《AI工程:大模型应用开发实战》强调AI工程的重要性,指引从炼丹时代迈向系统、流程和可靠性为核心的施工时代,在AI“下半场”中赢得竞争优势。
原文标题:这可能是我近两年读过最重要的一本 AI 书!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、书中将提示工程、RAG 和微调比作核心能力构建的“三部曲”,你认为在实际项目中,应该如何根据不同的应用场景选择合适的技术方案?
3、书中提到“AI 的下半场”是关于如何定义正确的问题,你认为对于企业来说,如何找到那些真正有价值、能够解决实际痛点的 AI 应用场景?
原文内容
犹记得谷歌正式发布 Gemini 2.0 模型的时候,技术报告中的各项基准测试数据令人眩目,当人们觉得这是一个 STOA (state of the art,最先进的) 大模型时,引发用户阵阵欢呼。
然而,仅仅一段时间以后,首批尝试在业务中集成该模型的企业开发者们却开始感受到理想与现实之间的温差——高昂的 API 调用成本、难以准确预测的响应时间、推理成本、特定业务场景下让人烦恼的智能幻觉,以及将模型能力融入现有 workflow 中的重重阻碍。
下图就体现了在不同模型体量下的推理成本的变化对比图,明显看出模型性能变强会带来巨大的 Token 成本:
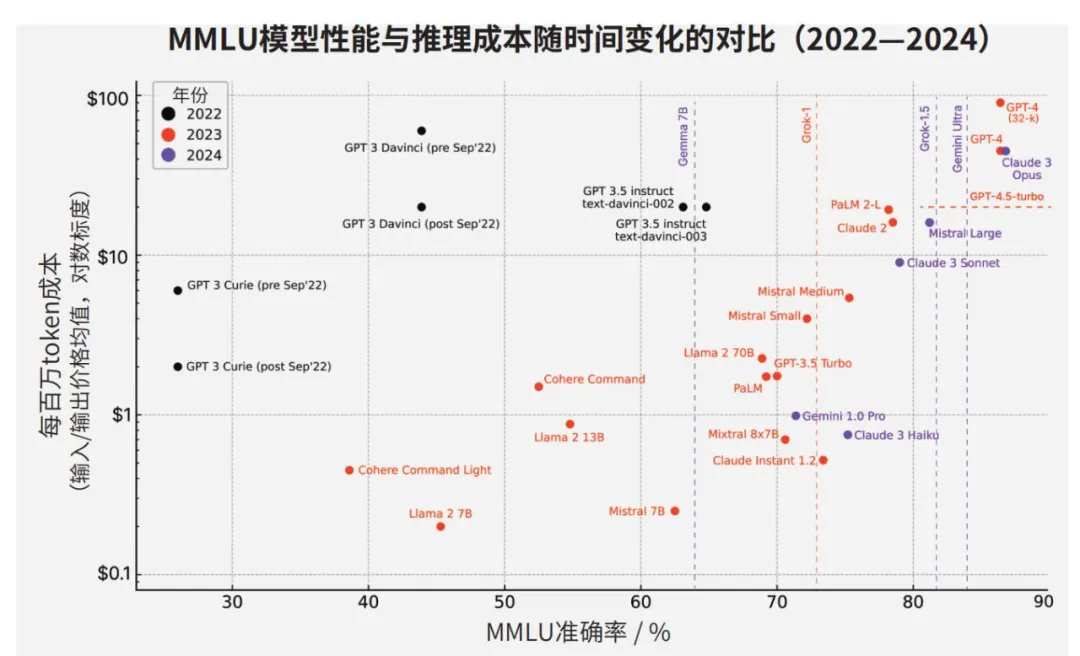
这种现象很是普遍,想必很多工程师在集成开源 Deepseek 模型的时候就有遇到过,这几乎是大模型问世以来的周期性问题:每一次技术突破带来的疯狂 crazy,总会在工程落地阶段遭遇理性的冷却,让人不禁唏嘘感叹一番。
而正在此时,如果你翻开《AI工程:大模型应用开发实战》一书时,你会眼前一亮。因为你感受到的并非一本浮于表面的技术颂歌,而是一份难得的可依据实践的工程地图。指引我们从炼丹时代,迈向一个以系统、流程和可靠性为核心的施工时代,在实战中辅助我们拥有解决问题的 AI 工程化能力。
01
AI 发展观的必要转向
过去几年里,围绕大模型的公共叙事往往笼罩着一层神话色彩。媒体和研究所热衷于报道参数量的跃升、benchmark 的刷新,以及模型在某些特定任务上超越人类的表现(当然有一些场景下还是我们人类厉害)。
这种叙事催生了一种“万物是模型,模型即一切”的迷信思维,仿佛只要选择了 STOA 模型,一切工程难题便会迎刃而解。
我们不得不承认大模型的强大能力,只是故事的开始,而非终点。如果将预训练大模型比作一块拥有无限潜能的璞玉,而 AI 工程则是将其雕琢成可用、可靠、可扩展之器的整套工艺。
这种视角的转换至关重要。它意味着:从一味追求模型的智能程度,转向全面考量系统的可用性(是否能稳定完成任务)、可靠性(输出是否一致、可控)、经济性(成本是否可持续)和可维护性(是否能随业务迭代)。
全书的各章节内容处处体现了这种工程化思维。它没有急于展示华丽的模型应用案例,手把手 Coding 让你叹服。而是一步步引导读者理解基础模型、数据准备、微调、模型服务化部署、性能监控与持续迭代的完整生命周期。这种全链路的视野,正是当前许多渴望拥抱 AI 的企业所最缺乏的。
02
应用开发生命周期全纪实
