FeatureBench基准用于评估大模型在复杂feature开发中的Agentic Coding能力,侧重跨文件、跨对象和长程依赖,更贴近真实软件工程。
原文标题:不止修bug:Agentic Coding评测走向复杂feature交付新阶段
原文作者:机器之心
冷月清谈:
怜星夜思:
2、FeatureBench特别强调了提供原生codebase的接口描述,避免Agent因为接口不匹配而无法通过测试,在实际开发中,你认为应该如何保证接口描述的准确性和完整性?
3、FeatureBench使用了错误历史回溯机制来保证任务的可执行性,这种机制在应对复杂的软件系统时,可能会遇到哪些挑战?
原文内容

在 Princeton 发布 SWE-Bench 之后,用真实世界代码仓库+可执行测试评测大模型软件工程能力,几乎已成为学术界与工业界的共识。围绕 SWE issue 的评测范式迅速发展,也催生了一系列 SWE 系列 benchmark,在刻画模型 bug 修复能力方面发挥了重要作用。
但真实的软件工程实践并不止于修 bug。大量关键工作发生在 feature 级别的 End-to-End 开发中:它往往意味着更长的代码路径、更复杂的跨文件依赖,以及对长期上下文与整体系统行为的理解。也就是说,能修 bug 并不意味着能交付一个完整的 feature。
为填补这一空白,中国科学院自动化研究所联合华为聚焦 Test-Driven 的评测范式,提出了 FeatureBench(Benchmarking Agentic Coding in End-to-End Development of Complex Features),并构建了一整套覆盖数据构建、推理与评测的端到端基础设施。数据、管线代码与执行镜像均已完整开源,旨在为评估与推动更强、更全面的 agentic coding 模型提供新的基准。

-
论文标题:FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
-
项目主页:https://libercoders.github.io/FeatureBench/
-
arXiv 论文:https://arxiv.org/abs/2602.10975
-
Hugging Face 数据集:https://huggingface.co/datasets/LiberCoders/FeatureBench
-
GitHub 代码库:https://github.com/LiberCoders/FeatureBench
-
Docker 镜像:https://hub.docker.com/u/libercoders
「高精准度」
动态追踪驱动的精准 feature 级代码抽取
FeatureBench 的任务构造以真实代码仓库中的单元测试作为切入点。在成熟的软件工程中,单元测试往往覆盖完整的功能路径或其关键组成部分,并隐式刻画了 feature 的行为边界与实现假设,因此天然适合作为定位 feature 行为范围的自然入口。
不同于仅将单元测试作为结果评估手段的既有评测方式,FeatureBench 在任务构造阶段便引入单元测试,用其反向定位并抽取与目标 feature 强相关的实现代码,从而形成要求 Code Agent 补全 feature 本身的评测任务。具体而言,系统会首先在真实代码仓库中自动发现并筛选可执行的单元测试,将这些单元测试所测内容视为任务的目标 feature,作为后续的 Fail-to-Pass(F2P);与此同时,引入 Pass-to-Pass(P2P)测试,用于约束任务构造过程中对非目标功能的潜在破坏。
