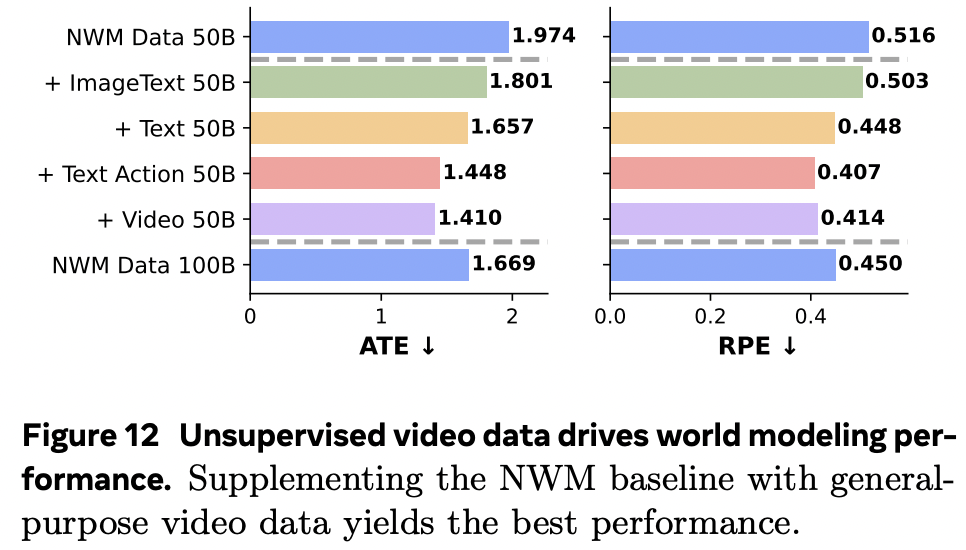
具体而言,添加纯视频数据带来的提升最大,但包括 MetaCLIP 和文本在内的所有其他模态也都有所帮助。这表明,世界建模更多地依赖于从多模态预训练中获得的能力,而非特定领域的数据。这与早期研究的发现相吻合。
世界建模能力可从通用训练中迁移
另外,为了进一步分析世界建模能力的来源,团队进行了消融实验,在保持总训练预算固定为 2000 亿 token 的情况下,改变 NWM 数据的比例。
结果如下图所示,性能相对于领域数据量的增加迅速达到饱和。团队观察到,模型仅需 1% 的域内数据即可达到极具竞争力的性能,比例更高时观察到的收益微乎其微。
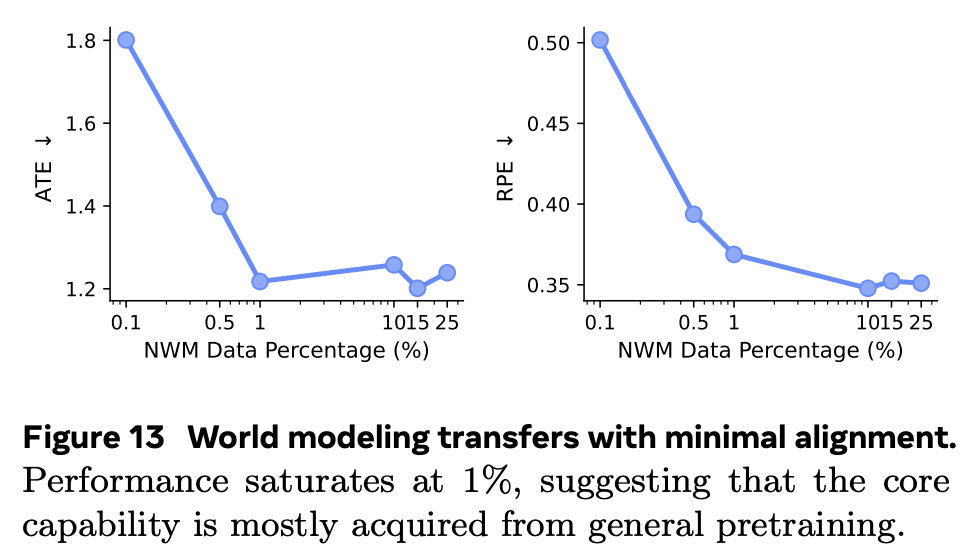
总的来说,这一发现加强了假设:导航和 VQA 等能力主要来自通用多模态预训练,仅需要极少的域内数据即可激活。
建议 3:统一的多模态预训练能够解锁世界建模(World Modeling)能力。只需将动作表示为文本 token,无需对模型架构进行额外修改;相关能力可以通过通用训练自然涌现,并且只需要极少的领域特定数据。
统一多模态架构设计
在前面的实验中,团队仅仅将共享的 FFN(前馈网络) 替换为模态专属 FFN,就发现能取得显著效果,这证明了适度的容量分离(capacity separation)具有很大潜力。
然而,模态专属 FFN 会在两种模态之间平均分配模型容量,而这种平均分配未必是理想的容量配置方式。
为此,团队进一步探索 MoE 是否能够通过解耦总容量与实际计算量,从而动态学习这种容量分离。
团队研究了 MoE 在统一多模态预训练中的设计空间,主要是希望了解 MoE 是否能够自动学习不同模态所需的容量分配,以及 MoE 是否能够在多模态训练中形成专家专门化。
