清华研究揭示BF16 FlashAttention训练崩溃机制:相似低秩结构放大舍入误差,导致loss爆炸。提出极简修复方案,稳定训练。
原文标题:为什么BF16的FlashAttention会把训练「炸掉」?清华首次给出机制解释,用极简改动稳住训练
原文作者:机器之心
冷月清谈:
怜星夜思:
2、论文中提到,一些稳定化技巧(如 QK normalization、Gated Attention)可能通过 “打散结构相似性” 来阻止误差同向累积。这些技巧是如何起作用的?有没有其他有效的稳定训练技巧?
3、这篇论文主要关注的是 FlashAttention 在 BF16 下的问题,那么 FlashAttention 在其他精度下,或者其他 attention 机制在 BF16 下,是否也会出现类似问题?这种研究对于未来大模型训练有哪些启示?
原文内容

一句话总结:社区里困扰了多年的一个 “玄学” 现象终于被拆解清楚了:在 BF16 等低精度训练里,FlashAttention 不是随机出 bug,而是会在特定条件下触发有方向的数值偏置,借助注意力中涌现的相似低秩更新方向被持续放大,最终把权重谱范数和激活推到失控,导致 loss 突然爆炸。论文还给出一个几乎不改模型、只在 safe softmax 里做的极小修改,实测能显著稳定训练。
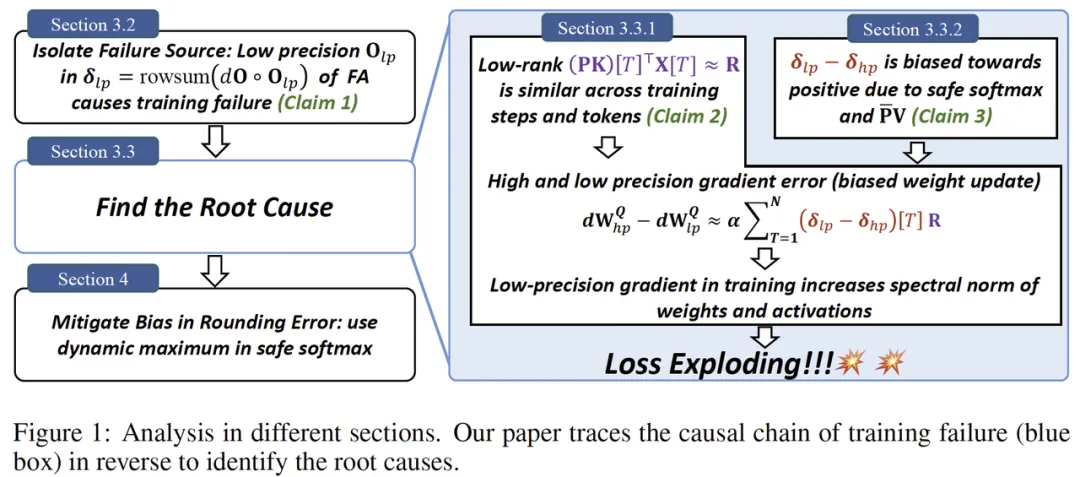
因果链总览(论文 Figure 1)

-
标题:Why Low-Precision Transformer Training Fails: An Analysis on Flash Attention
-
作者:邱海权,姚权铭
-
机构:清华大学 电子工程系
-
投稿:ICLR 2026 Oral
-
关键词:低精度训练,BF16,FlashAttention,数值稳定性,舍入误差(rounding error),低秩表示(low-rank)
-
论文链接:https://arxiv.org/abs/2510.04212
-
代码链接:https://github.com/ucker/why-low-precision-training-fails
背景:低精度训练越来越 “刚需”,但注意力比你想的更敏感
大模型训练的现实是:显存和吞吐决定一切。工业界普遍在混合精度里使用 BF16/FP16,甚至把 FFN 推到 FP8,以换取更高的训练效率。但工程实践同样残酷:越接近 “极限精度”,训练越容易出现难以解释的不稳定。
Flash Attention 是长上下文训练的关键加速组件,几乎成了标配。问题在于,社区长期存在一个可复现却难以解释的失败案例:
-
用 FlashAttention + BF16 训练 GPT-2,一开始正常收敛,但在几千 step 之后突然 loss 爆炸。
-
你可以通过回退到标准注意力、或把关键计算提高到 FP32 来 “救火”,但代价是吞吐和显存优势没了。
这类问题被报告了多年(相关 issue 在多个开源项目里反复出现),却一直缺少一条能 “从数值误差一路解释到 loss 爆炸” 的机制链。
