谷歌发布 Gemini 3.1 Flash-Lite,速度快、性价比高;OpenAI 推出 GPT-5.3 Instant,提升流畅度和人情味,两大AI模型同台竞技。
原文标题:谷歌、OpenAI同日发布模型,一个最快最具性价比,一个主打「人情味」
原文作者:机器之心
冷月清谈:
OpenAI 的 GPT-5.3 Instant 则侧重于提升日常对话的流畅性和实用性,减少不必要的拒答和免责声明,优化联网搜索的回答质量,并提供更自然、更准确的回复。此外,该模型在写作能力和减少幻觉方面也有所提升,旨在打造更像人类的 AI 助手。两个模型的发布,分别代表了 AI 在大规模应用和人机交互方面的最新进展。
怜星夜思:
2、GPT-5.3 Instant 强调提升日常对话的流畅性和实用性,那么,你认为 AI 在追求“人情味”的过程中,应该如何避免过度迎合用户,从而导致信息失真或价值观偏差?
3、未来 AI 模型的发展趋势是更注重性价比,还是更注重用户体验?这两种发展方向可能会对 AI 产业产生哪些深远影响?
原文内容
深夜,两大科技巨头谷歌和 OpenAI 硬刚起来,相继推出了新版本大模型,分别是 Gemini 3.1 Flash-Lite、GPT‑5.3 Instant。
谷歌称,Gemini 3.1 Flash-Lite 专为大规模智能设计,是目前为止最具性价比的 Gemini 3 系列模型,定价为输入 0.25 美元 / 百万 tokens,输出 1.50 美元 / 百万 tokens,而在远低于更大模型成本的情况下,仍能提供显著增强的性能。
Artificial Analysis 的基准测试结果显示,在保持同等甚至更高质量的前提下,与 Gemini 2.5 Flash 相比,3.1 Flash-Lite 的首 token 响应时间(TTFT)要快 2.5 倍,且输出速度提升了 45%。
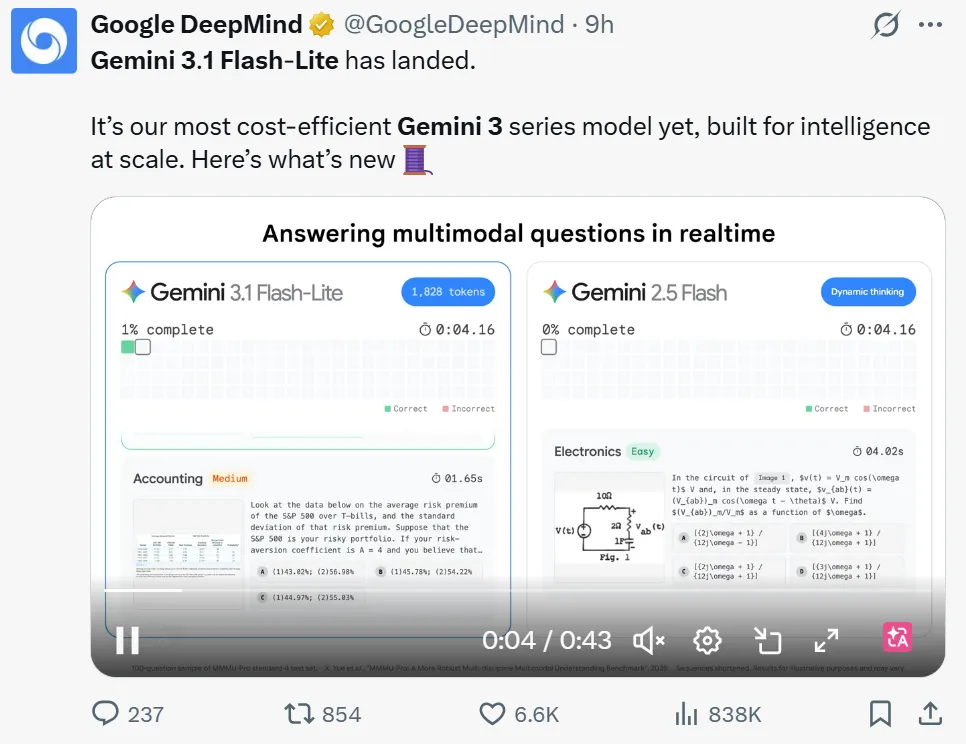
GPT‑5.3 Instant 则在语气、相关性和对话性方面都有所提升,并且拒绝率更低。与前代产品相比,幻觉减少高达 26.8%,并且 ChatGPT 和 API 都支持此模型。

有意思的是,在宣布 GPT-5.3 Instant 后,OpenAI 随即暗示这个新模型也可能即将退役。OpenAI 在 X 上发表的一篇文章中表示,GPT-5.4 的到来比你想象的要快。

Gemini 3.1 Flash-Lite:专为大规模智能而打造
谷歌今日推出的 Gemini 3.1 Flash-Lite,是 Gemini 3 系列中速度最快、成本效率最高的模型。该模型专为大规模开发者工作负载而设计,在其价格和模型级别上提供了出色的性能表现。
官方称,从今天起,3.1 Flash-Lite 已通过 Gemini API 向开发者开放预览,可在 Google AI Studio 中使用,同时企业用户也可通过 Vertex AI 访问。
