Luma AI推出Uni-1模型,华人团队打造统一理解与生成架构,在图像编辑任务上超越Nano Banana,展现出强大的推理和理解能力。
原文标题:海外华人15人团队打造,统一理解与生成的图像模型,超越Nano banana登顶图像编辑
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Uni-1模型通过生成训练提升理解能力,这种思路给你带来了哪些启发?你认为未来AI模型的发展趋势是什么?
3、文章提到Uni-1团队规模较小,但取得了超越规模优势的结果。你认为小型团队在AI研究中如何发挥优势?
原文内容
上周,谷歌推出了 ,主打一个又快又便宜,迅速在社交平台刷屏。
网友们在 X 上晒出各种效果图,有像素级还原的产品渲染、细节拉满的人物写真、风格各异的插画……
这股热浪还未消退,海外 AI 初创公司 Luma 也发布了一款最新图像生成模型 Uni-1。
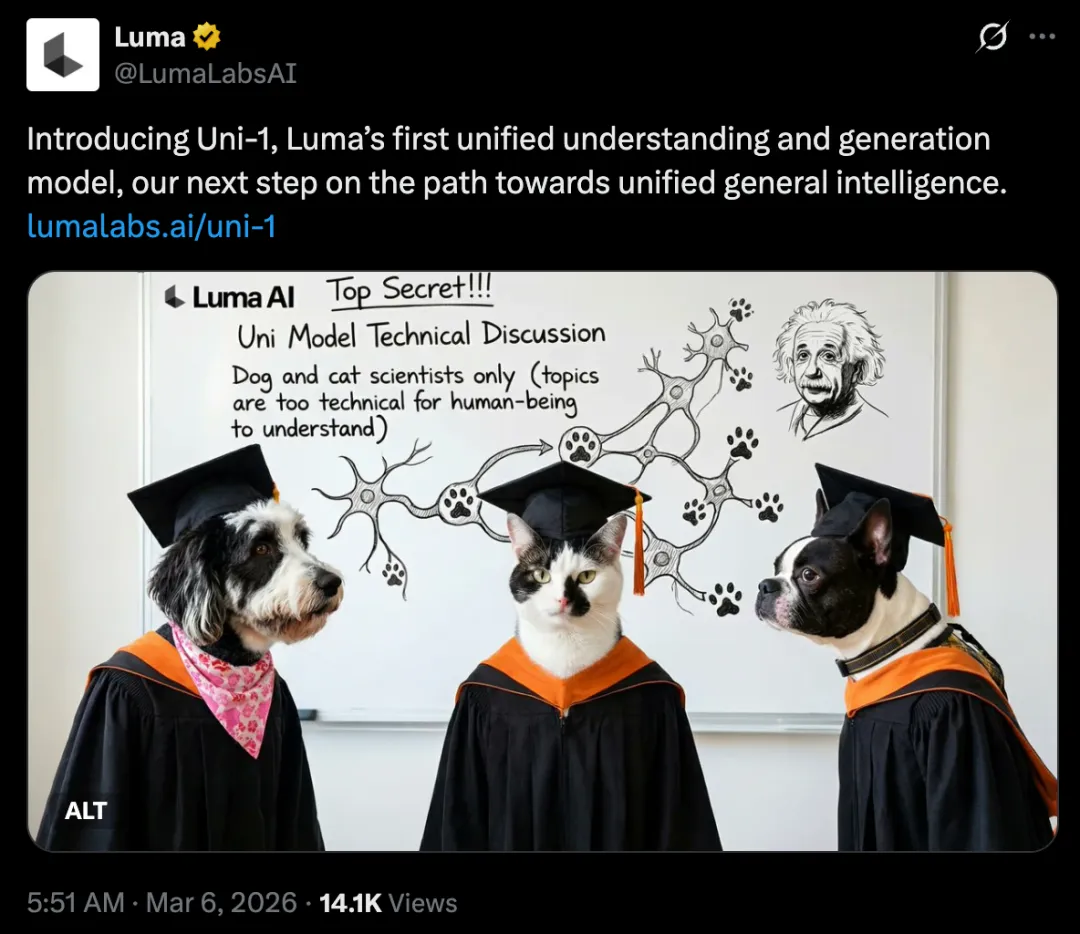
这是 Luma 首个将「理解」与「生成」统一在同一套架构里的模型,试图让 AI 不只会画,还真的会想。
比如,它生成的极具视觉冲击力的时尚杂志大片:

