宇树机器人OmniXtreme解锁新技能:人形机器人学会连续翻转、霹雳舞。秘诀:流生成预训练+驱动感知残差强化学习,大幅提升动作成功率和鲁棒性。
原文标题:王兴兴署名,宇树机器人春晚之后又进化了:单个策略就能学习各种极限动作
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到OmniXtreme在电机约束、功率安全等方面做了很多优化,这些优化对于人形机器人的实际应用有什么意义?
3、文章提到OmniXtreme采用了基于流的生成控制策略,这种策略相比传统的强化学习有什么优势?为什么能够打破模型规模的Scaling Law限制?
原文内容
春晚上,《武 BOT》给人留下了深刻印象。表演中,人形机器人 G1 和 H2 在快速奔跑中完成了穿插变阵和武术动作,展现出了高动态、高协同的全自主集群控制技术。

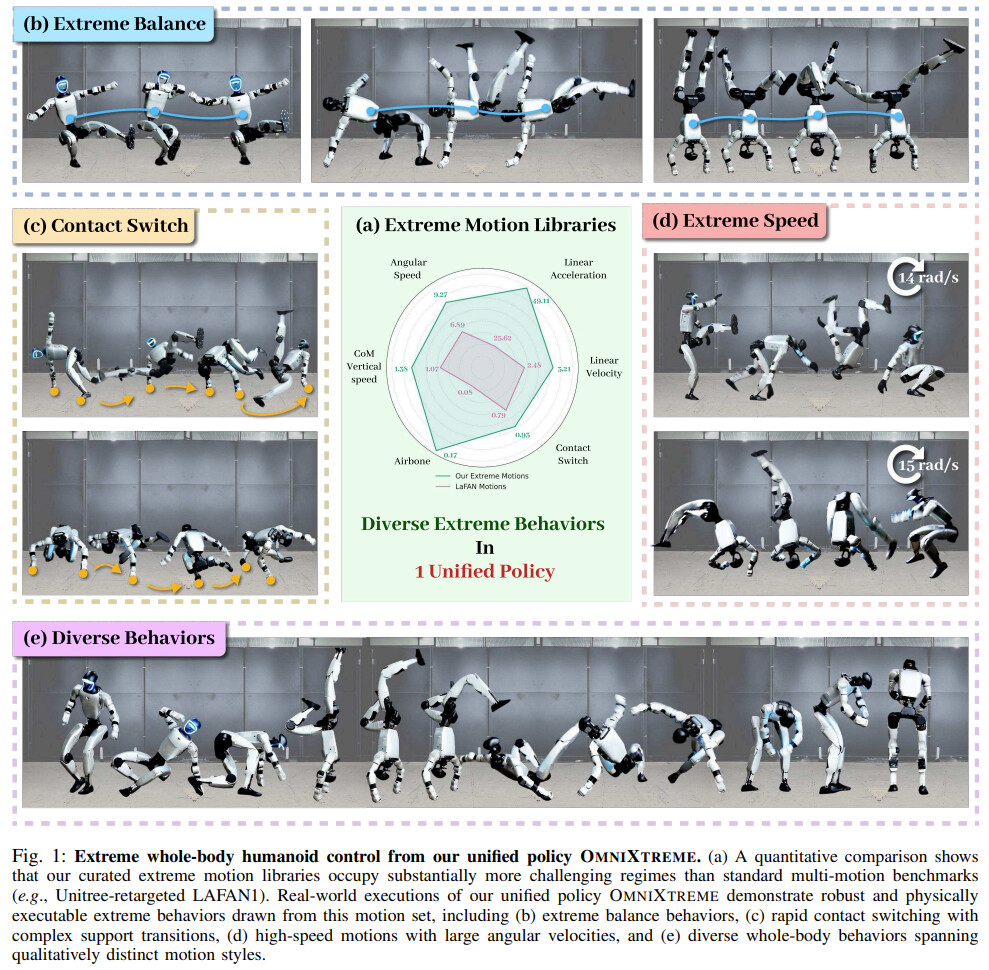
而现在,北京通用人工智能研究院(BIGAI)、宇树、上海交通大学和中国科技大学等机构的一项新研究在这个方向上更推进了一步,提出了 OmniXtreme:第一个可以执行各种极限动作的通用策略,包括连续翻转、极限平衡,甚至可以通过快速接触切换进行霹雳舞。
这种能力的实现过程首先是预训练一个基于流的生成控制策略(flow-based generative control policy),然后针对复杂物理动力学进行「驱动感知残差强化学习」(actuation-aware residual RL)的后训练。其中后训练这一步对于成功实现真实世界的迁移至关重要。
该项目的通讯作者之一、BIGAI 研究科学家 Siyuan Huang 在 X 上表示:「我们花了一整年时间深入研究通用跟踪和极端物理行为之间的障碍。在测试了数十台 G1 机器人之后,我们最终找到了学习和物理执行能力方面的瓶颈。」
值得注意的是,宇树科技联创和 CEO 王兴兴也在这篇论文的作者名单中。论文一作为 Yunshen Wang 和 Shaohang Zhu。

-
