Anthropic团队揭秘Claude Code构建经验:像Agent一样思考,根据模型能力进化工具,利用搜索构建上下文,避免工具膨胀。
原文标题:构建Claude Code的经验教训首次揭秘了!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到,随着模型能力的提升,曾经有用的工具可能会变成束缚。那么,如何判断一个工具是否已经过时?有哪些指标可以参考?
3、文章强调了“渐进式披露”的重要性,认为它可以避免工具膨胀。在实际应用中,如何设计一个好的“渐进式披露”策略?需要考虑哪些因素?
原文内容

本文约2500字,建议阅读5分钟Claude Code究竟是如何炼成的?
Claude Code究竟是如何炼成的?
近日,Anthropic团队成员Thariq发文,首次揭秘了开发Claude Code过程中悟出的四条实战经验,一天就被300万人围观,近万人赞同。
文章聚焦于一个核心问题:怎么给 Agent 设计工具?
Thariq 的观点很直接:给模型设计工具既是科学也是艺术。它没那么多死板的规则,关键是学会像Agent一样思考。
下面我们看他具体是怎么说的:
构建Agent最难的部分之一,是设计它的行动空间(action space)。
Claude通过工具调用(Tool Calling)来行动,而在API层面,这些工具可以用不同形式构建——bash命令、skills、还有最近新增的代码执行。
工具这么多,该怎么选?Agent需要多少个工具?是只用代码执行或bash就够了,还是像瑞士军刀一样准备50个工具应对各种场景?
要理解这个问题,我喜欢把自己代入模型的视角。想象你拿到一道复杂的数学题——你需要什么工具来解它?
这取决于你自己的能力水平。
纸笔是底线,但手算太慢。计算器更好,但你得会用那些高级功能。最快最强的当然是电脑,但你得会写代码、会执行。
用这个框架来设计Agent工具很管用:给它的工具要贴合它自身的能力。但你怎么知道它有什么能力?你得观察,读它的输出,做实验。学会像Agent一样思考。
下面是我们观察Claude、开发Claude Code过程中学到的一些经验。
一、要提升向用户提问的能力,去优化信息获取
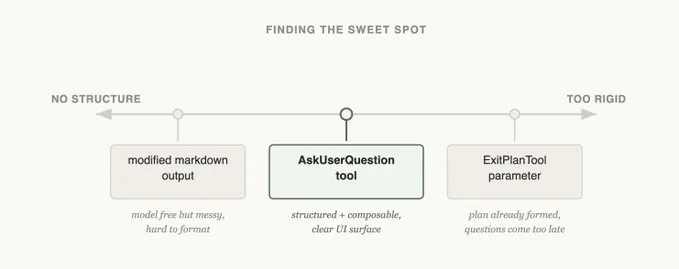
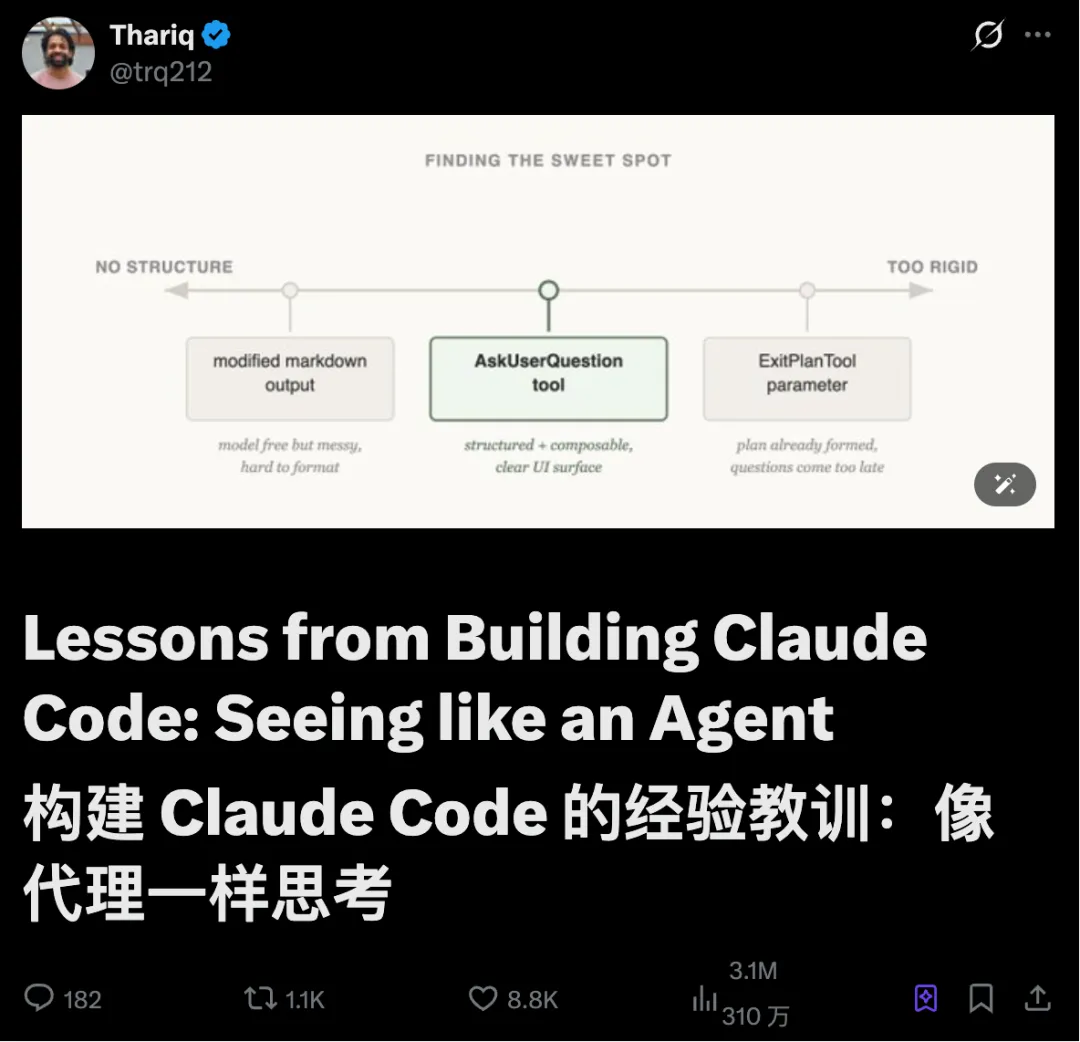
做AskUserQuestion工具时,我们的目标是提升Claude的提问能力(elicit)。
Claude当然可以直接用文字提问,但我们发现回答这些问题总要多花不少时间。怎么降低摩擦、提升用户和Claude之间的沟通带宽?
