REDSearcher 提出一种低成本可扩展的深度搜索Agent训练框架,其30B参数模型在深度搜索任务上超越GPT-5,为AI自主探索提供新路径。
原文标题:30B参数超越GPT-5!REDSearcher让「深度搜索Agent」做到低成本可扩展!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、REDSearcher使用了Mid-Training来强化Agent的能力,那么这种Mid-Training和传统的Fine-tuning有什么区别?在什么情况下我们应该选择Mid-Training而不是Fine-tuning?
3、文章提到REDSearcher通过SFT+Agentic RL双阶段增强Agent的能力,其中Agentic RL是如何保证数据质量的?这种Agent-as-Verifier的方法有什么优势和劣势?
原文内容

「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
这并不是一道靠记忆就能解答的题。Agent 必须在多轮环境交互中,不断假设、验证并修正路径,始终保持推理一致性,才能将零散证据整合成自洽链条。
2025 年被视为 AI Agent 元年,但真正的自主 Agent 核心在于「深度搜索」,在长程任务中像人类专家一样维持目标、验证信息并动态调整策略。然而,训练这样的 Agent 面临三大瓶颈:
-
数据稀缺:高难度长程问答任务极度依赖人工标注,成本高昂。因此,我们需要一条能够自动化合成高难度问题的链路。
-
能力鸿沟:预训练模型虽知识储备丰富,却缺乏与真实环境进行长程交互的能力。这需要通过低成本的中训练阶段来弥补鸿沟。
-
环境缺失:在真实环境中训练成本高且不可控。一个功能等价的模拟环境,可以在本地复现搜索过程,从而支持算法的快速迭代。
为突破瓶颈,REDSearcher 团队设计了一套低成本、可扩展的训练框架,最终使用 30B 规格模型在深度搜索任务上取得开源模型 SoTA,并且超越了 GPT-5 等一众闭源模型。

-
论文标题:REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
-