在测试执行过程中,FeatureBench 利用动态追踪技术,从 F2P 单元测试出发,捕获执行测试路径上的函数调用与对象依赖关系,并在对象粒度上对相关实现进行标注与分类。随后,系统仅会抽取并移除既与 F2P 测试强相关、又不会影响 P2P 测试持续通过的实现代码,其余部分保持不变。而被移除的代码的接口,签名等信息则通过规则自动从原声代码抽取,并在后续作为任务描述的一部分提供给模型。
这里需要强调的是,研究团队在构造评测任务之初,便考虑到了 featrue 级实现任务接口模糊可能导致的任务不可解的问题——对于feature开发问题,若给 Agent 的任务描述本身是模糊的自然语言,则极有可能出现 Agent实现了逻辑等价的功能,但因为接口不匹配的问题而无法通过已经固定的单元测试的情况。
因此在每条任务中,FeatureBench 都提供了原生codebase的接口描述。所有接口签名均通过规则自动抽取自原生 codebase。对于那些原生codebase缺少接口描述的任务,例如某些案例中的接口签名下缺少详细的docstring,FeatureBench 构建了一套自动化的工作流,让大模型根据设定好的必要信息去合成详细的接口描述。所有合成的接口描述均在后续进行了人工检验。
通过这一过程,FeatureBench 构造得到的是一类更接近真实开发场景的评测任务:模型需要在保持所有 P2P 通过的前提下,仅依据给定的接口描述与仓库上下文信息,补全缺失的 feature 实现。
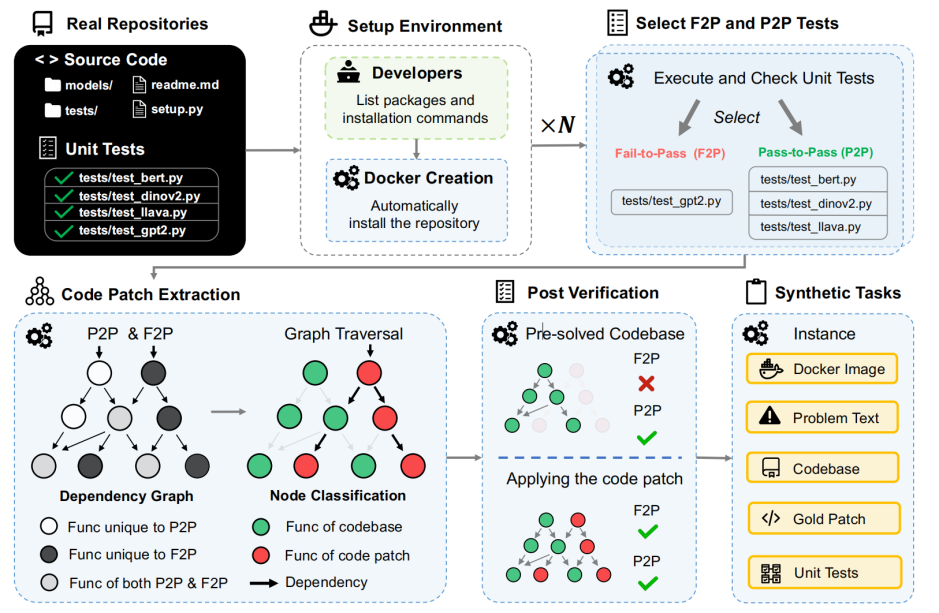
从单元测试出发,结合动态追踪定位 feature 相关对象,抽取并移除实现,生成缺失版本代码库与 gold patch,并在沙盒环境中执行评测。
「强可执行性」
基于错误历史回溯的任务构造机制
然而,在真实代码库中直接移除实现代码,往往会引入非常多困难且复杂的工程问题。复杂系统中存在大量隐式依赖、初始化逻辑与运行时假设,一旦相关代码被删除,程序甚至可能在单元测试执行之前就已无法启动,导致构造出的任务失去可执行性。
为解决这一问题,FeatureBench 首次在任务构造过程中引入了错误历史回溯机制,将 “可执行性” 作为代码抽取过程中的硬约束,用于保障代码抽取过程的稳定性与可执行性。系统会在每一次抽取操作后记录可回溯的中间状态,并即时验证任务的可执行性;一旦发现删除某一部分代码导致程序无法运行、测试环境失效、或 P2P 测试失败,构造流程将自动回退至最近一次可正常执行的状态,并据此重新调整后续的抽取策略。
通过这一机制,FeatureBench 能够在无需人工干预的前提下,逐步收敛,稳定完成 feature 相关实现的抽取,确保每一个生成的评测实例均满足 “可执行、可验证” 的基本要求。这使得在真实代码仓库中大规模、持续的自动化任务构造成为可能。
「强验证机制」
由目标对齐、验证闭环与长链路复杂性构成的评测约束
在复杂 feature 的评测中,“更难” 往往并不意味着 “更可靠”。一些现有基准虽然引入了真实仓库和较长代码路径,但评测结果仍然容易受到多种噪声干扰:
一方面,评测目标通常依赖人工接口或自然语言描述,从而不同模型对实现目标形成不同理解,导致评测结果混合了能力差异与任务理解偏差。
另一方面,现有工作对于抽取出来的 feature 是否真正可验证可执行往往并不透明:模型的失败可能来自无关功能被破坏、依赖链被意外切断,而非 feature 本身尚未实现,使得评测分数难以反映真实的 feature 开发能力。
此外,为了控制难度或保证可执行性,任务构造过程中常会对真实代码路径与依赖关系进行裁剪,使得看似复杂的任务在实际实现中并不包含真实系统中的长程依赖,进一步削弱了评测结果的指示意义。
针对以上这些问题,FeatureBench 并未通过额外设计规则或人工后处理筛选,而是将噪声控制前移到任务构造阶段。首次通过在真实代码仓库中施加三重约束,在保证任务复杂性的同时,使评测结果更稳定、可对齐,更具可解释性。
