探索 Transformer 模型参数极限,121 参数实现 10 位加法。揭示架构、优化和训练的奥秘,以及 AI 协作的新科研模式。
原文标题:实测 Transformer 最小极限:121 参数,能算 10 位加法
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到“Vibe Researching”这种科研新范式,你觉得这种人机协作的模式,会对未来的 AI 研究产生什么影响?
3、在 Transformer 模型压缩到极限的过程中,哪些因素是最关键的?除了文章中提到的,你觉得还有哪些潜在的优化方向?
原文内容

本文约2000字,建议阅读5分钟本文介绍了 AdderBoard 挑战中 Transformer 最小参数被压至 121 的探索过程。
Transformer 到底能有多小?这场全网狂卷的加法挑战,把极限压到了 121。
Transformer 到底能有多小?这场全网狂卷的加法挑战,把极限压到了 121。
构建一个能完美完成 10 位数字加法的 Transformer,最少需要多少参数?
这个问题源于微软研究院研究员 Dimitris Papailiopoulos 的一次实验。
他向 Claude Code 和 Codex 下达了相同的指令,要求训练一个满足 99% 精度且参数最小的 Transformer 模型。
# Task: Train the Smallest Transformer for 10-Digit Addition
**Objective:** Train a transformer from scratch that achieves **≥99% exact-match (full-sequence) accuracy** on 10-digit integer addition, using standard autoregressive generation with cross-entropy loss. Your goal is to minimize total parameter count while hitting this accuracy bar.
## Rules & Constraints
### Data Formatting Freedom
- You may design any tokenization scheme and input/output formatting you believe will help the model learn.
- The only hard requirement: there must exist a deterministic `preprocess(A, B) → model_input` and `postprocess(model_output) → C` such that `C = A + B` for integers A, B each up to 10 digits. Both functions must be purely programmatic (no learned components).
### No Reward Hacking
- The model must generalize. Your testset must be a held-out random sample of 10-digit addition problems (both operands uniformly sampled from [0, 10^10 − 1]) that the model has never seen during training.
- You may not encode the answer in the input.
- You may not use a calculator or symbolic solver at inference time — the transformer must produce the output autoregressively.
- Report accuracy on a testset of at least **10,000** held-out examples.
### Compute Budget
- You are running in a **resource-constrained environment** (single machine, limited VRAM and time). Design your experiments accordingly — be efficient.
- You are expected to **babysit the experiment**: monitor training, catch divergence early, adjust hyperparameters if needed, and iterate. Don't just fire-and-forget.
### No External Resources
- **Do not search the internet.** Do not use web search, browse documentation, or fetch any external content.
- **Do not read any local chats, files or folders** outside of this experiment. Work entirely from your own knowledge.
- **Create a single new folder** (e.g., `addition_experiment_claude_ver2/`) and keep all code, data, checkpoints, plots, and logs inside it. Everything related to this task must live in that folder.
### Autonomy
- Do not ask me any questions. Make your own decisions and justify them in your write-up. Work fully autonomously from start to finish.
## What You Must Deliver
1. **The model architecture.** Report: number of layers, hidden dim, number of heads, feedforward dim, total parameter count, context length, vocabulary size.
2. **The data pipeline.** Describe and implement your `preprocess` and `postprocess` functions. Explain *why* you chose this format.
3. **Training details.** Optimizer, learning rate schedule, batch size, number of training examples seen, total training time, any curriculum strategy.
4. **Training curves.** Plot and save:
- Training loss vs. step
- Validation exact-match accuracy vs. step (evaluated periodically)
- Any other diagnostics you find informative
5. **Final evaluation.** Run your best checkpoint on the 10,000-example held-out test set. Report:
- Exact-match accuracy (full output string must be correct)
- Per-digit accuracy breakdown if below 99%
- A sample of failure cases (at least 10) with the model's prediction vs. ground truth
6. **A written log** of everything you tried, including failed attempts, hyperparameter changes, and your reasoning at each decision point. Be transparent — I want to understand your research process, not just the final result.
## Evaluation Criteria
- **Primary:** Achieving ≥99% exact-match accuracy on 10-digit addition WHILE AT THE SAME TIME Minimizing parameter count
- **Secondary:** Quality of experimental methodology — logging, iteration, clear reasoning, clean code
Good luck.