项目主页:https://github.com/RedSearchAgent/REDSearcher
-
论文链接:https://arxiv.org/abs/2602.14234
-
Collections:https://huggingface.co/collections/Zchu/redsearcher
一、什么是「足够难」的深度搜索题目?
什么是困难的搜索题目?推理跳数往往只是表象,应该追求的是问题的结构性困难。
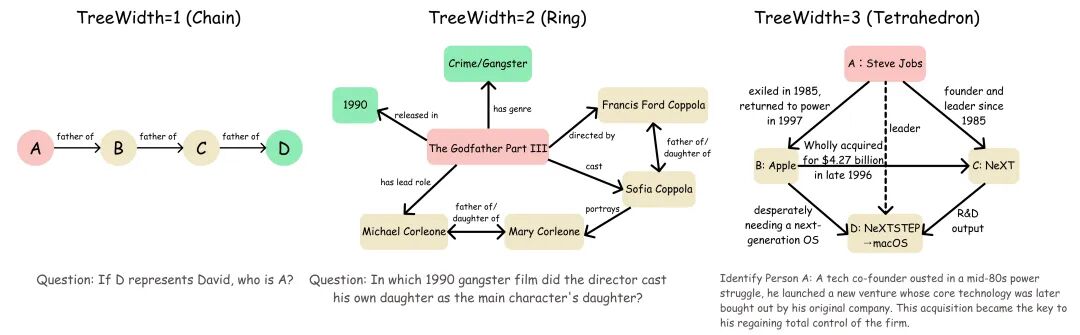
1. 拓扑复杂度:用树宽衡量「结构性困难」
复杂任务中,信息分叉交织形成回环。Agent 需同时记忆多路推论,时刻验证一致性,并随时准备整体回溯,这便是深度搜索的核心挑战。为此,团队引入图论中的 TreeWidth(树宽)概念来刻画这种「结构性困难」。以下通过三种结构问题进行对比:
-
线性/树状(树宽=1):典型链式推理,只需按部就班检索便可解答。
-
菱形/回环(树宽=2):出现分叉与重汇合,要求 Agent 维持多路假设的一致性,并在矛盾时进行回溯。
-
强耦合子图(树宽≥3):形成网状约束,需要将零散证据拼合成一致的整体,迫使模型进行全局验证和回溯。
2. 信息分散度:杜绝搜索「捷径」
即使问题的拓扑结构很复杂,如果存在一个网页恰好包含所有关键事实,模型一次检索就能抄走答案。为此,团队引入「信息分散度」,即覆盖全部关键证据所需的最小来源数。信息分散度越大,表明问题相关的证据片段(注:原文为“争取片段”,疑为笔误,此处已作修正)在互联网上的分布就更加零散,这迫使 Agent 与外部环境进行更多轮次的交互从而获取更加充分的信息。
二、大规模「自动化」合成
「高难度」的深度搜索问题
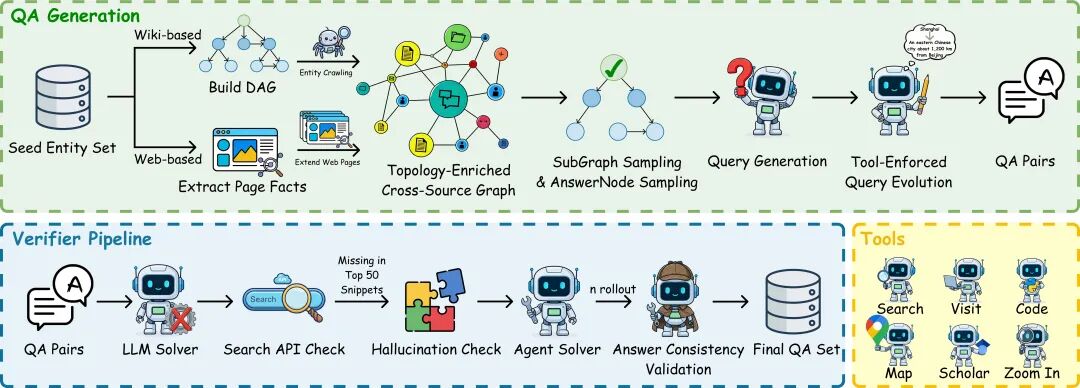
基于双约束复杂度标准,我们采用 graph-to-text 流程合成数据:先生成符合树宽与分散度的推理图,再将其翻译为自然语言问题,并经过多层校验确保「高难度、可解且答案唯一」。同时,我们设计了基于「结构化信息」与「网络浏览」两套图构造流程,以覆盖不同搜索环境。在合成问题中,我们采取:
-
拓扑结构增强:直接生成高树宽图的成功率较低。为此,我们引入大模型智能体对初始依赖图进行「拓扑加密」,通过添加环状与交错约束,显著提升结构复杂度,迭代地提高问题难度。