Prompt:Figure seen from behind wearing a flowing white cloak and wide-brimmed black hat standing in a vast field of tall vivid red grass, rolling hill stretching to the horizon, deep saturated blue sky with no clouds, strong color contrast between red field white fabric and blue sky, shot on medium format film, infrared photography aesthetic, high fashion editorial feel, sharp shadows, portrait orientation
生成同一棵樱花树的四季景色更迭:

Prompt:The four seasons of a single cherry blossom tree shown simultaneously in one image, divided into four vertical strips left to right: spring with pink blossoms and rain, summer with full green canopy and butterflies, autumn with red and gold leaves falling, winter with bare branches and fresh snow. Same tree, same angle, seamless transitions between seasons.
该模型采用 decoder-only 自回归 Transformer 架构,在 RISEBench 推理式生成基准上取得最优成绩,并在 ODinW-13 开放词汇密集检测等理解任务上展现出强劲竞争力。
这款模型效果咋样,还得拉出来遛遛。
这款模型成色几何?
接下来,我们将通过多组任务,看看 Uni-1 在不同场景下的具体表现。所有对比均在相同 prompt 条件下与 GPT Image 1.5 和 Google Nano Banana Pro 进行。
中文文字渲染:马年新春贺卡

Prompt:生成一张包含「新春快乐」、「马年大吉・万事如意」、「马年 二〇二六」等中文文字的马年新春贺卡。
中文文字渲染长期以来是图像生成模型的薄弱环节,涉及字符级别的精确控制和排版语义理解。
Uni-1 生成的贺卡在文字完整性、排版合理性和视觉风格一致性上均优于对比模型。GPT Image 1.5 出现了文字排列混乱的问题,而 Nano Banana Pro 的文字渲染存在明显的笔画瑕疵。
信息图理解与生成
海报提取为信息图

Prompt:将一张「THE BEES NEED YOU」公益海报提取为可用于生产的信息图,直接生成完整图片,不带任何占位框,清楚描述信息图中所有可见文字。
该任务同时考验模型的视觉理解能力(准确提取海报中的文字和版式信息)和生成能力(重新组织为清晰的信息图)。Uni-1 准确还原了文字内容、保持了正确的层级结构。而 GPT Image 1.5 混淆了文字层级,部分文字难以辨认;Nano Banana Pro 则未能完整呈现信息图的内容。
密集文字信息图

Prompt:生成一张关于{水钟(Clepsydra)与古代计时}的密集文字信息图,包含多个知识板块和精细插图。
该任务要求模型在单张图像中同时处理大量文字、图表和插图元素。Uni-1 在布局规划、文字清晰度和图文配合方面的表现优于其他模型。其生成的信息图在多个知识板块之间保持了视觉层级和逻辑连贯性。
平铺式信息图

Prompt:生成「种子到植物生命周期」(Seed-to-Plant Life Cycle)的平铺式信息图。
Uni-1 准确呈现了完整的生命周期阶段,每个阶段的插图和标注文字清晰可辨。值得注意的是,Uni-1 在处理「Young Plant」到「Mature Plant」的过渡阶段时,正确呈现了植物形态的渐变关系,展现了对生物学常识的理解。
参考图引导生成
多参考图场景合成(对比)

