影溯开源InSpatio-WorldFM,实时交互3D世界模型。突破2D限制,低算力需求,或为空间智能带来新突破。
原文标题:李飞飞50亿美金赛道被开源!浙大教授章国锋带队创业,打造无限时长实时3D世界模型
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到InSpatio-WorldFM在消费级GPU上就能实现实时推理,这对于空间智能的普及有什么意义?会催生哪些新的应用场景?
3、影溯选择开源 InSpatio-WorldFM,你认为这种策略对公司自身和整个行业会带来什么影响?
原文内容
AI 领域最前沿的方向「世界模型」,正在出现一场革命。
互联网上,OpenClaw 的「赛博龙虾」在虚拟数字世界中灵活穿梭,无所不能;现实中,具身机器人却依然受困于试验场的围栏,难以迈向复杂的物理空间。这道横跨虚拟与现实的鸿沟,本质上是智能体对空间智能(Spatial Intelligence)感知的缺失。
2024 年,被誉为「AI 教母」的李飞飞教授创立 World Labs 强势入局,正式点燃了空间智能这一千亿级赛道的全球战火。就在不久前,该公司完成了最新一轮融资,估值直接飙升至 50 亿美元。RTFM(实时帧模型)是 World Labs 去年 10 月发布的实时生成式世界模型,其核心在于构建一个拥有永久一致性(Persistence)的 3D 场景,让智能体不仅能「看见」空间,更能真正理解并实时交互物理世界。
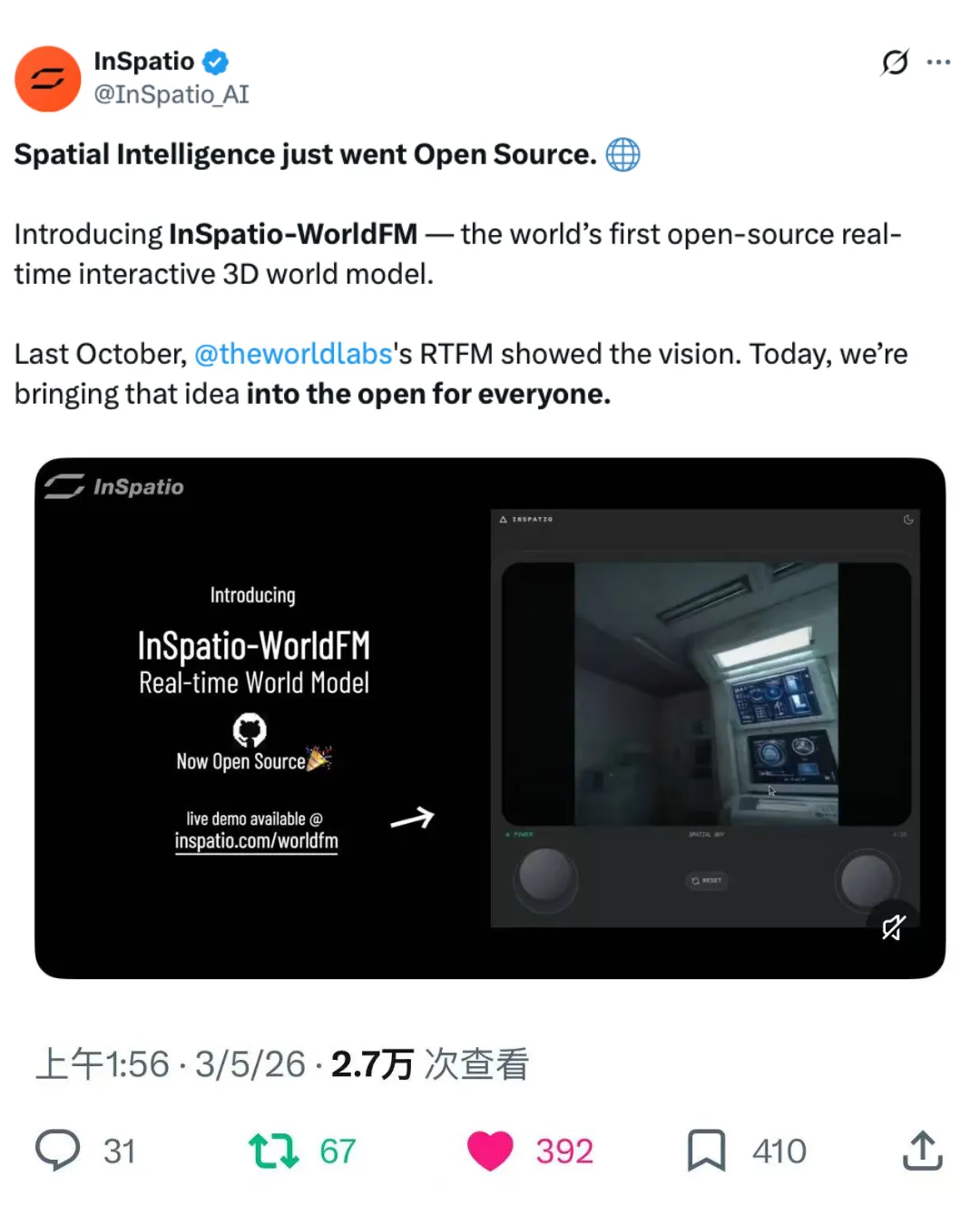
在 50 亿美元估值神话的背后,这一空间智能的最新高地正被国内创业公司攻克并推向产业纵深。近日,影溯(InSpatio)正式发布并开源了其实时帧生成模型 InSpatio-WorldFM,一个实时交互的 3D 世界模型。这标志着中国团队在空间智能底层技术上取得了奠基性突破,而且以开放的姿态,正成为推动 AI 从虚拟屏幕走向物理现实的关键破局者。
-
InSpatio-WorldFM 项目主页:https://inspatio.github.io/worldfm/
-
模型 GitHub:https://github.com/inspatio/worldfm
-
模型在线体验:http://www.inspatio.com/worldfm
InSpatio-WorldFM 的发布和开源不仅是对全球顶尖技术路线的快速响应,更是中国团队在空间智能领域的独立思考。由浙江大学计算机辅助设计与图形系统全国重点实验室教授、国家杰青章国锋博士领衔,影溯凭借在 3D 视觉和空间计算领域深耕 20 多年的底蕴,跳出了单纯依赖极稀缺「原生 3D 数据」的传统路径,通过独创的「数据升维」与「几何约束」策略,成功激活了互联网海量 2D 存量视频数据中蕴含的 3D 空间知识。