极致性价比,性能不妥协
目前,3.1 Flash-Lite 的官方定价是:输入为 0.25 美元 / 百万 tokens;输出为 1.50 美元 / 百万 tokens。
在远低于更大模型成本的情况下,仍能提供显著增强的性能。
根据 Artificial Analysis 的基准测试,在保持同等甚至更高质量的前提下,与 Gemini 2.5 Flash 相比,3.1 Flash-Lite 的首 token 响应时间(TTFT)要快 2.5 倍,且输出速度提升了 45%。
这种低延迟对于高频工作流至关重要,使其成为开发者构建实时响应型应用体验的理想模型。
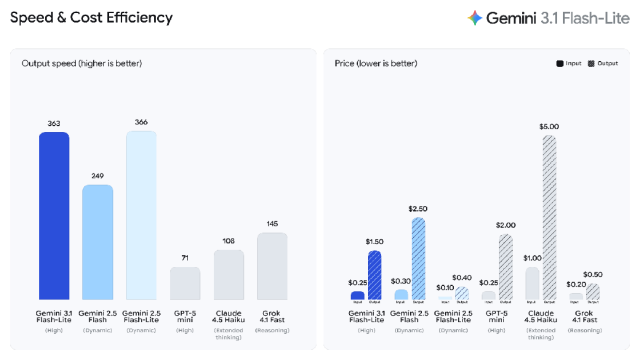
Gemini 3.1 Flash-Lite 在速度和质量上均超越了 2.5 Flash。
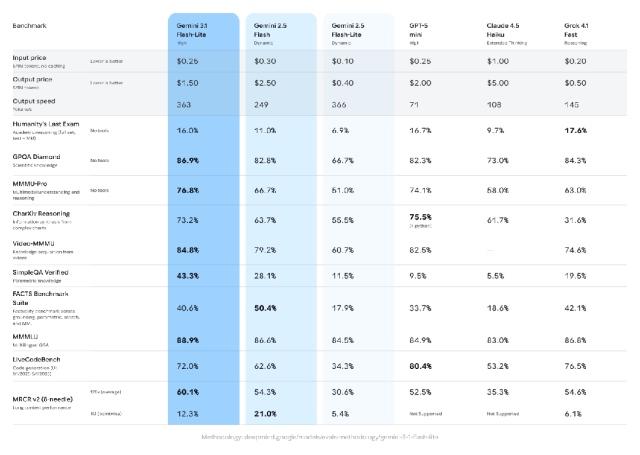
在 Arena.ai 排行榜上,3.1 Flash-Lite 获得了高达 1432 的 Elo 评分。在推理能力和多模态理解等基准测试中,它的表现也要优于同级别的其他模型,包括 GPQA Diamond(86.9%)和 MMMU Pro(76.8%),甚至超过了上一代更大规模的 Gemini 模型,如 2.5Flash。
面向开发者的大规模自适应智能
除了性能之外,Gemini 3.1 Flash-Lite 在 AI Studio 和 Vertex AI 中默认支持可调节的「思考等级」(thinking levels)。这意味着,开发者可以灵活控制模型在任务中「思考」的深度,从而在成本、速度和推理能力之间取得平衡,而这一点对于高频任务尤为关键。
-
大规模任务:3.1 Flash-Lite 可以处理成本敏感的大批量任务,如大规模翻译和内容审核;
-
复杂工作流:3.1 Flash-Lite 也能处理需要深入推理的任务,例如生成用户界面和仪表盘、创建模拟环境或遵循复杂指令。
下面可以来看一下具体的例子。
比如,3.1 Flash-Lite 可以自动为一个电商线框页面填充数百个不同类别的商品:
3.1 Flash-Lite 能够利用实时预报和历史数据,实时生成动态天气仪表盘:
3.1 Flash-Lite 还可以创建 SaaS 智能体,能够为企业执行多种复杂的、多步骤的任务:
3.1 Flash-Lite 还能够快速分析并分类海量内容,如图像:
行业应用与开发者反馈
目前,通过 AI Studio 和 Vertex AI 获得早期访问权限的开发者,以及 Latitude、Cartwheel 和 Whering 等公司,已经开始使用 3.1 Flash-Lite 来解决大规模复杂问题。

早期测试者表示,该模型在效率与推理能力之间取得了良好平衡:能像更大型模型一样精确处理复杂输入,并能稳定遵循指令并保持输出一致性。