Prompt:给定 4 张参考图(两只猫的形象、一位真人照片、Luma AI 的 logo),合成一个会议讨论场景 —— 一只猫在展示关于 Luma AI 的幻灯片,另一只猫在旁听,同时融入真人照片和品牌 logo。
这一任务要求模型同时理解多张参考图的语义身份,并将它们合理地组织在一个新场景中。Uni-1 准确保留了每个参考对象的身份特征,并实现了合理的场景构图。相比之下,GPT Image 1.5 将参考图的原始图片直接嵌入了幻灯片区域,缺乏语义层面的融合;Nano Banana Pro 则未能有效利用全部参考信息。
5 张参考图场景合成
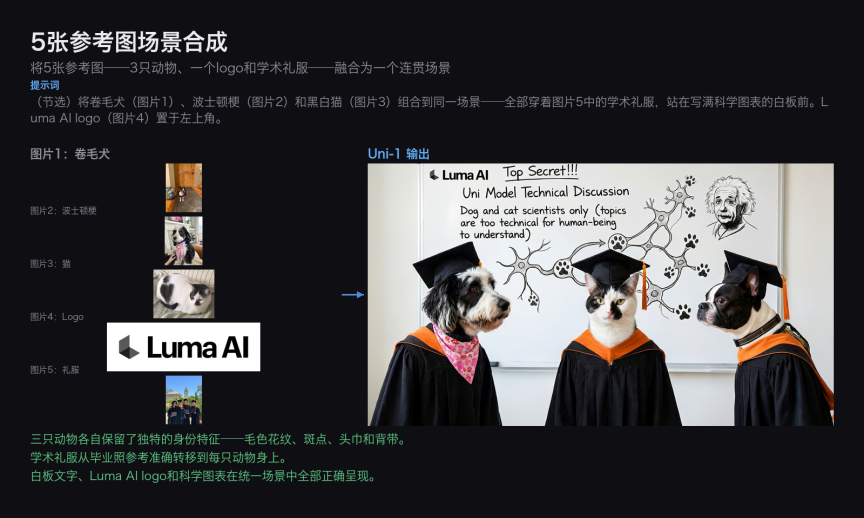
Prompt:将 5 张参考图 ——3 只动物、一个 logo 和学术毕业礼帽 —— 融合为一个连贯场景。
Uni-1 在处理 5 个不同参考源时,准确保留了每只动物各自的身份特征(毛色花纹、品种、头部轮廓),同时将学术氛围元素和品牌 logo 有机地融入了同一画面,展现了对多源参考信息的精确控制能力。
漫画角色参考(对比)
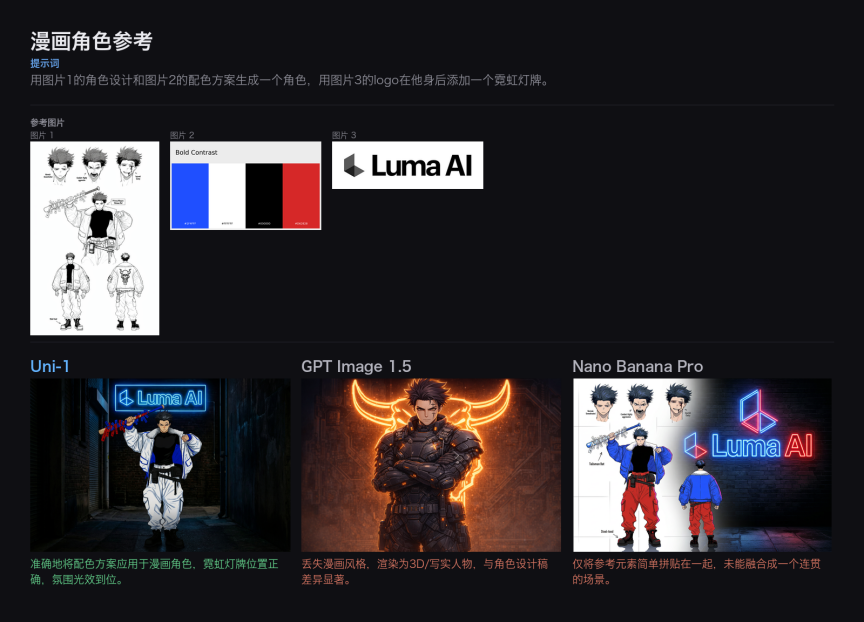
Prompt:融合角色设计图和配色方案生成一个漫画角色,同时将品牌 logo 自然地融入角色身上。
Uni-1 准确地将配色方案应用于二维漫画角色,保持了角色设计和 logo 的完整性。GPT Image 1.5 则未能区分 2D 和 3D 风格,生成了偏写实的 3D 人偶;Nano Banana Pro 未能准确识别角色设计图的意图。
草稿 + 材质→产品渲染