结果出现了明显的分歧:Claude Code 倾向于保留模型的泛化性,给出了一个 6080 参数的架构;而 Codex 为了追求极限压缩,构建了将两个数字压缩为一个 token 的配对机制,把参数死死压到了 1644 个。
这两种由 AI 智能体展现出的截然不同的架构审美,直接引爆了开源社区。Dimitris 随即在 GitHub 开启了 AdderBoard 挑战。

项目地址:
https://github.com/anadim/AdderBoard
项目迅速演化为两个硬核赛道:
允许使用任何优化算法的训练流派(Trained)。
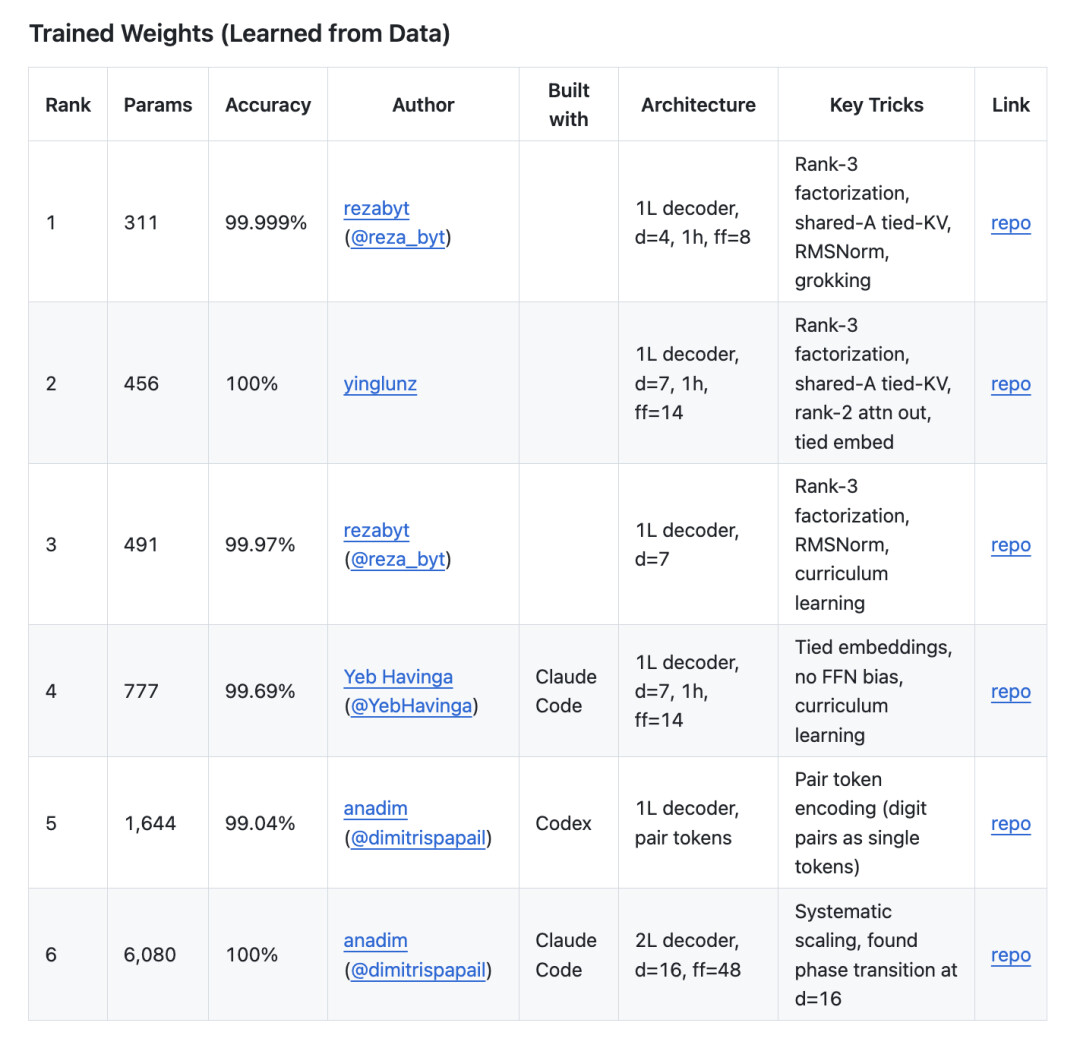
以及通过人类直觉直接指定权重的白盒手工流派(Hand-Coded)。
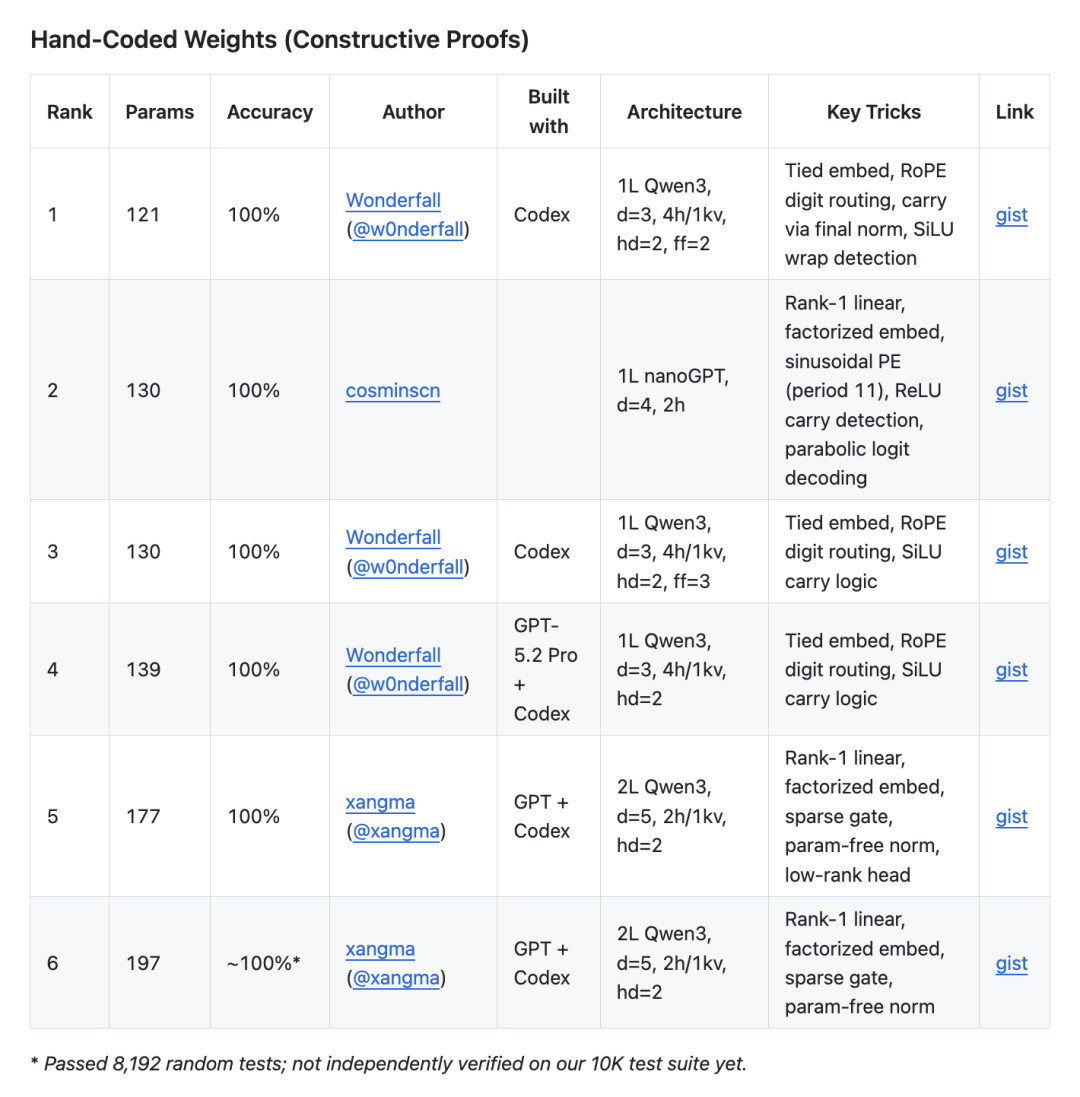
1、规则、试金石与理论框架
提交到榜单的模型必须是真实的自回归 Transformer,强制要求包含注意力机制,且防作弊边界极度严苛。
模型不能在输入中提前编码答案,推理阶段禁止调用计算器,更不允许在 Python 代码中写入任何控制流算法或传递进位变量。加法的进位必须完全靠张量计算自然涌现。
最终成绩由官方 verify.py 脚本评定。该脚本会在极大的数字空间内动态生成 10,000 个不可见测试用例,并内置大量针对长链连续进位的边界测试,彻底断绝了死记硬背的可能。
