FlashAttention-4在Blackwell GPU上实现矩阵乘法级速度,显著提升大模型Attention性能。
原文标题:FlashAttention-4正式发布:算法流水线大改,矩阵乘法级速度
原文作者:机器之心
冷月清谈:
怜星夜思:
2、FlashAttention-4中使用CuTe-DSL有什么优势?为什么作者会感到“莫名兴奋”?
3、FlashAttention-4的性能提升对大语言模型的未来发展有哪些潜在影响?
原文内容
经过一年的努力,FlashAttention-4 终于正式上线了。
近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。
FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!

当前,Tensor Core 的速度现在非常快,以至于注意力前向传播的瓶颈呈指数级增长,而注意力后向传播的瓶颈是共享内存带宽。
重新设计的算法中包含一些旨在克服这些瓶颈的机制,包括使用多项式进行指数模拟,新的在线 softmax 可以避免 90% 的 softmax 重新缩放,2CTA MMA 指令允许两个线程块共享操作数以减少 smem 流量等。

-
论文地址:https://github.com/Dao-AILab/flash-attention/blob/main/assets/fa4_paper.pdf
-
代码链接:https://github.com/Dao-AILab/flash-attention
接下来,就来详细了解一下。
硬件趋势:不对称的硬件扩展
长期以来,Attention 作为无处不在的 Transformer 架构中的核心层,一直是大语言模型和长上下文应用的性能瓶颈。
此前 FlashAttention-3 通过异步执行和 warp 专门化对 Attention 进行了优化,但其主要针对的是 Hopper GPU(H100)架构。
然而,AI 行业已经迅速转向部署 Blackwell 架构系统,例如 B200 和 GB200。而像 Blackwell GPU 这样的现代加速器延续了一种趋势:硬件的非对称扩展(asymmetric hardware scaling)。
在这种趋势下,张量核心(Tensor Core)的吞吐量增长速度远快于其他硬件资源,像是共享内存带宽、用于指数运算等超越函数运算的特殊函数单元(SFU),以及通用整数与浮点 ALU……
举个例子,从 Hopper H100 到 Blackwell B200,BF16 张量核心吞吐量增加了 2.25 倍(从 1 到 2.25PFLOPs),但 SFU 数量和共享内存带宽基本保持不变。
这种扩展不对称性对像 Attention 这样的复杂 kernel 优化产生了深远影响。
具体来看,Attention 的核心包含两个通用矩阵乘法(GEMM):
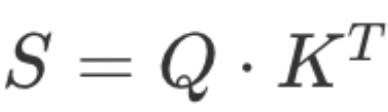