Prompt:将外套设计草稿与面料材质参考结合,生成写实的产品概念图。
Uni-1 准确地将面料的纹理质感 —— 灯芯绒的条纹、高级面料的光泽和垂坠感 —— 映射到了草稿的轮廓上,生成了具有商业可用度的产品渲染图。这类任务在时装设计和工业设计领域具有直接的应用价值。
草稿引导编辑与转化
草稿引导的照片编辑

Prompt:将手绘草稿叠加转化为写实编辑 —— 在一张猫的照片旁,以草稿为参考添加一只彩色蝴蝶。
Uni-1 将草稿的叠加转化为写实的照片编辑,保持了原始照片的细节完整性:猫的身份信息(毛色花纹、耳部形态)、环境(光线和背景)均未受影响,新增的蝴蝶自然融入了场景。
草稿转漫画

Prompt:将一张粗略草稿(猫站在书架上的多格漫画分镜)转化为精细漫画插图。
Uni-1 将草稿的分镜结构、人物动态和对话气泡位置完整地转化为专业漫画画面。所有细部信息均被保留并精细化:猫耳朵的弧度、卷烟缸的位置、书架上的书本排列,以及手机屏幕上显示的「911」文字,体现了模型对草稿语义的深层理解。
风格迁移与角色一致性
发型迁移至名画
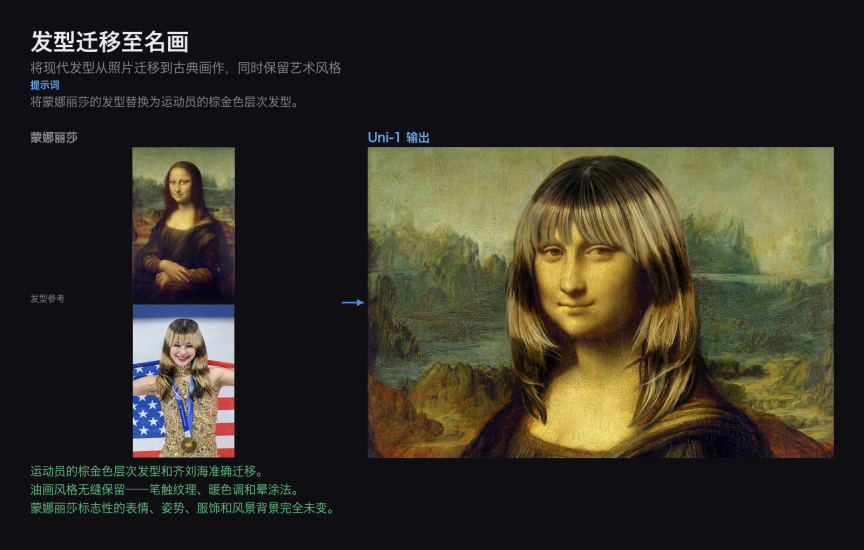
Prompt:将一位现代女性的棕金色层次发型迁移至蒙娜丽莎的画像上,同时保留文艺复兴油画的艺术风格。
该任务要求模型精确区分「需要迁移的元素」(发型的形态和色彩)和「需要保留的元素」(达・芬奇的晕涂法画风、背景、衣着、面部神态)。Uni-1 在两个维度上均表现出良好的控制力,生成结果在风格一致性和迁移准确性之间取得了平衡。
角色姿态迁移

Prompt:将真实人物的姿态迁移到虚构角色上,同时保留角色身份和环境设定。
参考图中一名男子在电梯间的半蹲姿势被迁移至一个穿宇航服的拟人化老鼠角色上,场景被重构为工业风格背景。Uni-1 在保持角色完整身份的同时 —— 鳞片状外衣、宇航服细节、耳机和口袋设计 —— 准确还原了参考姿态的关节角度和重心分布,体现了对人体动力学和角色设计语义的双重理解。
故事板生成:钢琴前的一生