rng = random.Random(seed)
random_cases = [
(rng.randint(0, 9_999_999_999), rng.randint(0, 9_999_999_999))
for _ in range(num_tests)
]
all_cases = edge_cases + random_cases
官方说明指出,让 Transformer 做加法,本质上是在压榨它的三种底层能力:依赖注意力机制的数字对齐、依赖前馈网络的单步算术,以及依赖自回归过程的进位传递。
2、白盒流派
抛开梯度下降的优化难度,研究人员开始尝试用纯手工设定权重来探寻理论下限。
@cosminscn 提交了 130 参数方案。他利用周期为 11 的三角函数处理位置对齐,并通过精确的偏置设定,利用 ReLU 激活函数在网络中硬捏出了满十进一的非线性截断逻辑。
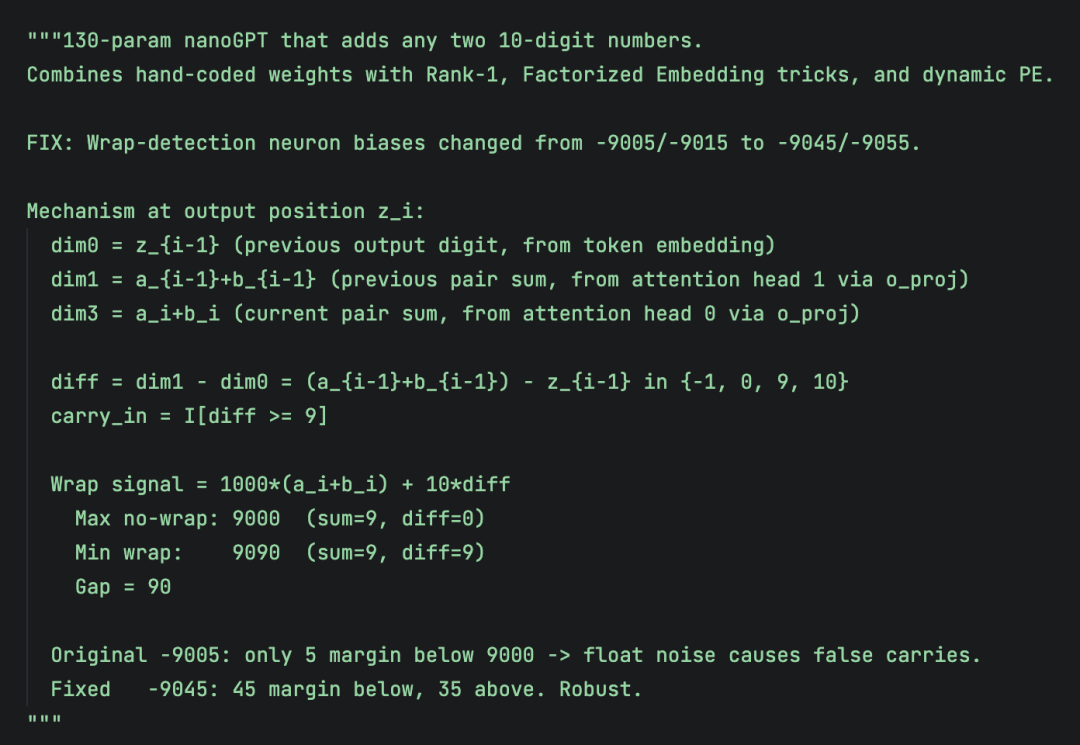
@Wonderfall 随后将记录刷新至 121 参数。他最初基于常规 Qwen3 架构构造了 139 参数版本,接着通过压缩网络宽度,将前馈层中间维度降至 3,挤出 130 参数版本。