论文地址:https://arxiv.org/abs/2602.23843
-
项目地址:https://extreme-humanoid.github.io
-
代码地址:https://github.com/Perkins729/OmniXtreme
方法:打破高动态控制的泛化壁垒
在人形机器人的运动控制领域,研究人员长期面临一个被称为「泛化壁垒(generality barrier)」的困境。
当动作库的规模和多样性增加时,传统的统一强化学习策略往往会遭遇性能崩溃,这在高动态动作的物理部署中尤为明显。这种崩溃源于两个相互叠加的瓶颈:仿真环境中的学习瓶颈(多动作优化的梯度干扰)以及物理执行瓶颈(真实世界复杂的驱动约束)。
为了从根本上解决这一问题,该研究团队提出了 OmniXtreme 框架。该框架将动作技能的学习与物理驱动的微调进行了巧妙的解耦,分为「基于流的可扩展预训练」与「驱动感知的残差后训练」两个核心阶段。
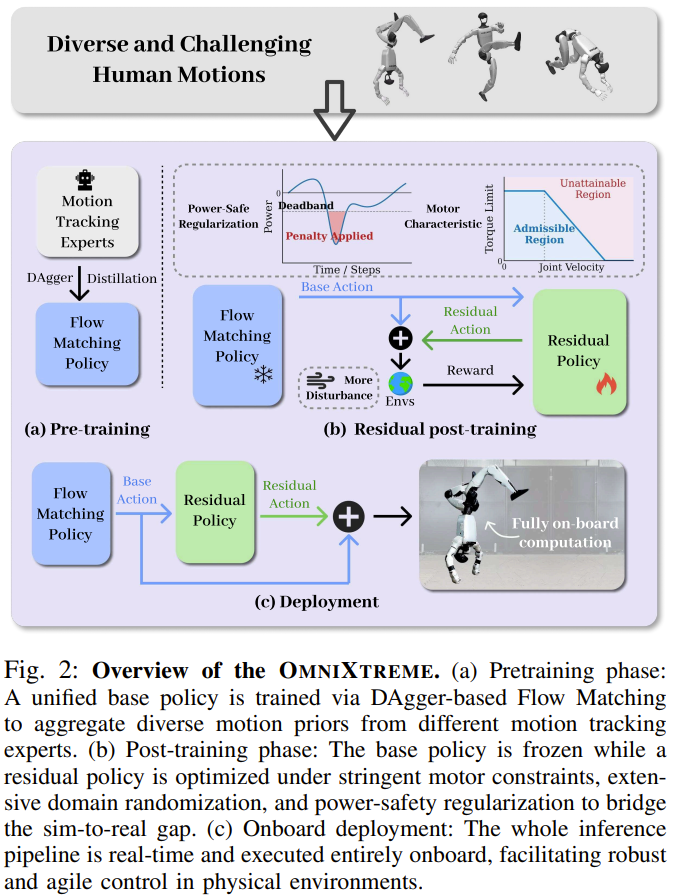
阶段一:基于流的可扩展预训练
在第一阶段,研究团队的目标是赋予模型极高的表示容量,使其能够掌握大量异构的极限动作,同时避免传统多动作强化学习中常见的保守化平均倾向。
研究人员首先整合了 LAFAN1、AMASS、MimicKit 等多个高质量动作数据集,并将其重定向至宇树 G1 人形机器人上。
针对这些参考动作,团队利用 PPO 算法训练了一系列专家策略。随后,OmniXtreme 采用了基于数据集聚合 (DAgger) 的知识蒸馏技术,将这些专家策略的行为统一融合到一个基于流匹配的生成式策略中。

在数学表达上,基于流的模型通过优化以下目标函数来学习从纯噪声中恢复专家动作的过程 :
在上述公式中,a_t 表示在流时间步 t 下,专家动作 a_{expert} 与随机噪声 ε 之间的插值动作。该目标函数使得模型能够学习到一个速度场 v_θ,从而在推理时通过正向欧拉积分生成高精度的连续控制动作。为了保证物理稳定性,团队在这一阶段仅引入了适度的噪声和域随机化,确保策略能够准确捕捉底层的物理动力学特征。