这一技术路径精准破解了困扰行业已久的「高质量、规模化 3D 数据贫矿」局限,将海量 2D 存量数据高效转化为驱动 3D 世界模型的高维原动力。
InSpatio-WorldFM 能够高效地进行多视角一致的空间推理,并支持实时交互式探索。它的效果是这样的:
该项目发布后迅速获得硅谷多位 AI 领域意见领袖转发关注,在线 Demo 访问量短时间内激增,一度出现排队和访问拥堵。
得益于 3D 的模型机制,其生成的虚拟世界有高度的一致性,模型生成的场景在空间几何与光照与物理规律上非常稳定,无限时长推理不会出现遗忘和衰退。
值得关注的是,相比以往的世界模型,InSpatio-WorldFM 对于算力的需求很低。影溯的目标是让实时的空间推理能在消费级 GPU 上实现,将空间智能从数据中心扩展到边缘设备 —— 甚至在单块 RTX 4090 GPU 上就能实现实时的推理,这就一下子打开了商业价值的想象空间。
生成的空间还支持整体一致性编辑 —— 不再是对单个物体或局部区域的零散修改,而是在保持几何结构、光照关系、材质属性与物理逻辑全局一致的前提下,进行跨视角、跨区域的统一调整。
比如从这样:
到这样:
无论是整体风格迁移、空间布局重构,光照材质,系统都能确保改动在所有视角与后续生成结果中保持一致,避免「前后打架」或「视角错位」。
换句话说,它编辑的不是一帧图像,而是一个可控、连贯、具物理约束的三维世界本体。
技术路线
维度突破,构建原生 3D
目前,不论是科技巨头还是创业公司都在加速发力世界模型。
图灵奖得主 Yann LeCun 曾多次表示,仅靠预测下一个 token 的生成式模型无法真正做到理解现实世界,世界模型将会是 AI 下一次技术突破的大方向。然而当前绝大多数主流的世界模型、图像生成模型(如谷歌的 Genie 3、OpenAI 的 Sora)进行 2D 像素概率预测的本质,并不符合技术前进的需要。
目前绝大多数的世界模型,如谷歌的 Genie3、英伟达 Cosmos、Runway GWM-1、Lingbo-World、PixVerse R1 等,本质上都是基于 2D 的视频生成模型,其每个时刻的空间状态都是由平面的 2D 图像进行表达。但物理世界是 3D 的空间,AI 要和物理世界交互,空间状态的表达也应该是 3D 的。
影溯所走的技术路线在于善用「第一性原理」,不再执着于逐像素地生成画面,而是构建原生的 3D 世界。