1) 目标对齐(评测的公平性):
FeatureBench 中所有顶层对象的接口签名均通过规则自动抽取自原生 codebase,而非人工编写或模型生成。由于接口定义直接来源于真实实现,这一设计显著降低了由人为抽象或描述不一致所引入的实现歧义,使不同模型在评测时面对的是同一组、可精确定义的功能目标,而非依赖对任务意图的主观理解。
2) 验证闭环(评测的完备性):
FeatureBench 对每一个任务均施加严格的先验与后验验证约束。即在代码抽取前,所有 F2P/P2P 测试必须全部通过;在代码抽取后,F2P 测试的通过率需低于预设阈值,而所有 P2P 测试必须保持全通过。这一双阶段验证机制确保:被移除的实现确实构成目标 feature 的核心组成部分,同时任务难度来源于对 feature 实现本身的还原,而非由不受控的代码破坏或偶然失效引入的伪难度。
3) 长链路复杂性(评测的长程性):
FeatureBench 的任务构造遵循从单元测试 → 顶层对象 → 关联对象与深层依赖的逐级展开过程。顶层接口仅刻画了 feature 的外部行为,其背后往往对应大量跨文件、跨对象的实现细节与隐式依赖关系。
因此,FeatureBench 中的任务通常涉及更长的代码路径与更广泛的修改范围,对 agent 的长程推理能力、系统级理解能力以及对既有行为约束的整体把握提出了更高要求。
「高复杂度」
面向真实 feature 的大规模可执行评测实例
基于上述自动化数据构建管线,研究团队在 3 天之内,系统性构建了 3825 个可执行的沙盒环境与候选任务实例。覆盖 24 个真实世界、覆盖不同应用场景且具有广泛影响力的 GitHub 仓库。所有实例均可直接运行,为后续筛选与评测提供了统一的可执行基础。
在此基础上,通过进一步施加统一的筛选约束,包括代码时间范围(2022 年 5 月之后)、测试覆盖强度(测试点数量大于 10)以及 feature 抽取规模(抽取代码行数超过 100 行),以确保任务在复杂度与代表性上的一致性。并经过人工 verified 验证,最终确定了 FeatureBench 的正式评测数据集:
-
FeatureBench Full:包含 200 条评测任务。单任务最多抽取 4495 行代码,单任务最多涉及 76 份不同代码文件。
-
FeatureBench Lite:从 Full 集中进一步筛选 30 条任务,作为低成本评测子集,便于社区进行快速对比实验与方法迭代。
整体来看,FeatureBench Full 中的任务在代码规模、依赖广度与测试约束强度上,均显著高于典型的 bug-fixing benchmark,更贴近真实工程环境中 feature 级开发的复杂度分布。
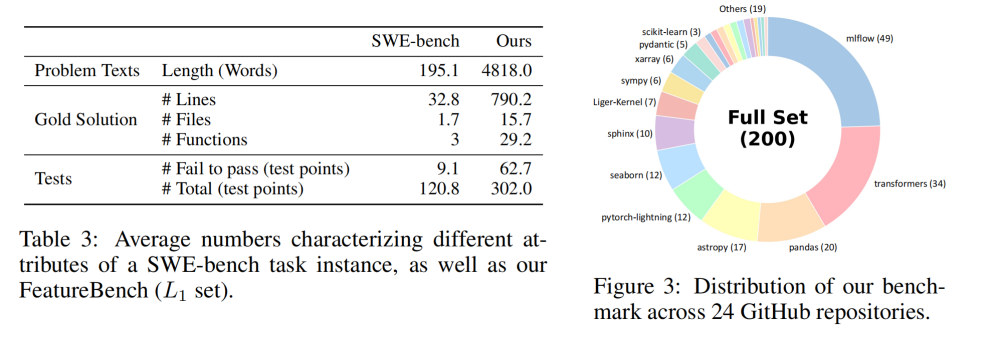
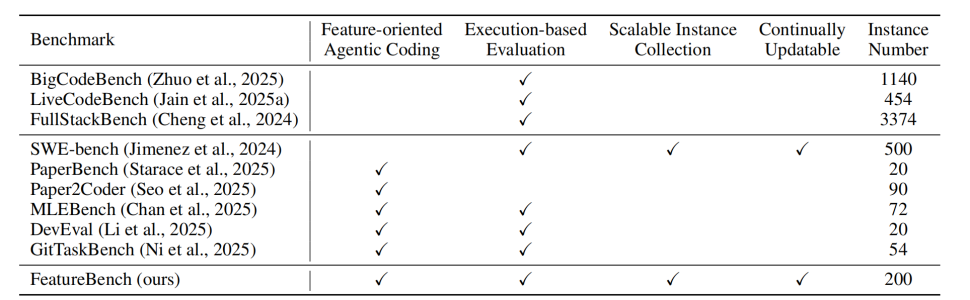
FeatureBench 的复杂度显著高于典型 bug-fixing benchmark,覆盖跨文件、跨对象、长程依赖的真实 feature 实现。
「高区分度」
Feature 级任务评测重新拉开模型能力差距
研究团队在 FeatureBench 上对多种主流 agent 框架(包括 OpenHands、Codex、Gemini-CLI、Claude Code 等)与多种模型配置(Opus 4.5、GPT-5.1-Codex、Gemini-3-Pro、Qwen-3-Coder-480B-A35B-Instruct、DeepSeek-V3.2 等)进行了系统评测。
评测结果显示,在以 bug fixing 为核心的 SWE-Bench 场景中,主流高性能模型的整体表现已呈现出明显的能力收敛趋势:不同模型之间的 resolved rate 差距相对有限,难以进一步刻画其在更复杂工程任务中的能力差异。