Prompt:生成 6 帧故事板,展示同一角色从童年到老年在钢琴前的一生。
6 帧画面中角色的身份特征保持一致 —— 面部结构、肤色在不同年龄阶段平滑演变,同时钢琴、透视和画面风格保持稳定。从第 1 帧的小男孩到第 6 帧的大家庭合照,全程维持了叙事连贯性和时间逻辑。这种跨帧的长程角色一致性和时间推理能力,是当前图像模型面临的核心挑战之一。
多轮交互编辑
多轮编辑

Prompt:对一张泰迪熊照片进行连续三轮编辑 —— 第 1 轮「去掉面前这只熊」,第 2 轮 「背景上加一个黑色布帘」,第 3 轮「让它变成黑白照片的风格」。
多轮编辑是检验统一模型优势的典型场景。每一轮编辑都需要模型在执行新指令的同时,保持此前所有编辑结果的一致性和空间布局的稳定性。Uni-1 在三轮编辑中均精准执行了指令,且主体身份和空间关系在各轮之间保持了连贯。这正是统一架构的优势所在 —— 理解和生成在同一个模型内完成,不需要在不同模块间传递和对齐信息。
专业视觉任务
UV 贴图生成(对比)

Prompt:给定一人从不同角度拍摄的三张照片(正面、左侧、右侧),生成一张标准面部拓扑 / SMPL 体和布局的展开 UV 贴图。
UV 贴图生成是 3D 建模工作流中的关键环节。Uni-1 生成的 UV 贴图在面部特征对齐、左右对称性和肤色一致性方面均优于对比模型。GPT Image 1.5 遭遇了正脸和侧面贴图的不一致问题,而 Nano Banana Pro 则未能生成符合标准 UV 布局规范的结果。
技术路线:从「分治」到「统一」
在当前的视觉 AI 领域,图像理解(如视觉问答、物体检测、图像分割)和图像生成(如文生图、图像编辑、风格迁移)长期以来是两条独立的技术路线,各自使用不同的模型架构和训练范式。
这种「分治」策略虽然在各自领域取得了显著进展,但也带来了明显的局限:理解模型缺乏视觉想象力,生成模型缺乏深层语义理解,而需要两者协同的复杂任务(如多轮引导编辑、基于推理的图像合成)则往往需要拼接多个模型的复杂 pipeline。
Uni-1 的核心设计思路是将这两种能力统一在单一模型中,即在一个具备推理能力的模型基础上,同时赋予它视觉生成的能力。
具体而言,Uni-1 采用 decoder-only 自回归 Transformer 架构,将文本 token 和图像 token 表示在同一个交错序列(interleaved sequence)中。在这一框架下,文本和图像既可以作为输入条件,也可以作为生成输出,实现了对时间、空间和逻辑的联合建模。
这种架构选择带来了一个值得注意的发现:生成训练能够显著提升模型的细粒度理解能力。
换言之,当模型通过生成任务学会了「如何画出」一个场景后,它对场景的理解 —— 包括物体关系、空间布局、语义层次 —— 也随之增强。这与认知科学中关于「生成式心智模型」的假说不谋而合。
Uni-1 的一个关键技术特征是推理式生成(reasoning-informed generation)。在接收到复杂的图像合成指令后,模型并非直接进入像素生成阶段,而是首先进行结构化的内部推理:分解指令语义、规划画面构图、确定元素间的逻辑关系,然后再执行渲染。
在评估这一能力的 RISEBench 基准测试中,Uni-1 取得了当前最优成绩。RISEBench 覆盖四个推理维度:时间推理、因果推理、空间推理和逻辑推理,是目前评估生成模型推理能力最全面的基准之一。
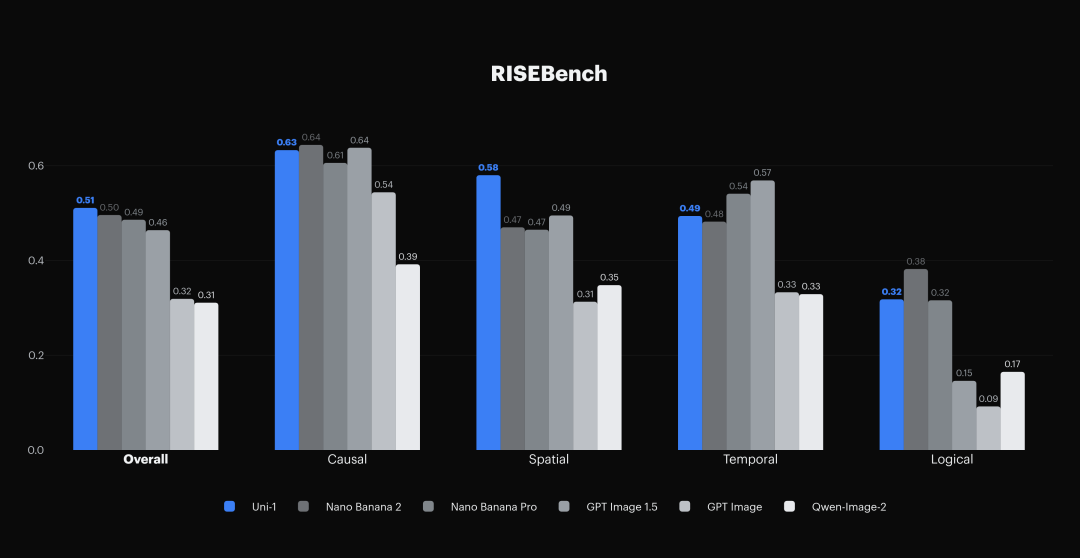
理解能力方面,在 ODinW-13 开放词汇密集检测基准上取得有竞争力的成绩。该基准传统上由专门的理解模型主导,Uni-1 作为统一模型在此基准上的表现,验证了「生成训练提升理解能力」这一技术假说的有效性。
起底背后团队
Uni-1 的核心研究团队不到 15 人,由两位华人学者领衔。
公司首席科学家宋佳铭,本科毕业于清华大学,博士就读于斯坦福大学,师从 Stefano Ermon。