这意味着需要走一条更具挑战的路,让模型学会对真实世界传感器数据进行抽象建模,过滤掉不可预测的噪声信息,并在更高层次的表征空间中进行预测与推理。
对此,影溯没有选择从零开始学习物理常识,而是将互联网海量 2D 存量视频数据中蕴含的 3D 空间知识成功激活。通过精确控制,他们反向抽取出其中蕴含的三维几何与物理规律。在其生成的 3D 世界中,人或 AI 也可以自由地行动,不必担心会出现不可靠的细节。
正是基于独特的 3D 技术路线,影溯的世界模型可以有效解决目前 AIGC 工具「盲盒抽卡」的痛点,不仅能在实时生成的场景自由漫游,而且支持将视频中的动态前景无缝转移到另一个空间环境中,并且能严格保证转移后的前景与新背景在空间几何、光照、物理规则上的高度一致性。 一次生成,精准可控,彻底告别反复重试的算力浪费。
可以看出,影溯的模型在背景变换与运镜控制上,展现出卓越的像素级前景锁定能力和精准运镜控制,其主体一致性与运镜稳定性已超越当前主流的世界模型与视频生成模型。尤为突出的是,即使背景完全变换、光线随新环境自然适配,前景主体的光照依然能与新背景保持高度一致,细节与结构毫发无伤、纹丝不动。
影溯团队透露,其世界模型的训练仅仅动用了 100 张卡的算力规模,远低于现在视频模型训练所需要的算力。当大厂还在用万张显卡暴力猜测「下一个 2D 像素是什么」时,影溯直接在底层构建了物理引擎的 3D 骨架。计算物理场,远比穷举像素更省算力。
具体来说,影溯这次开源的 InSpatio-WorldFM 具备三大特性:
突破 2D 限制:赋予空间智能一致性
在尝试当前的先进 AI 视频生成工具时,你一定遇到过这样的尴尬:镜头一转,原本的人物变形了,背景里的建筑凭空消失或发生了扭曲。这种现象的本质,是因为基于 2D 的 AI 模型只是在进行像素级的二维变化预测,它们并不懂什么是真正的物理世界。
InSpatio-WorldFM 抛弃了纯 2D 的学习路径,将「三维多视图一致性」作为内容生成的核心约束机制。无论是在预计算阶段还是实时推理中,模型都被强制要求理解并保持 3D 空间结构的连贯性。
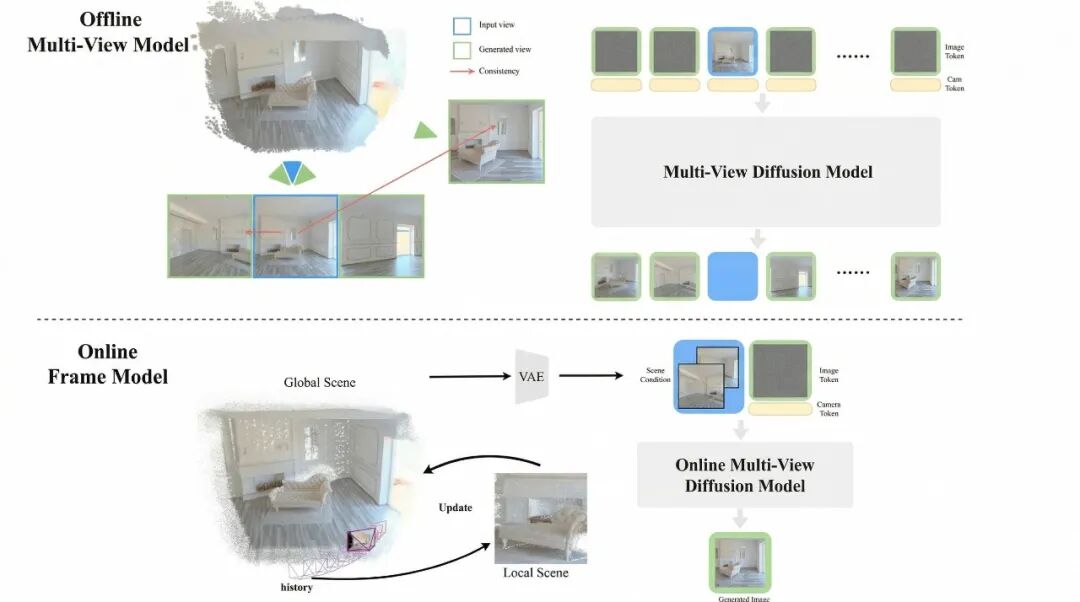
多视一致的生成模型
于是在 InSpatio-WorldFM 生成的世界里,物体不仅具备真实的物理体积,而且不会随时间发生漂移或形变。它赋予了空间智能最稀缺的品质 —— 物理级的持久一致性。
InSpatio-WorldFM 在构建 3D 世界时,可以保持生成的场景在时空上的持久一致性,无论在这个虚拟空间里转多久,场景都不会像其他 AI 生成的视频那样崩坏变形,这对影视制作、游戏资产和具身智能来说是杀手级特性,证明了模型不是在「画画」,而是在「计算物理场」。由此生成的虚拟世界不再只是炫酷的视频,而是直接为未来的机器人生准备的数以万计的虚拟训练场。