相比之下,当评测任务推进到 feature 级端到端开发时,模型与 agent 之间的差距被显著放大。以 Claude Opus 为例,其在 SWE-Bench Verified 上的 resolved rate 已达到 74.4%,而在 FeatureBench Full 上的解决率为 11%;与此同时,其他模型在 FeatureBench 上的表现分化更为明显,呈现出远高于 SWE-Bench 场景的区分度。
这一现象表明,FeatureBench 并非简单地提高了任务难度,而是通过引入跨文件、跨对象的长程依赖结构,以及严格的 P2P 约束,将评测焦点从局部缺陷修复能力推进到系统性 feature 交付能力。在这一设定下,即便在 bug fixing 任务中表现接近的模型,也会在 feature 级开发能力上呈现出明显差异。

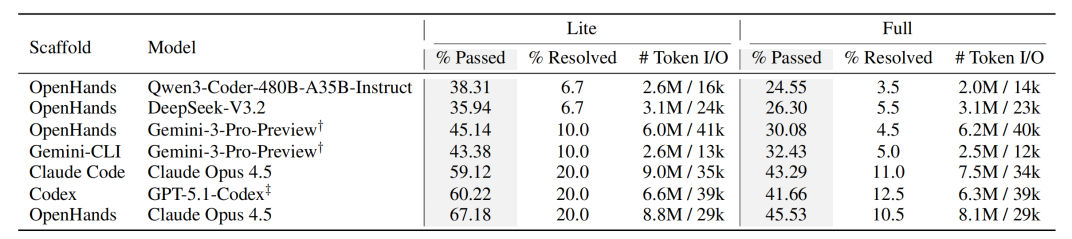
Bug Fixing 任务上前沿模型能力已收敛,但 Feature 级任务中仍体现出能力分化

Lite 数据集上的模型表现
「高易用性」
一行命令启动 FeatureBench 的完整评测流程
为降低 FeatureBench 的复现与评测门槛,并支持学术界与工业界的实际使用,研究团队同步开源了一套覆盖推理、评测与数据构建的完整基础设施。通过统一的运行环境与标准化配置,用户无需繁琐的环境搭建或手动拼装流程,即可在本地或集群中一键启动完整评测流程,从推理执行到结果统计实现端到端复现。在这一设计下,FeatureBench 不再只是一个静态数据集,而是一个可长期演进、可持续扩展的评测平台。
推理模块(Inference):多 Agent 框架的统一入口
FeatureBench 提供了统一的 agent 抽象接口,对主流代码 agent 框架进行了标准化适配,包括 Claude Code、Codex、Gemini-CLI、OpenHands 以及 Mini-SWE-Agent 等。用户只需进行最小化配置,即可将自定义 agent 接入现有管线,并在统一环境中完成大规模推理实验。
该模块同时内置了断点续传、并发执行、网络代理与资源控制等机制,使长时间、多配置的推理任务能够通过单一命令稳定运行,显著降低实验管理成本。
评测模块(Evaluation):执行即评测
以实际测试执行结果为唯一依据,对模型生成的代码补丁进行自动化评测,严格统计 F2P/P2P 测试的通过情况,确保不同模型与 agent 的评测结果具有良好的可复现性与可比性。
数据构建管线(Data Pipeline):任务可自动生成、持续扩展
完整开源了 FeatureBench 的原生任务生成流程,覆盖从代码仓库拉取、单元测试发现与筛选、动态追踪、顶层对象识别、P2P 测试选择,到对象级代码抽取与后验验证的全链路步骤。借助该管线,FeatureBench可以在无需人工干预的情况下持续、自动、可验证地生成新的任务。
结语
FeatureBench 是 Code Agent 评测领域的一次关键突破:FeatureBench 系统性地将 agentic coding 的评测范式,从“短 patch、少文件、单 PR 的 bug fixing”,推进到了“跨文件、跨对象、长程依赖的真实 feature 开发”。更重要的是,FeatureBench 通过 test-driven 的自动化任务构造流程,在保证公平性与完备性的同时,大幅提升任务复杂度,并为 benchmark 的持续扩展与防数据污染提供了一条可行路径。
同时,FeatureBench作为一套面向真实软件工程场景的可执行数据生成与验证基础设施,将为后续 Agent 训练与强化学习提供数据支持。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com