他最广为人知的工作是发明了 DDIM—— 一种大幅加速扩散模型采样速度的算法,如今已被 Stable Diffusion、DALL・E 等主流图像生成系统广泛采用。
他在 ICLR 2022 上凭借这项工作拿到了 Outstanding Paper Award,引用量超过万次。
随后在 NVIDIA Research 工作了一段时间,再加入 Luma,先后主导了视频生成模型 Dream Machine 和文生 3D 模型 Genie 的训练工作,Uni-1 是他带队推进的最新成果。
另一位核心研究负责人 William Shen(沈博魁) 同样是斯坦福计算机科学博士,师从 Silvio Savarese 和 Leonidas Guibas,本科也在斯坦福完成,毕业时获得系里荣誉和全校杰出毕业生称号。

他的研究横跨计算机视觉、机器人、图形学和生成模型,曾获 CVPR Best Paper Award 和 RSS Best Student Paper Award 提名。

此外,沈博魁还曾作为 CEO 与联合创始人创建 Apparate Labs,并主导推出一款,而后被Luma AI收购。
这两个人的履历,放在任何一家顶级实验室里都不会显得突兀。但他们选择了一家初创公司,选择了在资源有限的条件下做一件他们认为正确的事。
结语
AI 领域从来不缺大力出奇迹的故事。
谷歌、OpenAI、Meta,每一家都在用巨量资源堆砌模型的上限,这是小公司难以复制的路径。
然而 Luma 有另一套打法。在正确的方向上,用更聪明的架构设计,做出超越规模优势的结果。
当然,一张基准测试榜单只是起点。Uni-1 目前还在向合作伙伴定向开放,距离大规模商业化还有距离。谷歌和 OpenAI 的迭代速度也从未放慢,Nano Banana 2 之后,下一个版本或许已经在路上了。
Uni-1 也只是 Luma 迈向统一多模态智能的第一步,后续统一框架将从静态图像扩展到视频、语音和交互式世界模拟等模态,最终构建能够在一个连续流中完成「看、说、推理、想象」的多模态系统。
在这个从来不缺大玩家的赛场上,Uni-1 证明了以小博大的可能性,小规模精英团队在前沿 AI 研究中仍具有竞争力。