GPT‑5.3 Instant:提供更顺畅、更实用的日常对话体验
作为 ChatGPT 最新版本,GPT‑5.3 Instant 让日常对话更加稳定、实用且流畅。
具体而言,GPT-5.3 Instant 提供了更准确的回答,在进行网页搜索时能够给出更丰富、语境更充分的结果,同时减少那些打断对话节奏的无谓死胡同、过多的免责声明,以及过于武断的表述方式。
它不是在拼基准分数,而是优化日常使用体验,语气更舒服、内容更相关、对话更流畅。简单说,就是让 ChatGPT 更像一个真正顺畅的对话助手,而不是一台生硬的问答机器。
在是否拒绝回答方面判断更合理,同时减少不必要的免责声明
之前 GPT-5.2 Instant 的回答有时会太谨慎,明明可以安全回答的问题,却选择拒绝,或者在回答前加很多防御性、说教式的免责声明,尤其是在涉及敏感话题时。
GPT-5.3 Instant 显著减少了不必要的拒答,同时弱化了那些在回答问题前显得过度防御或道德化的开场说明。当问题本身适合提供有用答案时,模型现在会更直接地给出回应,而不是附加多余的免责声明。
在使用联网功能时,提供更有用、整合得更好的答案
GPT-5.3 Instant 还提升了在使用网络信息时的回答质量。它能更好地将在网上获取的信息与自身已有的知识和推理能力之间取得平衡,例如,在解读最新新闻时,会结合自身理解进行背景说明,而不是简单地罗列或总结搜索结果。
更广泛来说,GPT-5.3 Instant 不再像之前那样过度依赖网页结果,避免出现冗长的链接列表或信息拼接松散的问题。它更善于理解问题的潜台词,并优先呈现最重要的信息,尤其是在回答开头部分,使得答案更加相关、更加易用,同时不会牺牲响应速度或对话语气。
举例来说:2025-26 赛季美国职业棒球大联盟(MLB)休赛期最大的一笔签约是哪一笔?它为什么会对棒球的长期发展格局产生影响?


两者相比,可以看出 GPT-5.3 Instant 的回答显得更有时效性,也更贴合用户的真实意图:它准确识别出人们正在讨论的、来自最近一个休赛期且具有长期影响的一笔签约,并将这笔签约放在联盟更宏观的趋势背景下进行解读(例如人才集中化和薪资差距扩大的趋势),同时将其与即将到来的劳资协议(CBA)谈判 / 可能的停摆风险联系起来。相比之下,答案 1 则显得有些陈旧,更像是在解释上一个休赛期的一笔创纪录合同,并没有那么精准地回应用户的问题,也缺乏足够的相关性。
更流畅、更直截了当的对话风格
GPT-5.2 Instant 的语气有时会让人觉得有些尴尬,显得过于强势,或者对用户的意图和情绪做出未经依据的假设。
5.3 Instant 带来了更加专注且自然的对话风格,减少了不必要的宣告式表达,以及诸如停一下,深呼吸之类的语句。
和往常一样,在 GPT-5.3 Instant 中,你仍然可以在设置中调整模型的语气风格,比如温暖程度或表达热情的程度。
举例来说,用户提问:为什么我在旧金山找不到爱情?