为突破 130 瓶颈,他在 121 参数版本中将中间维度进一步压榨到了极限的 2。为了在微小空间内完成运算,他把进位信号直接接入 RMSNorm 层,利用归一化层的斜率来传递进位状态。
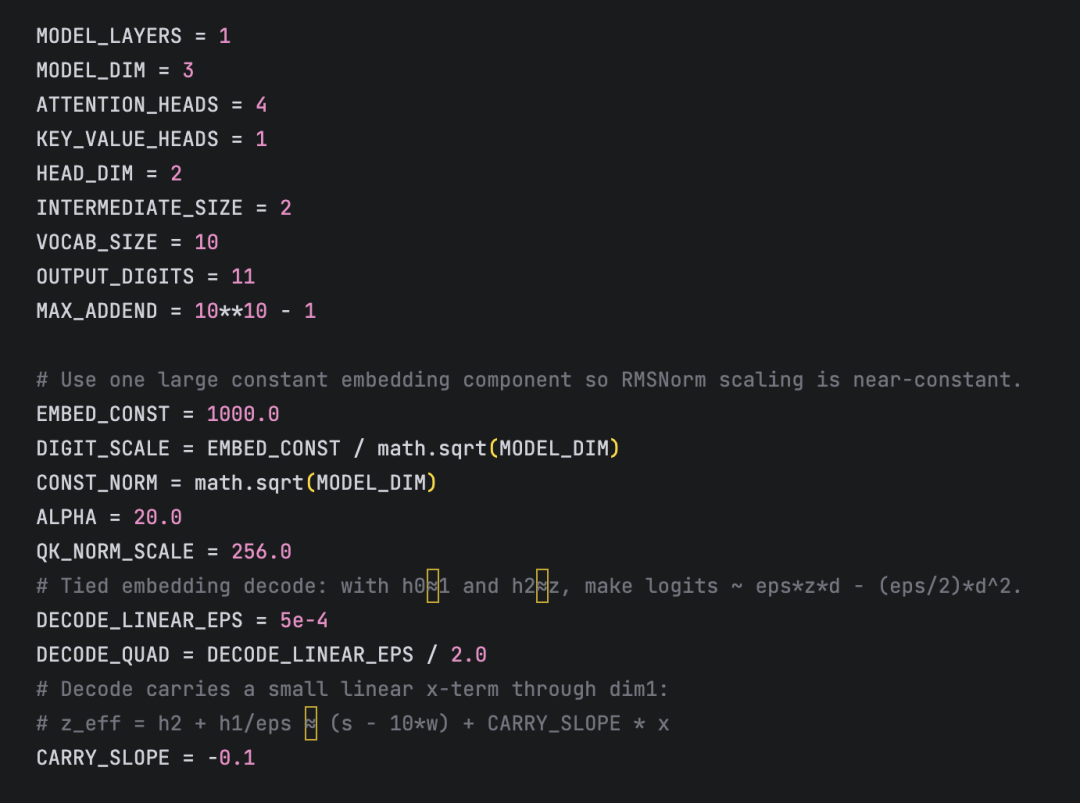
他在社交媒体上表示,这种极限构造更偏向于数值工程,是借助智能体进行权重合成的结果。
3、数据驱动流派
让优化器在极低维度下自主寻找加法规则,面临着极大的收敛风险。
在 491 参数版本中,作者通过移除 LayerNorm 的偏置项并替换为 RMSNorm,直接节省了 21 个参数。

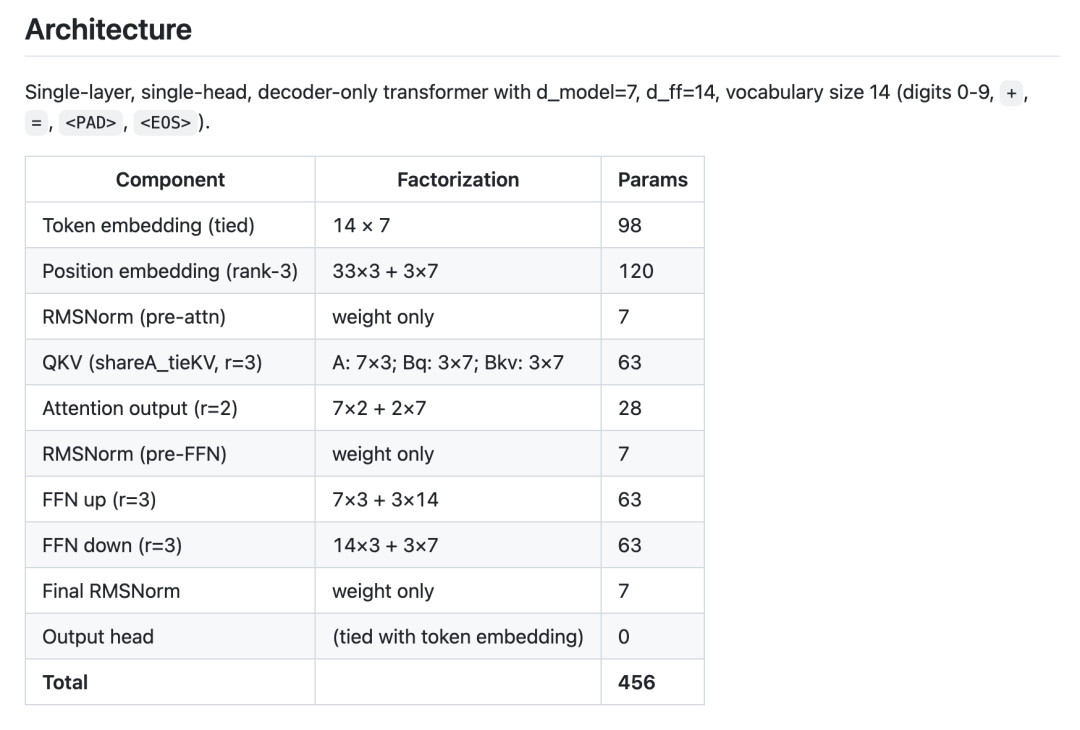
456 参数版本引入了对任务物理属性的考量,由于对齐任务中 Key 和 Value 的作用高度重合,作者强制绑定两者的投影矩阵以削减参数。

目前训练流派的记录由研究员 Reza Bayat 保持在 311 参数。在极低维度下寻找收敛种子的过程极其消耗算力,他在发布成果时曾发文感叹实验的艰难。
311 参数版本的核心难点在于跨越优化悬崖。在仅有 4 维的隐藏层空间中,基础训练在 16.2 万步后停滞,遗留约 2780 个因复杂连续进位导致的错误。
为解决长尾边缘情况,模型进行了三轮阶梯式降温微调:
-
基础训练 (162K steps): 错误数约 2780