-
工具增强的问题合成:在问题构造阶段,我们主动植入工具调用需求。通过将关键实体替换为隐含工具依赖的表达(如地名→地图服务、文章→谷歌学术),使工具调用成为解题前置条件。
三、多模态扩展:从「文本图」到「多模态图」
在文本合成基础上,REDSearcher 通过模态注入将纯文本推理图转化为跨模态推理,使部分约束锚定在图像中。
-
视觉属性锚定:用图像描述替换节点的文本属性,迫使模型先识别图像再关联知识。
-
跨模态依赖:设置视觉不可替代约束,使图像搜索成为推理必经之路,而非冗余信息。
-
视觉语义抽象:使用抽象指代替代直接命名,迫使模型识别图像内容后再进行搜索。
-
模态灵活插入:视觉证据可插入推理链任意位置,既可早期设置瓶颈增加难度,也可后期引入验证,实现难度精细控制。
通过这套轻量级扩展,REDSearcher 可高效迁移至多模态搜索领域,合成高质量的图文深度搜索问题。
四、「成本可控」Mid-Training 强化智能体能力
预训练模型缺乏多轮交互训练,在长程搜索中易出现目标漂移、重复搜索等问题。为此,REDSearcher 采用可扩展的两阶段 Mid-Training 框架,依次强化模型的「原子能力」与「组合能力」,实现从语言建模到智能体的过渡。
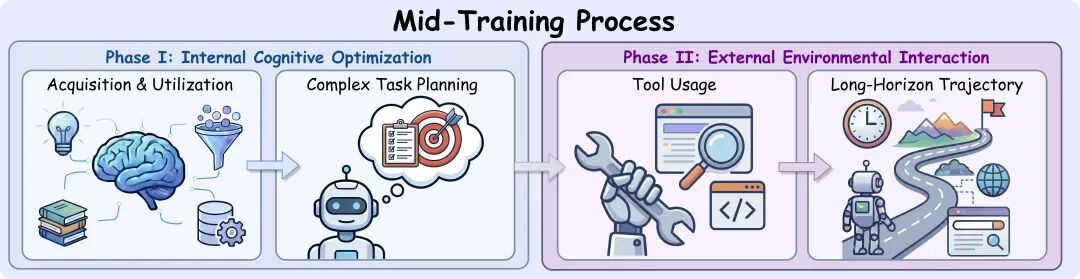
原子能力建设
针对深度搜索重要的两个基础能力优化:
-
意图锚定:从含噪的观测中精准抓取关键证据,过滤噪声,减少幻觉与推理漂移。
-
层次化规划:将复杂目标拆解为可立即求解的具体目标与需逐步消解的不确定目标,确保规划可落地。
组合能力建设
通过环境交互强化长程任务中的状态维持与目标一致性,全程以成本为约束:
-
工具调用能力:通过合成工具协议与本地模拟环境交互,使模型在 ReACT 范式下掌握基础与外界环境交互能力。
-
长程交互能力:在「功能一致」模拟环境中,让 Agent 进行长程的环境交互,强化规划能力与目标一致性。
五、后训练持续进化:
不只是「搜得多」,更要「搜得准」
后训练采取 SFT + Agentic RL 双阶段增强:
-
在真实环境中交互,通过多重过滤获取长程高质量轨迹,教会模型深度搜索行为。
-
在真实搜索环境中进一步优化策略,关键设计包括:
-