这种 3D 机制突破了 2D 视频模型的极限时空记忆,解决了世界模型一直以来头疼的「长时序遗忘」和「空间几何崩塌」问题。
实现高效率
InSpatio-WorldFM 构建了轻量化与高效率的框架。通过基于帧的架构,辅以模型蒸馏和推理优化技术,影溯成功地压缩了庞大的空间计算需求。影溯的目标是:在消费级 GPU 上实现实时的空间推理。这不仅能让实时交互成为可能,更意味着空间智能将彻底走出数据中心,真正被部署到从机器人到 XR 眼镜的各类端侧设备中。
高效率低延迟的实时生成
显式锚点 + 隐式记忆:实现空间记忆
空间智能的终极考验在于「记忆」:如果一个机器人在转头的瞬间,就忘记了身后仓库的布局和货架的位置,那么高阶规划和自主导航就无从谈起。为了解决这一痛点,InSpatio-WorldFM 创新地采用了一种「显式锚点 + 隐式记忆」混合架构设计。
在该模型中,团队利用前沿的前馈式重建技术生成显式的物理空间锚点,为模型提供稳固的 3D 结构支撑。与此同时,模型会将参考帧作为生成模型内部的隐式记忆。
这就像是让 AI 拥有了「三维坐标体系」,不论镜头怎么转,生成场景的内容都不会发生漂移和变化。
这种设计让 AI 不仅能像神经元一样灵活思考,还能拥有几何级别的严密记忆,确保了 AI 即使在跨越复杂视点、经历长时间推移后,依然能保持稳定、高效且可扩展的空间推理能力。
在以往,视频模型由于空间记忆限制,随着时长延长,复杂度指数级上升,因此 Genie3 等世界模型能够生成的时长有限。InSpatio-WorldFM 理论上生成的时长则是无限的。
除此以外,在训练数据上,影溯团队利用自身在 SLAM(同步定位与建图)、NeRF(神经辐射场)和 3DGS 等领域的技术积累,能够极低成本地合成海量高质量的 3D 训练数据,从而打破了 3D 训练数据极度匮乏的行业瓶颈。
正是得益于这些架构的创新与底层数据的积累,从目前的一系列 demo 中可以看出,InSpatio-WorldFM 呈现出了很强的「工程可用性」。
这种创新与实用的并重,让我们不得不把目光转向影溯的核心团队。
顶尖团队下场创业
等了 20 年的「3D 时刻」
训练 3D 世界模型是一个极具挑战的任务,互联网上存在海量的 2D 视频数据,但 3D 数据极其匮乏,另一方面,精通 3D 视觉与图形学的人才长期以来极为稀缺。
在通往空间智能的 AI 终极赛道上,影溯选择硬核的原生 3D 路线,其底气源自核心团队在 3D 领域 20 多年的技术积淀。