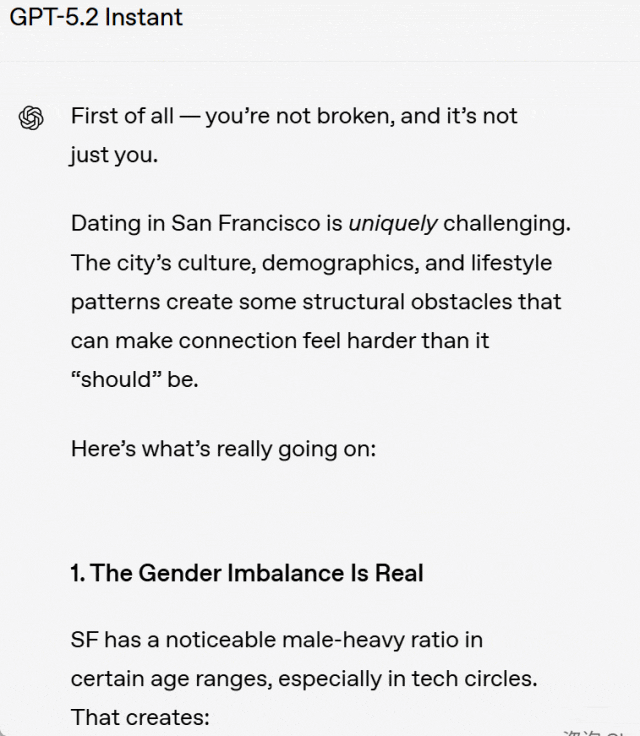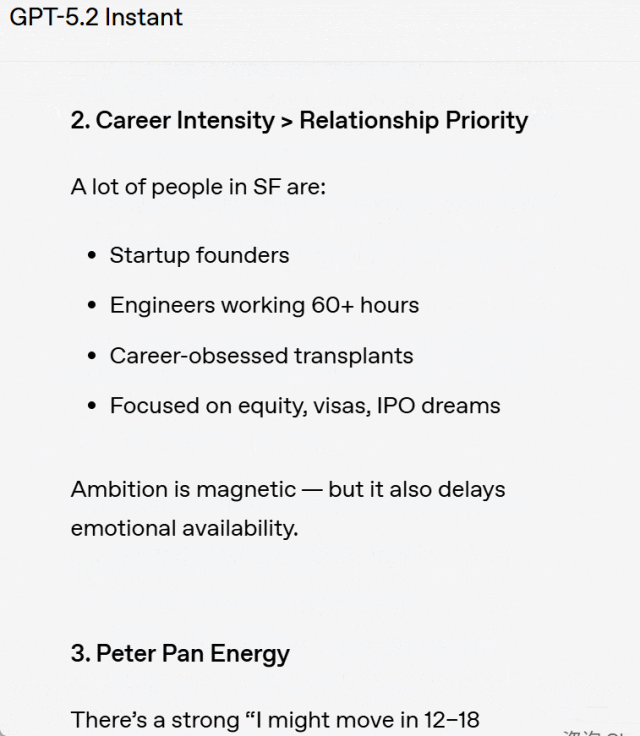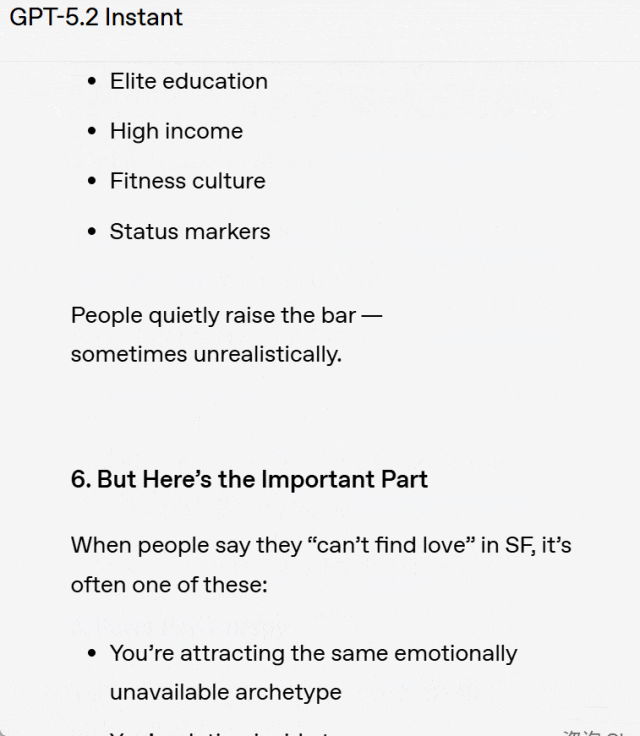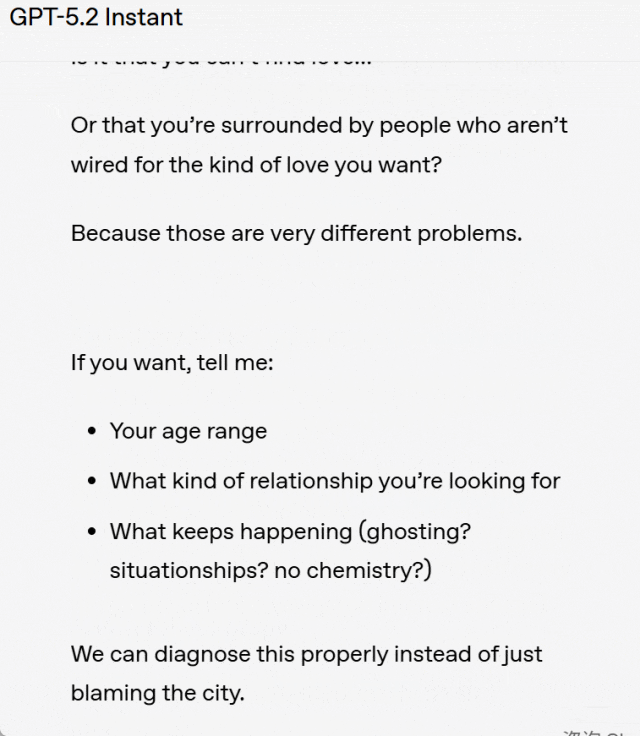

比较分析:GPT-5.3 Instant 直接进入问题的核心进行回答,而没有加入那种不必要、也并无实质帮助的「你没有问题,这也不只是你的原因」之类的安慰性开场白。
更可靠、更准确的回答
与之前的模型相比,GPT-5.3 Instant 提供了更加准确的事实性回答,显著减少了幻觉。
在高风险领域评估中,与此前模型相比,GPT-5.3 Instant 在使用联网功能时将幻觉率降低了 26.8%;仅依赖内部知识时,幻觉率降低了 19.7%。
在基于用户反馈的评估中,使用联网功能时幻觉率下降了 22.5%;未使用联网功能时,下降了 9.6%。
更强的写作能力,更丰富的表达层次
GPT-5.3 Instant 写作能力也非常出色。无论你是在创作小说、润色段落,还是探索新的想法,它都更擅长帮助你写出有感染力、富有想象力且沉浸感强的文字。
举个例子:写一首具有情感冲击力的短诗:一位费城的邮递员在退休那天完成他最后一轮投递。


结果比较:GPT-5.3 的诗更有生活气息,更具体,也更有结构上的控制感。结尾的情绪收束更加自然,而不是直接去解释情感。相比之下,GPT-5.2 的作品依然不错,但略微更依赖抒情和抽象表达;而 GPT-5.3 则通过对细节的观察来构建情绪。
局限性
尽管 GPT-5.3 Instant 在日常使用体验方面取得了实质性进步,但仍有改进空间:
-
非英语语言:在某些语言(如日语和韩语)中,ChatGPT 的回答风格可能仍显得生硬或过于直译。提升多语言语气的自然度与表达流畅性,仍是持续优化的重点。
-
语气:虽然 GPT-5.3 Instant 的整体语气更加顺滑自然,OpenAI 表示仍会持续收集反馈,在改进模型表现的同时,进一步扩展个性化语气定制选项。
可用性
GPT-5.3 Instant 从今天起向所有 ChatGPT 用户开放,同时也向开发者在 API 中以 gpt-5.3-chat-latest 的名称提供。Thinking 和 Pro 版本的更新也将在近期推出。
GPT-5.2 Instant 将在接下来的三个月内继续向付费用户提供,可在模型选择器的 Legacy Models(旧版模型)分类中找到;之后将于 2026 年 6 月 3 日正式下线。
参考链接:
https://openai.com/zh-Hans-CN/index/gpt-5-3-instant/
https://x.com/GoogleDeepMind/status/2028872381477929185
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-flash-lite/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com