低成本验证:构建「功能等价」的本地模拟环境,保持 API 一致、证据完备且含噪声,加速实验迭代。
-
数据质量保障:针对合成问题中存在的答案错误、一题多解现象,采用 Agent-as-Verifier 对强化学习问题集进行校验,避免数据污染影响训练稳定性。
团队观察到了效率与性能同步提升的现象:随着训练进行,模型的平均交互轮次不断下降,但准确率持续提升。这表明 REDSearcher 并非简单的「暴力搜索」,而是学会了更精准的信息获取策略,主动减少无效调用,形成「越训越聪明」的良性循环。
六、实验结果
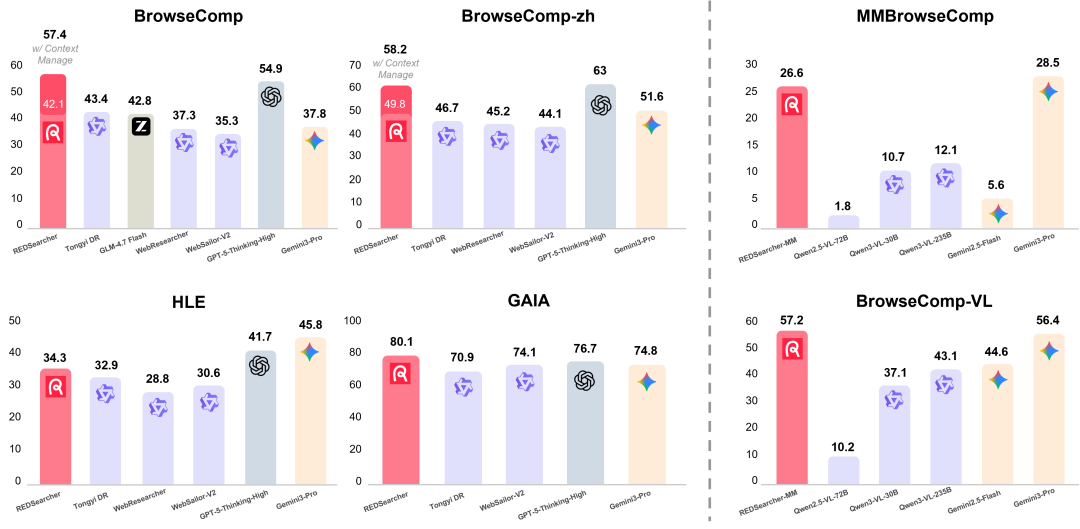
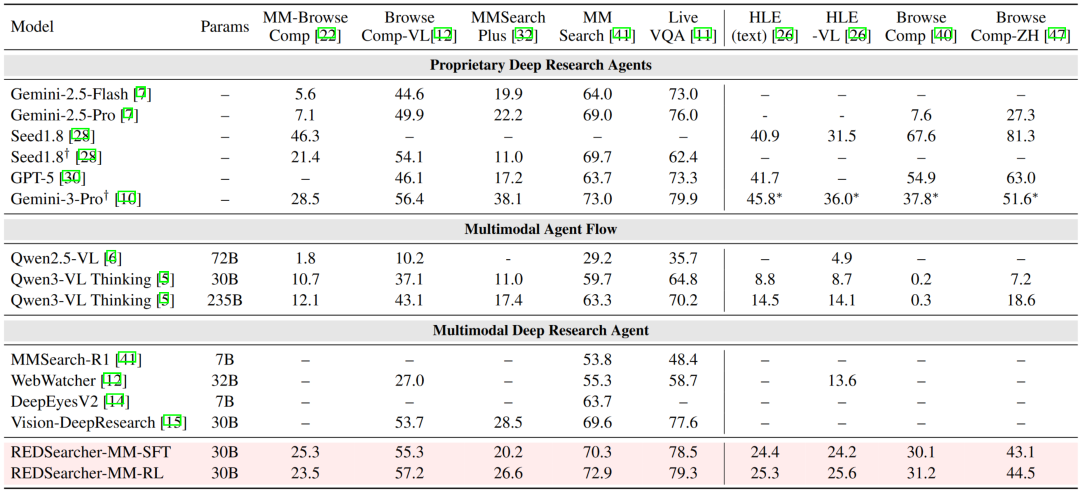
在多项深度搜索权威基准上,REDSearcher 在开源模型中取得了优异的表现:
-
REDSearcher 在同规模开源模型中取得了 SoTA 水平,并且超过了 GPT-5-Thinking-high、Gemini-2.5-pro、Claude-4.5-sonnet 一众闭源先进模型(*为带有上下文管理的性能)。
-
REDSearcher-MM 在多模态搜索基准中相比同规格模型取得了 SoTA 水平,并且性能超过 Gemini-2.5-pro,在部分基准上取得了接近 Gemini-3-pro 的性能。

结语
REDSearcher 的核心在于系统性设计:从图论角度定义深度搜索任务复杂度,以双约束优化可扩展合成数据,以两阶段中间训练降低能力迁移成本,以高质量轨迹合成结合强化学习实现持续迭代。它提供了一条可复现、低成本的深度搜索智能体训练路径,使 AI 系统从静态知识查询走向开放环境下的自主探索、验证与信息整合。
作者简介
初征,哈工大社会计算与信息检索中心在读博士生,由刘铭教授和秦兵教授共同指导,研究方向是智能体、大语言模型、复杂推理、深度搜索。
王枭,就职于小红书 Hi Lab,负责Search Agent,主要关注长程推理、智能体、数据合成、强化学习。
Jack Hong,小红书 Hi Lab 团队算法实习生,主要研究方向是多模态大模型、Agent、计算机视觉等。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com