影溯的班底堪称国内空间计算领域「梦之队」,由浙江大学计算机辅助设计与图形系统全国重点实验室(图形学领域全球排名第三,仅次于斯坦福和 MIT)与原商汤科技 3D 视觉与混合现实团队的顶尖专家组成:
其中创始人章国锋为浙江大学求是特聘教授、国家杰青,前商汤数字空间事业群首席科学家。作为国内空间计算领域的领军人物,他在 SLAM(同步定位与建图)和 3D 重建领域深耕已超过 20 年,是国内空间计算领域公认的引领者。
联合创始人兼 CTO 刘浩敏是前商汤研究总监、浙大博士。他的一个重要成就是:曾主导实现了业内首个手机端无标志 SLAM 商业系统,比苹果的 ARKit 和谷歌的 ARCore 早了整整 3 年。
随着生成式 AI 的爆发,3D 空间的重建与生成开始合流。影溯团队敏锐地捕捉到了这个历史性的「3D 时刻」,于 2025 年 7 月下场创业,致力于打造属于中国的 3D 世界模型。
在这场世界模型的狂欢中,影溯的目标是让 AI 真正理解 3D 物理世界中的空间几何、物理规则和因果关系,利用 3D 视觉和图形学的底座,来实现 AI 的升维,通向真正的世界模型。
基于团队 20 多年的空间计算 / 智能的技术积累,影溯已经构建了一个三维场景重建与生成平台,具备大尺度真实场景的快速扫描与重建生成能力,提供了从数据采集、场景生成、场景编辑到应用开发的完整工具链,可通过无人机、全景相机甚至手机拍摄实现低成本纯视觉三维重建和生成。
影溯构建了一套行业内独有的「3D 数据升维引擎」:不盲目耗费海量算力,而是从现有的海量视频抽取 3D 知识,用成熟的几何约束工具链打破 3D 数据荒。这是大厂短期内拿算力也砸不出来的能力,也是影溯的核心商业壁垒。
长期 3D 视觉和图形学算法的积累、成熟的工程化工具链,构成了影溯难以被轻易复制的技术护城河。他们用着相对少的资源,撬动了空间智能的未来。
结语
与 World Labs 选择闭源的商业路径不同,影溯从一开始便确立了开源共建的核心战略,认为空间智能的未来不应由单一企业定义,而应由全球开发者共同创造。
InSpatio-WorldFM 推出之后,为了支持全球 AI 社区的共建,影溯团队下一步计划提供更丰富的技术细节。同时,扩展版模型,以及支持与动态世界实时交互的体验应用也将在不久后推出。
随着 InSpatio-WorldFM 等开源空间智能模型的推出,生成模型、具身智能体和现实世界的机器人现在站在了全新的起跑线上。
AI 的下一个故事,才刚刚开始。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com