阶段二:驱动感知的后训练
预训练得到的流匹配策略虽然在仿真中表现出了惊人的跟踪精度,但现实世界中的电机非线性特性往往会导致这种高动态表现大打折扣。
为了实现平滑的「仿真到现实」迁移,团队冻结了预训练的基础策略,并在其之上训练了一个轻量级的 MLP 残差策略。该残差策略无需重新学习动作跟踪,主要负责输出修正动作以对抗真实的硬件约束。
为了让残差策略真正理解物理世界的残酷,团队在训练环境中引入了三个层面的深度建模:
1. 激进的域随机化
研究人员将初始姿态噪声、外力干扰幅度、角速度等常见域随机化参数的范围大幅提升了最高 50%。更为关键的是,他们将终止阈值放宽了 1.5 倍(例如将躯干方向误差容忍度从 0.8 弧度放宽至 1.2 弧度)。这种设计给予了残差策略充足的探索空间,使其能够学会在大偏差状态下进行极限挽救,极大地增强了系统的鲁棒性。
2. 功率安全驱动正则化
执行后空翻等高动态动作时,机器人会产生巨大的瞬态制动负载。常规的强化学习管线通常缺乏对此类负载的约束,从而极易在真实硬件上触发过流保护或热应力宕机。OmniXtreme 创新性地引入了针对机械功率的惩罚机制,其核心在于计算关节扭矩与角速度的乘积,即瞬时机械功率 P=τ・ω。
对于超出安全死区的高额负功率(再生制动),团队应用了严格的二次惩罚函数 :
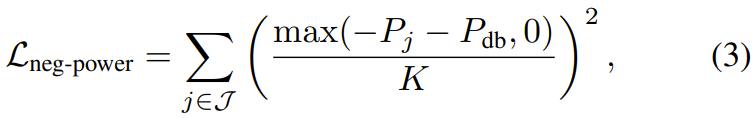
在实际应用中,该惩罚项被重点施加于膝关节,因为膝关节在冲击与恢复阶段最容易承受破坏性的制动负载。
3. 驱动感知的扭矩与速度约束
单纯的扭矩截断往往会忽略由反电动势引起的与速度相关的物理限制。团队将真实的电机运行包络线直接集成到了仿真器中,定义了随关节速度幅值单调递减的容许扭矩函数。此外,系统还通过非线性摩擦项对执行器级别的内部损耗进行了建模 :

该公式精确捕捉了从静摩擦到动摩擦的平滑过渡,并计算了与速度相关的耗散阻尼。
纯机载的实时部署
在硬件部署方面,OmniXtreme 展现出了极高的工程完成度。