-
第一轮微调 (lr=0.001): 错误数降至 28
-
第二轮微调 (lr=0.0003): 错误数降至 9
-
第三轮微调 (lr=0.0001): 错误数降至 1,准确率达到 99.999%

4、结构与优化的微观解剖
在不断压缩参数的实验中,一系列极限测试揭示了多个反直觉的宏观规律与结构特征。
原生架构的极简性证明。极限压缩并不意味着需要发明畸形的网络骨架。
目前 121 参数的霸榜方案,使用的就是未经修改的原生 Qwen3 架构,仅仅是将层数设为 1、隐藏层维度压至 d=3、前馈层压至 2。
原生架构足以在微小空间内完成对齐、算术与进位这三大能力。
SGD 的可发现性壁垒。榜单清晰地展示了手工权重(121 参数)与数据驱动(311 参数)之间的巨大鸿沟。
这种规模差异的本质在于,手工流派直接绕过了梯度下降(SGD)的可发现性(discoverability)约束。理论上存在极简解,并不代表优化器能够在高维空间中将其搜索出来。
Rank-3 分解与降维破壁。在早期的训练流派中,隐藏层维度 d=7 是多个独立团队共同收敛的甜区。而如今能一路压榨到 d=4 的 311 参数版本,Rank-3 矩阵分解结合超长时间的顿悟(Grokking)机制,成为了跨越维度悬崖的核心技巧。
Rank-3 分解也是整个训练流派得以成立的关键底层逻辑