中间夹着 softmax,但在真实实践中,Attention 还涉及大量辅助工作,比如数据搬运、同步、数据布局转换、元素级运算、调度、mask 处理等。
传统的观点认为,Attention 的性能完全由 GEMM 的速度决定。然而,对 B200 进行「速度与馈送」分析显示:主要的瓶颈不在于张量核心,而是:
-
前向传播中用于 Softmax 指数运算的 SFU 单元;
-
反向传播中的共享内存流量,受 shared memory bandwidth 限制。
为此,团队推出 FlashAttention-4,一种算法 + kernel 的协同设计,核心目标在于,通过最大化矩阵乘法与其他瓶颈资源之间的重叠,在 B200(BF16)上,最高可达 1605TFLOPs/s(71% 的利用率),比 cuDNN 9.13 快 1.3 倍,比 Triton 快 2.7 倍。
协同设计的核心思路如下:
-
新型流水线:为前向和反向传播分别设计了新的软件流水线,利用 Blackwell 的全异步 MMA 和更大分块(Tile)尺寸,最大化 Tensor Core 计算、softmax 计算以及内存操作之间的重叠执行;
-
前向传播 (FWD):在 FMA 单元上通过多项式近似实现指数函数的软件仿真,以提升指数计算吞吐量;同时引入条件式 softmax 重缩放(conditional softmax rescaling),跳过不必要的重缩放操作,从而缓解 SFU 瓶颈;
-
反向传播 (BWD):利用张量内存 (TMEM) 存储中间结果,以缓解共享内存流量压力;同时,结合 Blackwell 新增的 2-CTA MMA 模式,进一步降低共享内存访问,并将 atomic reduction 次数减少一半;此外,还支持确定性执行模式,以实现可复现训练;
-
调度优化:引入新的 tile 调度器,解决因果掩码和变长序列导致的负载不均衡。
Blackwell 的新硬件特性
张量内存(TMEM):在 B200 上,148 个 SM(流式多处理器)中的每一个都配备了 256 KB 的 TMEM,与 Tensor Core 直接连接,用于 warp 同步的中间结果存储。
完全异步的第五代张量核心:指令 tcgen05.mma 支持异步执行,并将累加结果存储在 TMEM 中。对于 BF16 和 FP16,单个 CTA 可使用的最大 UMMA tile 为 128×256×16,约为 Hopper 架构中最大 WGMMA 原子块的 2 倍。UMMA 由单个线程发起,从而减轻寄存器压力,使得在不出现 Hopper warpgroup MMA 那种寄存器溢出问题的情况下,可以更容易地使用更大的 tile 和更深的流水线。
此外,这也使 warp 专门化更具可行性:部分 warp 负责搬运 tile,另一些 warp 负责发起 MMA,从而实现矩阵乘加运算与 softmax 计算以及内存访问的重叠执行。tcgen05.mma 还可以直接从 TMEM 中读取操作数 A。
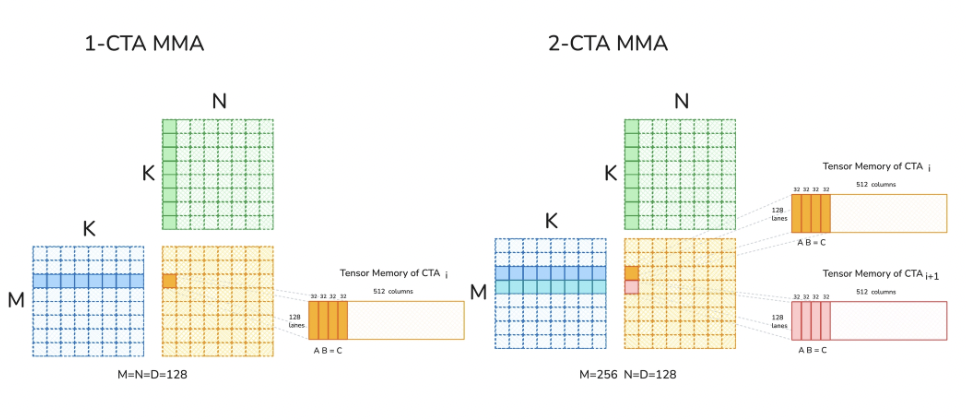
2-CTA MMA:Blackwell 支持在同一 cluster 中由一对 CTA 共同执行一个 UMMA 运算,并跨越两个 CTA 的 TMEM。由 leader CTA 中的一个线程发起 MMA,但在执行期间两个 CTA 都必须保持活跃。通过在这对 CTA 之间拆分 M 和 N 维度,可以将 MMA 的 tile 尺寸扩展到 256×256×16,从而减少冗余数据传输并降低每个 CTA 的资源占用。在一个 kernel 中,CTA 组大小(1 或 2)在 TMEM 操作和 Tensor Core 运算之间必须保持一致。
编程语言与框架:CuTe-DSL
FlashAttention-4(FA4)完全使用 CuTe-DSL 实现,这是 CUTLASS 提供的 Python kernel DSL。
Kernel 代码使用 Python 编写,随后 DSL 会将其降级(lower 为 PTX,再由 CUDA 工具链编译为 GPU 机器代码。
该编程模型在抽象层面与 CuTe / CUTLASS 保持一致,同时提供 PTX 级别的 escape hatch(底层控制接口)。与使用 C++ 模板相比,这种方式可以将编译时间缩短约 20–30 倍。
对此,Tri Dao 更是在 X 上发帖称感到「莫名兴奋」,这意味着,安装 /「编译」现在只需几秒钟,而不是几分钟 / 几小时。