整个推理管线(包括基于正向运动学的状态估计、流匹配基础策略以及残差策略)均使用 TensorRT 进行了深度优化。在宇树 G1 人形机器人的机载 NVIDIA Jetson Orin NX 平台上,系统实现了约 10 ms 的端到端推理延迟,完美支持 50 Hz 的高频闭环控制。
实验表现:全方位挑战极限测试
为了全面评估 OmniXtreme 的可扩展性与鲁棒性,研究团队不仅使用了标准的 LAFAN1 动作库,还精心挑选了约 60 个极具挑战性的动作,构建了 XtremeMotion 评估集。这些动作包含了极高的角速度、频繁的接触切换以及严苛的时序约束。
可扩展的高保真跟踪能力
在仿真环境中,OmniXtreme 与传统的「从头训练多动作强化学习」基线模型以及「专家到统一 MLP 蒸馏」基线模型进行了直接对比。数据表明,OmniXtreme 在所有指标上均实现了碾压。面对难度激增的 XtremeMotion 数据集,传统方法的跟踪误差显著增加,而 OmniXtreme 依旧维持了极低的运动学误差和极高的成功率。

在现实世界的宇树 G1 机器人上,团队选取了 XtremeMotion 中的 24 个不同高动态动作进行了 157 次物理测试。测试涵盖了后空翻、杂技、霹雳舞、武术等多个动作类别。
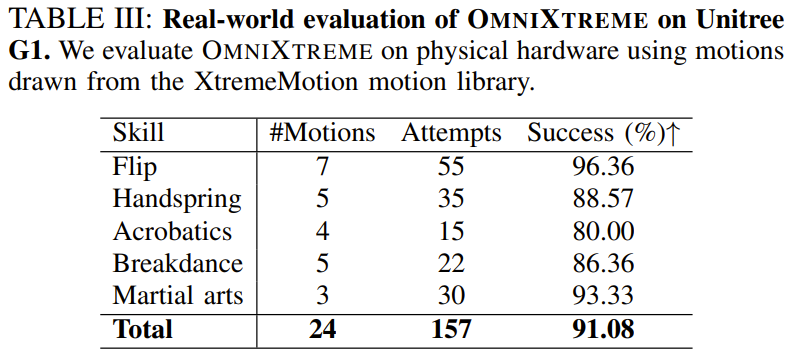
最终,OmniXtreme 斩获了 91.08% 的整体平均成功率。其中,后空翻类动作的成功率高达 96.36%,武术类动作达到 93.33%,霹雳舞类动作也保持在 86.36% 的高水平。这证明了仿真中的高保真度成功跨越了现实鸿沟。
下面展示了一些示例:
托马斯全旋、上旋、向前爬行和后空翻。
霹雳舞
武术
打破保真度与可扩展性的权衡
为了验证系统是否打破了泛化壁垒,团队设计了渐进式的压力测试。他们将训练动作集从 10 个逐步扩展到 20 个,最终扩展到 50 个,并使用固定的前 10 个动作进行统一评估。
实验结果揭示了显著的差异。随着动作多样性的增加,传统从头训练的强化学习基线模型出现了严重的性能衰退,其成功率从 100% 暴跌至 83.3%,最终滑落至 73.9%。