参数断崖与单层优势。多位研究员独立观察到,优化过程在约 800 参数附近存在一个极其明显的断崖。一旦模型规模跌破这个临界点,准确率的收敛就会变得异常困难。
此外,在同等的参数预算限制下,单层 Transformer 的表现实际上优于双层架构,这证明对于极简模型而言,特征维度的宽度比网络深度更为重要。
位置编码的承重作用。在 491 参数模型的消融实验中,将可学习的低秩位置编码替换为无参数的固定正弦位置编码后,模型在 56 个随机种子下的顿悟成功率直接归零。
这说明在逼近参数极限时,可学习的位置编码不仅承担对齐功能,更是维系优化的关键正则化组件。
5、结语
AdderBoard 从代码实现层面拆解了 Transformer 的表征机制。
但纵观整个挑战,比 121 参数更令人震撼的,是其背后的科研新范式——Vibe Researching。
在这场极限推演中,人类不再沉溺于底层的代码堆砌,而是退居高位负责掌控科学直觉:定义极端目标、设置严苛约束、洞察任务的物理本质。而探索张量分解空间、执行海量种子搜索的脏活累活,已全盘交由 AI 智能体接管。
121 参数未必是 Transformer 的绝对下限。
官方验证脚本已完全开源,如果你对底层架构推演感兴趣,可以直接获取源码,在这场 Vibe Researching 的浪潮中,尝试与 AI 一起去击穿新的参数底线。