Attention 性能基准测试
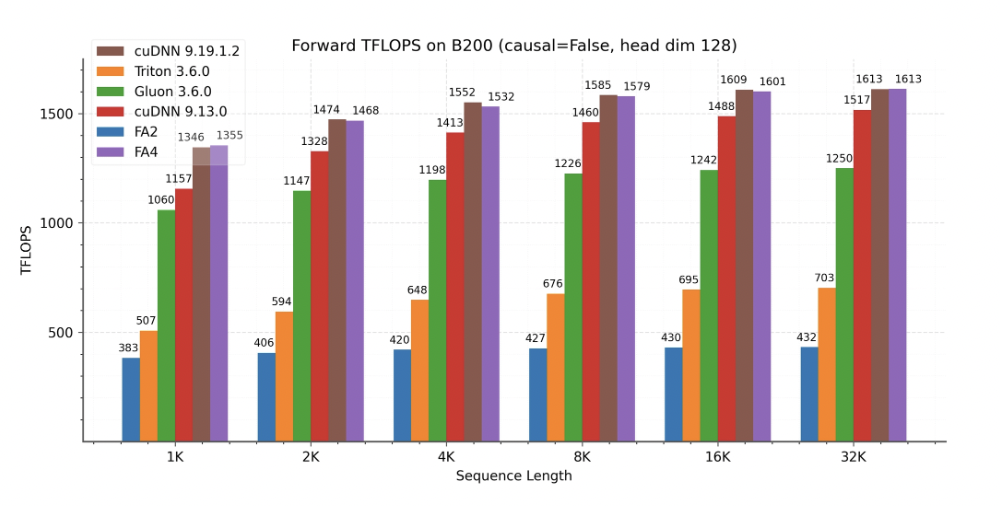
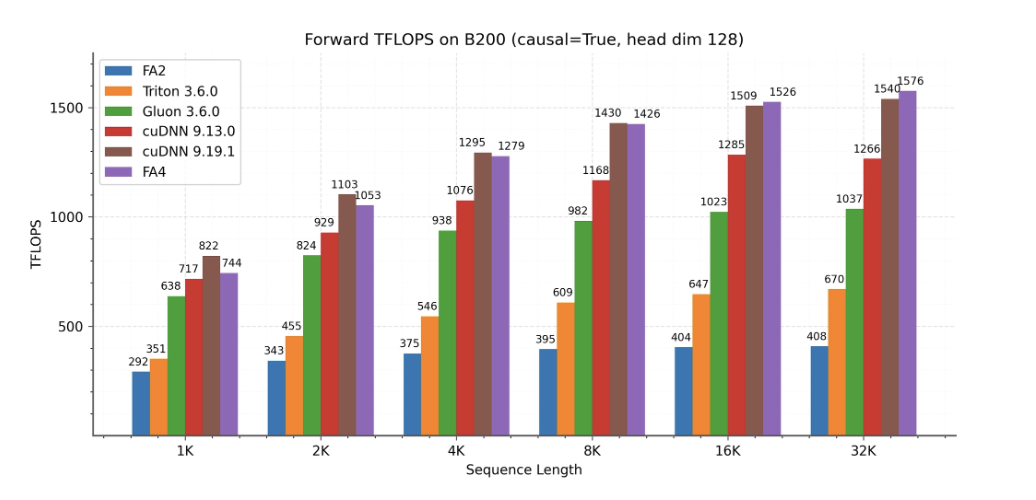
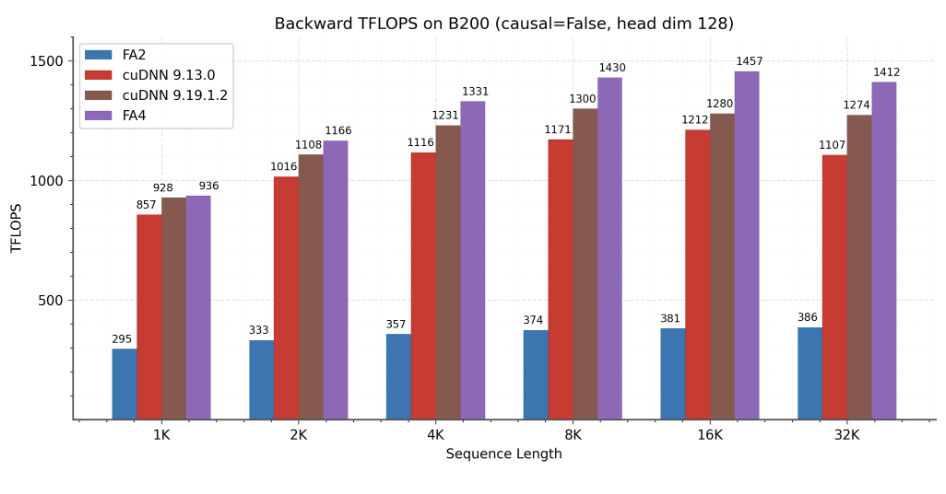
团队展示了 FlashAttention-4 在 B200(BF16)上的性能结果,并将其与 FlashAttention-2 以及 Triton、Gluon 和 cuDNN 的实现进行了对比。
结果显示:
-
前向传播(forward pass):FlashAttention-4 比 cuDNN 9.13 快 1.1–1.3 倍,比 Triton 实现快 2.1–2.7 倍。
-
反向传播(backward pass):在长序列长度场景下,FlashAttention-4 的表现始终优于其他基准模型。

而 FlashAttention-4 一经发布,也引起了大家的热议。
Pytorch 官方宣布 FlexAttention 现已支持 FlashAttention-4 后端。

Pytorch 表示,很长一段时间以来,FlexAttention 让研究人员能够快速原型化各种自定义 Attention 变体,目前已有 1000 多个代码仓库采用,并有数十篇论文对其进行了引用。
然而,用户常常会遇到性能瓶颈,直到 FlashAttention-4 的出现。
如今,他们已在 Hopper 和 Blackwell GPU 上为 FlexAttention 增加了 FlashAttention-4 后端。PyTorch 现在可以自动生成 CuTeDSL 的 score/mask 修改代码,并通过 JIT 编译为自定义 Attention 变体实例化 FlashAttention-4。
结果显示,在算力受限的工作负载下,相比 Triton,仍可实现 1.2 倍到 3.2 倍的性能提升。研究人员再也不必在「灵活性」和「高性能」之间做单选题。
一位网友则认为,「FlashAttention-4 是一个里程碑。」在 Blackwell 架构上,Attention 已经能够达到接近矩阵乘法(matmul)速度,这意味着计算瓶颈将完全转移到内存与通信上。约 1600TFLOPs 的 Attention 性能堪称惊人 —— 相比 FlashAttention-3 提升了 2–3 倍。「这将直接惠及所有前沿大模型。」因为,更快的 Attention 意味着更长的有效上下文窗口、更低的推理成本、更强的规模化推理能力……

更多内容,可查看论文原文获取!
参考链接:
https://x.com/tri_dao/status/2029569881151263082
https://tridao.me/blog/2026/flash4/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com