论文做了什么:把 “锅” 一步步缩小到 FlashAttention 反传里的一个 ![]() 项
项
作者的做法很工程,且足够 “可复现”:
1. 严格复现失败:GPT-2(12 层、12 头、d=768、context=1024),OpenWebText 预训练;并且通过记录并重放相同的数据 batch 序列,把数据顺序带来的随机性排除掉。
2. 定位到层、头:用谱范数(spectral norm)等指标快速缩小范围,发现异常主要来自某一层注意力模块,甚至少数几个 attention head。
3. 定位到一个关键中间量:FlashAttention 反向传播为效率会计算![]()
论文发现:只要让这里用到的 ![]() 走一条更 “高精度 / 等价但不同数值路径” 的计算方式,训练就能恢复稳定。换言之,训练炸掉的导火索并不是 “整个低精度训练”,而是非常具体的:低精度下
走一条更 “高精度 / 等价但不同数值路径” 的计算方式,训练就能恢复稳定。换言之,训练炸掉的导火索并不是 “整个低精度训练”,而是非常具体的:低精度下![]() 的数值误差进入
的数值误差进入 ![]() ,污染后续梯度。
,污染后续梯度。
机制解释 1:相似低秩结构,让误差变成 “持续推力” 而不是噪声
定位到![]() 之后,关键问题变成:为什么一个看似很小的数值误差,能在训练中被放大到灾难?
之后,关键问题变成:为什么一个看似很小的数值误差,能在训练中被放大到灾难?
论文把高精度(hp)与低精度(lp)的梯度差写成一种很直观的形式:梯度误差与 ![]() 成正比,并被注意力里的某些项调制。进一步分解后,误差更新可以近似看作许多 rank-1 项的叠加;更关键的是,作者在实证中观察到:
成正比,并被注意力里的某些项调制。进一步分解后,误差更新可以近似看作许多 rank-1 项的叠加;更关键的是,作者在实证中观察到:
-
不同 token、不同训练 step 下,相关的矩阵结构出现了强相似性,可以抽象为一个共同的低秩方向 R。
-
如果
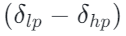 的系数在统计上还出现偏置(不是围绕 0 对称波动),那么误差不会抵消,而会沿着 R持续累积。
的系数在统计上还出现偏置(不是围绕 0 对称波动),那么误差不会抵消,而会沿着 R持续累积。
结果就是:权重更新被 “带偏”,谱范数和激活异常增长,最终把训练推到 loss 爆炸。
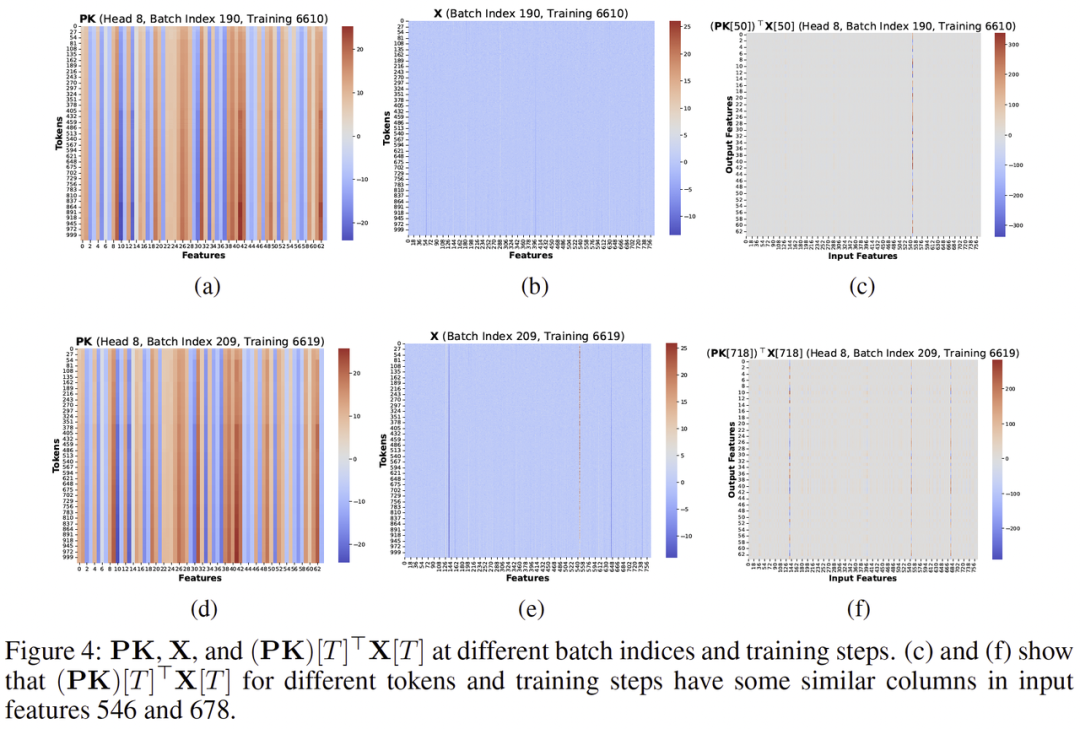

低秩结构相似性与偏置累积(论文 Figure 4/5)
机制解释 2:偏置从哪来?safe softmax + BF16 舍入误差里藏着一个 “离散触发器”
第二条链更 “反直觉”,但也更关键:为什么![]() 会偏向同一方向?
会偏向同一方向?
作者把问题追到了 FlashAttention 前向里的未归一化输出:
-
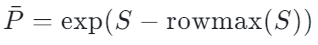 (safe softmax 的常见写法)
(safe softmax 的常见写法) -