全书结构呈现为一个清晰的工程闭环,精准模拟了 AI 应用从构想到成熟的全生命周期:
第一阶段:认知与战略奠基(第1-2章):梳理技术演进脉络并界定应用场景,确保项目始于正确的战略预期。随即深入剖析基础模型的内在原理,为后续工程实践奠定坚实的理论根基。
第二阶段:科学评估与理性选型(第3-4章):在模型爆炸的时代,本书提供了抵御噪音的决策框架。它不仅解构了评估方法论从传统指标到“AI裁判”的演进,更关键的是,将其落地为一套可操作的模型选择工作流,将性能、成本、延迟等多维度标准转化为科学的决策树。
第三阶段:核心能力构筑三部曲(第5-7章):提示工程,作为最敏捷的交互层,强调工业化实践与安全防御,视提示词为可维护、需版本管理的生产代码。
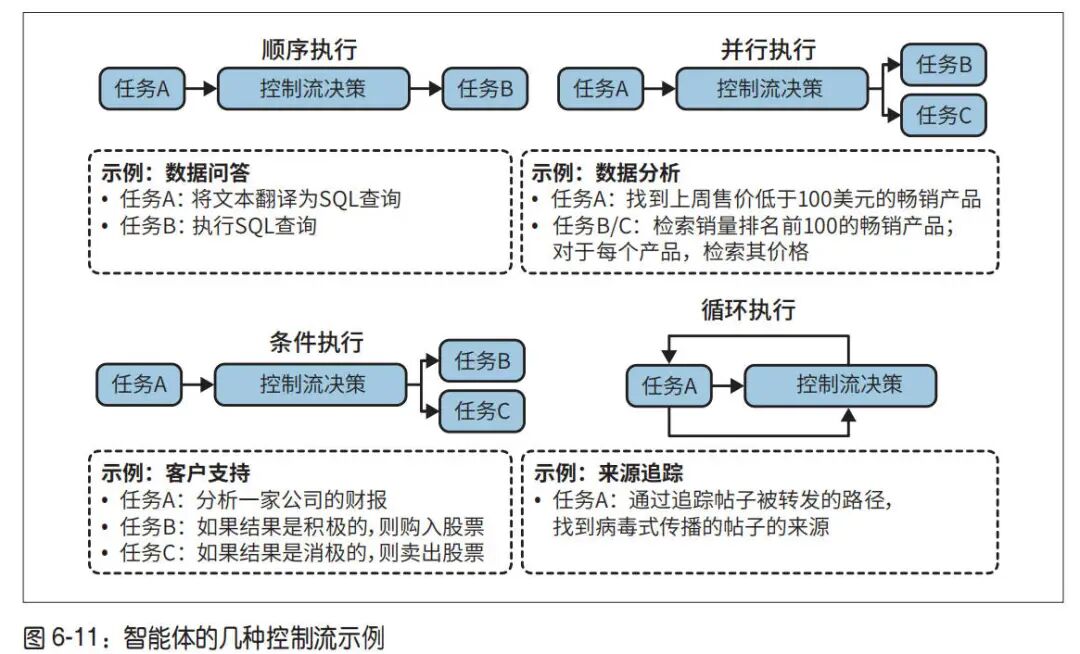
RAG 与智能体,构建连接模型与外部知识/行动的核心扩展层,实现复杂应用逻辑。本部分作者清晰的介绍了几种智能体的控制流程,且指出具有非顺序控制流的计划更难生成,也更难翻译为可执行命令。
微调,作为终极深度控制手段,理性分析其适用边界,并详解内存优化与高效微调技术,使其从黑魔法变为可规划的工程选项。
第四阶段:数据集的工程化(第 8-9 章):数据集工程,系统化构建高质量数据流水线,强调 AI 驱动的数据合成,这是模型持续迭代的燃料。推理优化,直面商业化核心制约,提供从模型压缩到服务部署的整套性能与成本优化工具箱。
第五阶段:系统整合与持续进化(第10章):全书高点在于将前述所有组件集成为有机整体。通过架构设计(上下文、缓存、路由、监控)实现系统的健壮与可观测,并通过用户反馈闭环确保产品持续迭代。
03
在技术洪流中确定方向
大模型的惊人能力,是一个伟大故事的序章。而真正波澜壮阔的主线,是如何将这些能力安全、可靠、经济、规模化地编织进人类社会的生产与生活中,而真正的带来巨大的价值。
开源与闭源模型每周都在刷新榜单,而我们需要明白,这本书它不教读者某个特定框架(如 LangChain)的瞬息万变的 API,而是传授:
如何思考:在面对一个具体问题时,应沿着“需求→评估→(提示/RAG/微调)→优化→架构”的路径进行系统性思考。
如何权衡:在快速试错的提示工程、增强知识的 RAG 与深度控制的微调之间,如何根据数据可用性、成本预算、性能要求中做出理性的选择。
如何避坑:挑战、局限性和故障模式分析,如评估的偏见、提示注入的风险、智能体的循环失效等,是比成功案例更宝贵的实战经验。
04
新的竞争点
2025 年 4 月,当 OpenAI 的研究员姚顺雨在《The Second Half》中写下“AI 的下半场”不是关于训练更强的模型,而是关于如何定义正确的问题。这本书也正是如何在“AI 下半场”中生存和发展的实战手册。在这个意义上,它可能比那些动辄讲解 Transformer 架构的圣经级著作更具现实意义。
读完这本书,你可能会想到 2026 年初腾讯混元团队的那次组织架构调整:新设 AI Infra 部、AI Data 部,将原有的大模型应用部重组为三个应用部门。这种从模型为中心向工程体系为中心的组织变革,与本书的核心理念不谋而合——当基础模型的能力趋于同质化,工程能力、数据能力、架构能力将成为差异化竞争的关键。