而实验结果表明,模型确实会形成明显的「专家专门化」现象,具体来说:一部分专家主要处理文本 token,另一部分专家主要处理视觉 token,而且这种分工是自动形成的,并不需要任何显式的模态标签或约束。
进一步统计结果显示,随着训练进行,专家之间的分工逐渐稳定。某些专家几乎只接收文本 token,而另一些专家则主要处理图像 token,还有少数专家保持跨模态能力,能够同时处理多种模态输入。
这种现象说明:MoE 可以在不显式设计模态结构的情况下,自然形成功能分化。换句话说,模型会自动学习到不同模态所需的不同计算路径。
而相比固定的模态专属 FFN,MoE 具有两个优势:
-
动态容量分配:不同模态可以使用不同数量的专家。
-
灵活的专家共享:一些专家可以同时服务于多种模态。
因此,MoE 为统一多模态模型提供了一种更加灵活的架构方案。
建议 4:在统一模型中采用 MoE 架构。它的效果优于人为设计的模态分离策略,并且能够从数据中自然学习出针对不同模态的专门化能力。
统一多模态模型的扩展律
本文同时推导了视觉与语言两种模态的扩展规律(scaling laws),并进一步研究模型架构如何影响这些扩展趋势。
图 23 展示了 Dense IsoFLOP 的结果。
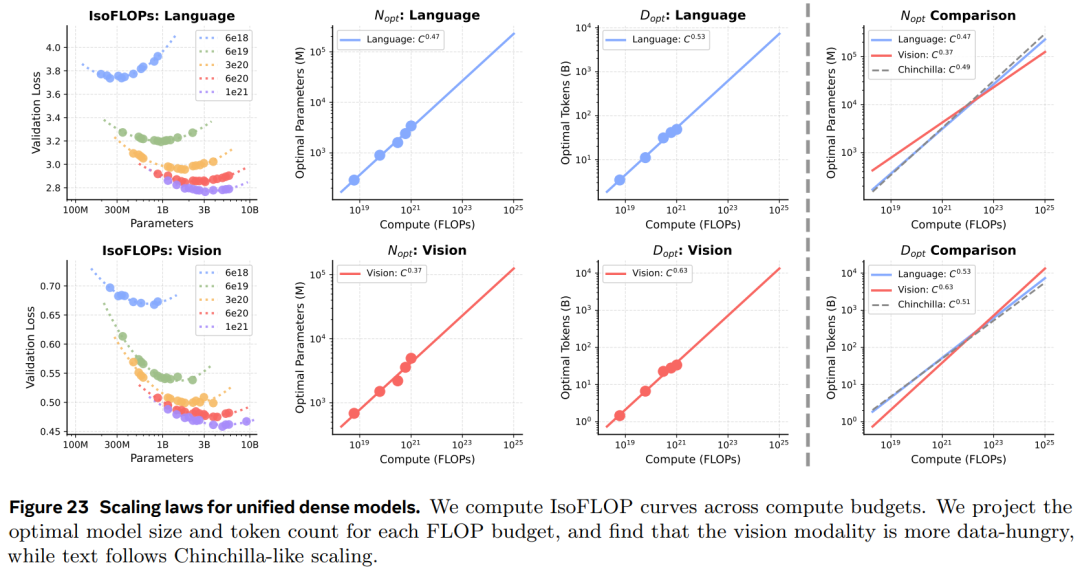
图 24 显示统一模型的性能可以达到甚至超过单模态基线。
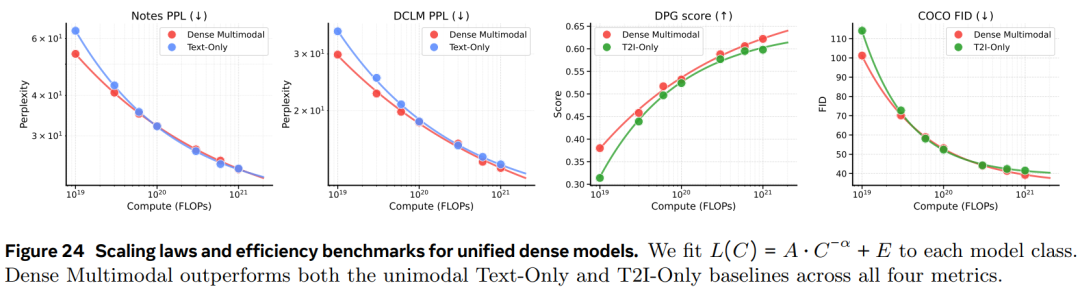
图 25 展示了 MoE IsoFLOP 结果:

图 26 比较了 MoE Multimodal + RAE(SigLIP 2) 与单模态 MoE 基线在整个计算范围内的表现。结果表明 MoE 使得单一模型可以在两种模态上同时达到接近单模态模型的性能,而且只需要极小的额外开销。

更多信息,可阅读原文获取!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com