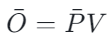
-

论文的关键观察是:![]() 在 BF16 下会出现系统性偏差,并且偏差的触发条件很具体:
在 BF16 下会出现系统性偏差,并且偏差的触发条件很具体:
触发条件:一行 score 出现 “多个相同最大值”,![]() 里会出现多个精确的 1
里会出现多个精确的 1
当 S 的某一行里,有不止一个位置等于行最大值时,这些位置在指数里都会变成 ![]() ,也就是:
,也就是:![]() 中会出现多个精确的 1(不是接近 1,而是 float 表示上真的等于 1)。
中会出现多个精确的 1(不是接近 1,而是 float 表示上真的等于 1)。
这看上去像个细节,但它会把后续 ![]() 的点积推到一个危险区间。
的点积推到一个危险区间。
偏置来源:当 ![]() 且某些维度的 V 以负数为主时,BF16 加法会系统性 “越加越负”
且某些维度的 V 以负数为主时,BF16 加法会系统性 “越加越负”
在某些特征维度上,V [:, i] 的分布可能以负数为主。此时当![]() ,乘积项就是 V [t,i] 本身(负的 BF16 数)。多个负数在 BF16 的加法舍入中会更容易触发尾数溢出、右移与 sticky bit 相关的舍入行为,导致误差贡献出现不对称,表现为:
,乘积项就是 V [t,i] 本身(负的 BF16 数)。多个负数在 BF16 的加法舍入中会更容易触发尾数溢出、右移与 sticky bit 相关的舍入行为,导致误差贡献出现不对称,表现为:
-
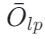 相对
相对 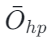 更倾向于 “偏负”
更倾向于 “偏负” -
如果上游梯度
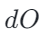 在对应维度也倾向为负,那么在
在对应维度也倾向为负,那么在  里就会形成偏正的误差项
里就会形成偏正的误差项 -
偏正的
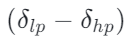 再去驱动前一节提到的相似低秩方向 R,就形成 “越训越偏” 的闭环
再去驱动前一节提到的相似低秩方向 R,就形成 “越训越偏” 的闭环

当 ![]() 出现时,
出现时,![]() 的误差会发生明显 “负跳变”(论文 Figure 6)
的误差会发生明显 “负跳变”(论文 Figure 6)
极简修复:让 ![]() 永远严格小于 1
永远严格小于 1
既然问题的离散触发器是 ![]() 中出现精确的 1,作者给出的修复思路非常直接:
中出现精确的 1,作者给出的修复思路非常直接:
-
检测一行 S 中最大值是否出现多次
-
一旦出现 “重复最大值”,就动态调整 safe softmax 的行移位常数 m,让最大位置的指数也变成严格小于 1
论文给出的实现(概念上)如下:
rm = rowmax (S)
rs = rowsum (S == rm) # 最大值出现次数