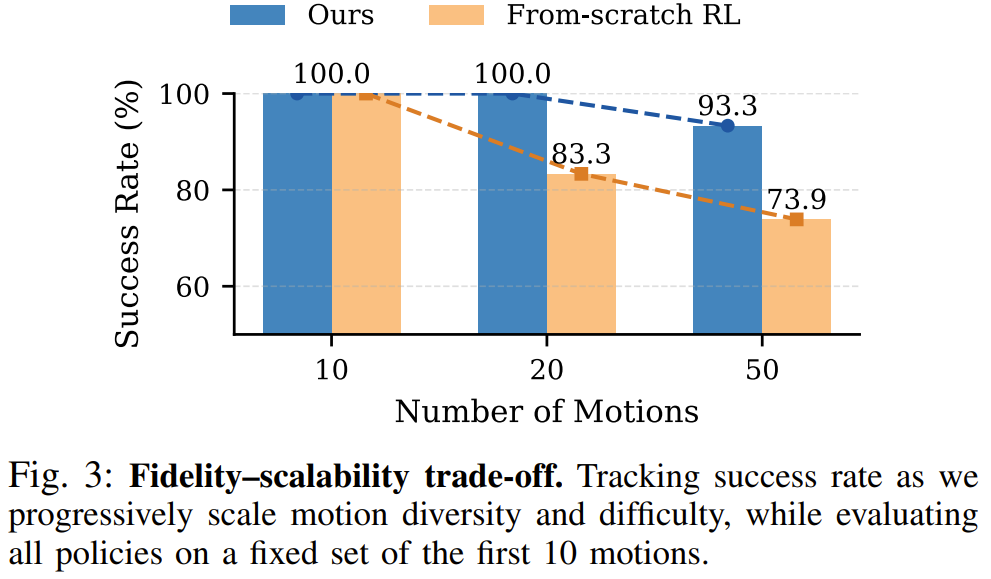
相比之下,OmniXtreme 展现出了惊人的韧性,在 50 个动作的庞大训练集下,其对核心动作的跟踪成功率依然坚挺在 93.3%。这彻底推翻了高保真度必定随着多样性增加而崩溃的固有认知。
模型规模的 Scaling Law
在人工智能的发展历程中,增加模型参数量往往能带来性能的飞跃,但这一规律在传统的运动控制领域似乎失效了。团队对比了不同参数规模(20M、50M、70M)的模型表现。
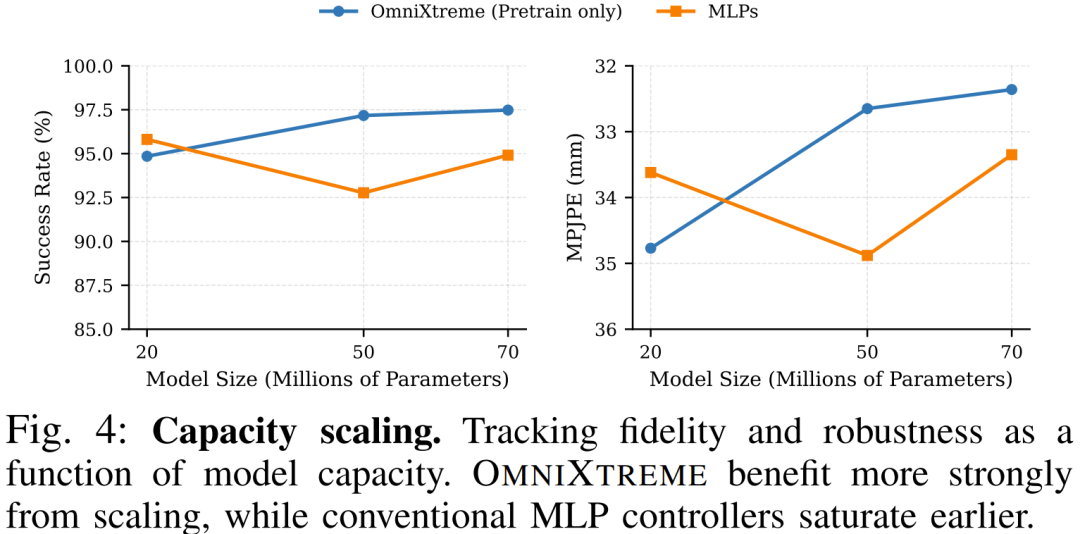
图表数据清晰地显示,传统的 MLP 策略在扩大参数量后很快就陷入了性能饱和,跟踪精度提升极其有限。
与之形成鲜明对比的是,基于流匹配的生成式策略完美契合了 Scaling Law。随着参数量向 70M 迈进,OmniXtreme 的跟踪精度与鲁棒性呈现出显著且稳定的线性增长。这说明生成式预训练为人形机器人控制系统提供了一条切实可行的能力进化路径。
现实世界执行力的深度消融
究竟是哪些机制赋予了机器人如此强大的物理稳健性?团队通过消融实验给出了答案。

对于具有强爆发力的翻腾动作(如后空翻),仅仅引入电机约束就足以保障稳定执行,因为这避免了底层硬件极限的瞬间崩溃。然而,对于包含高频接触转换的霹雳舞动作,系统必须同时依赖电机约束与激进的域随机化,才能在接触扰动中维持时序敏感的平衡。
最严苛的挑战来自于包含高速冲击缓冲的杂技落地动作。团队发现,如果没有功率安全正则化机制,即使模型在姿态上维持了平衡,也会因为电机瞬态制动导致过流或电池欠压而宣告失败。

这充分说明,真实世界的极度敏捷必须建立在声、光、电、热等多维物理约束的精确建模之上。
参考链接
https://x.com/siyuanhuang95/status/2028506522633073132
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com