if rs > 1 and rm > 0: m = β * rm (β > 1)
if rs > 1 and rm < 0: m = 0
else: m = rm
Pbar = exp (S - m) # 从而 max (Pbar) < 1
这一步在精确算术下不改变注意力结果(softmax 对 “整行减常数” 不敏感),但在有限精度下能避免 ![]() 触发后续 BF16 累加的偏置舍入,从根上切断误差链。
触发后续 BF16 累加的偏置舍入,从根上切断误差链。
实验结果:稳定训练不再 “突然炸”
论文在 BF16 设置下验证了上述分析与修复:
-
GPT-2S:使用修改后的 FlashAttention,在 AdamW 与 Muon 两种优化器下,都能稳定训练到 600K steps
-
GPT-2M:同样能在 AdamW 下稳定训练(论文展示到 100K steps)
-
论文还提到该现象与结论在多种硬件上保持一致(包括 A100、RTX 4090、Ascend 910B)
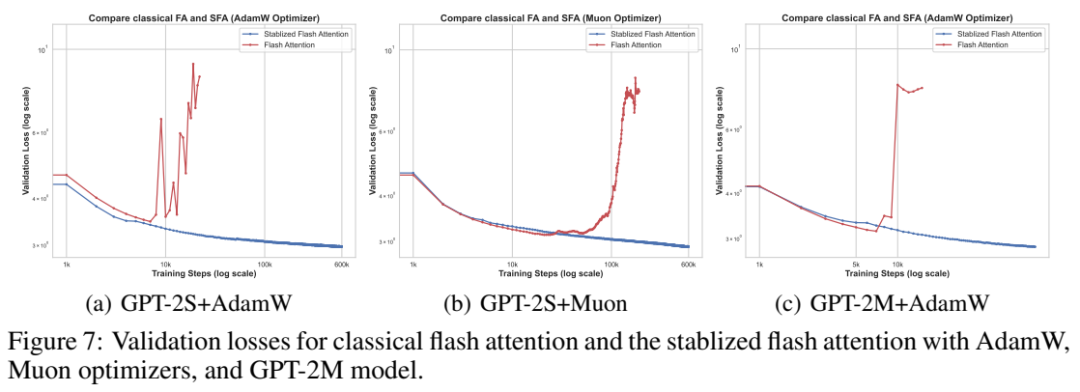
验证集 loss 曲线对比(论文 Figure 7)
更重要的启示:别把低精度误差当成 “零均值噪声”
这篇论文的价值不只在 “修了一个 bug”,更在于给出了一个可迁移的诊断范式:
-
数值误差未必是随机噪声。在特定分布与离散事件(如重复最大值、概率精确为 1)下,舍入误差可能形成系统性偏置。
-
模型结构会放大偏置。注意力里涌现的相似低秩更新方向,让偏置误差更容易 “同向叠加”。
-
经验修复为什么有效也能被解释:论文讨论了 attention sinks 与多最大值的关系,并给出了一个数值层面的连接;同时也指出一些稳定化技巧(如 QK normalization、Gated Attention)可能通过 “打散结构相似性” 来阻止误差同向累积。
作者介绍
邱海权是清华大学在读博士研究生,研究方向涵盖机器学习理论、表示学习与大模型机制分析。他的研究围绕模型表达能力、结构归纳偏置以及参数空间几何与优化动力学之间的内在联系展开,关注模型在不同结构约束与训练条件下的泛化行为与可组合性问题。整体上,他强调以可分析的理论框架刻画模型的能力边界与机制来源,从结构与原理层面理解深度模型为何有效、何时失效。
姚权铭,清华大学电子工程系副教授。长期致力于数据高效学习与智能体系统研究,在少样本学习、图学习、知识图谱与生物医药智能等方向取得系统性成果。发表 Nature 子刊、TPAMI、JMLR、ICML、NeurIPS、ICLR 等论文 130 余篇,被引 1.4 万余次。代表性工作包括抗噪学习算法 Co-teaching、小样本学习综述、自动化图学习方法及新药物相互作用预测模型。现任 TPAMI、TMLR 编委及 Neural Networks 资深编委,多次担任 ICML、NeurIPS、ICLR 领域主席,入选 IEEE Computing Top 30、IET Fellow 等。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com