第一次尝试:改ExitPlanTool
最先试的是在ExitPlanTool上加一个参数,让工具同时输出计划和问题列表。实现起来最简单,但把Claude搞懵了——我们同时要它给计划,又要它问关于计划的问题。那如果用户的回答和计划冲突怎么办?Claude要调两次ExitPlanTool吗?看来得换个思路。
第二次尝试:改输出格式
接下来我们试着改Claude的输出指令,让它用一种变体的markdown格式来提问。比如让它输出带选项的bullet point问题列表,然后我们解析格式、渲染成UI。
这是改动范围最小的方案,Claude也确实能按格式输出。但问题是不稳定——它总会多 append 几句话、漏掉选项、或者干脆换种格式。
第三次尝试:AskUserQuestion工具

最后我们做了个独立工具,Claude随时都能调用,但特别鼓励它在plan模式下使用。工具触发时,我们会弹出一个模态框展示问题,然后阻塞Agent循环,等用户回答。
这个工具让我们能要求Claude输出结构化内容,确保给用户多个选项。用户也能在Agent SDK里调用它,或者在skills里引用。
最重要的是,Claude似乎很喜欢调这个工具,而且输出效果确实好。设计得再好的工具,如果模型不知道怎么用,也是白搭。
这是不是Claude Code里信息获取的最终形态?我们不确定。就像下个例子要讲的,适合一个模型的方案,不一定适合另一个。
二、要跟着模型的能力,去进化工具
Claude Code刚上线时,我们发现模型需要一个Todo列表来保持专注。可以在开始时写个todo,做完一项勾一项。于是我们做了Claude TodoWrite工具,让它写或更新todos并展示给用户。
但即使这样,我们还是经常发现Claude忘事。为了应对,我们每5轮对话就插入一次系统提醒,让Claude记住目标。
但随着模型变强,它们不仅不需要被提醒看todo list,反而会觉得这玩意儿碍事。被提醒看todo,会让Claude觉得自己必须死守列表,而不是灵活修改。我们还发现Opus 4.5在用subagent上强了很多,但多个subagent怎么共享一个todo list?
看到这些,我们把TodoWrite换成了Task工具。
如果说Todos是为了让模型保持专注,那Tasks更多是帮Agent之间互相协作。Tasks可以有依赖关系、跨subagent同步更新、模型也能修改和删除它们。
模型能力在涨,你曾经给它的工具,现在可能反而成了束缚。 要经常回头看之前的假设是否还成立。这也是为什么要尽量只支持一小批能力相近的模型。
三、要设计搜索交互,让Agent自己构建上下文
对Claude来说,有一类工具特别重要——搜索工具,用来帮它自己构建上下文。
Claude Code刚发布时,我们用RAG向量数据库(RAG vector database)来找上下文。RAG又快又强,但需要建索引、做配置,在不同环境下还很脆弱。更重要的是,上下文是我们塞给Claude的,不是它自己找的。
但既然Claude能搜网页,为什么不能搜代码库?给了Claude Grep工具,它就能自己搜文件、自己构建上下文了。
我们观察到一个模式:Claude越变越聪明,只要给它对工具,它就越擅长自己构建上下文。
推出Agent Skills时,我们把渐进式披露正式化了——Agent可以通过探索,逐步发现相关的上下文。
Claude能读skill文件,这些文件又能引用其他文件,模型可以递归地读下去。实际上,skills的一个常见用法就是给Claude加搜索能力,比如教它怎么用某个API、怎么查询数据库。
一年时间,Claude从完全不会自己构建上下文,进化到能跨多层文件做嵌套搜索,精准找到需要的上下文。
渐进式披露现在成了我们添加新功能的常用技巧,不用再加新工具了。
四、要避免工具膨胀,让信息逐步显现
Claude Code目前有大概20个工具,我们一直在问自己:真的需要这么多吗?加新工具的门槛很高——每多一个选项,模型就要多思考一层。
比如,我们发现Claude对自己怎么用Claude Code了解不够。问它怎么加MCP、斜杠命令是干嘛的,它答不上来。
我们可以把这些信息全塞进系统prompt,但用户很少问这些,只会徒增上下文噪音,干扰Claude Code的主业——写代码。
于是我们试了渐进式披露:给Claude一个文档链接,它可以加载并搜索更多信息。这能跑通,但我们发现Claude会加载大量结果进上下文,其实用户只想知道答案。
于是我们做了Claude Code Guide subagent。当用户问关于Claude Code自身的问题时,Claude会被prompt去调这个subagent。Subagent有详细的指令,教它怎么高效搜文档、该返回什么。
虽然不完美——问Claude怎么配置它自己时,它还是会懵——但已经比原来好多了。我们用这种方式扩展了Claude的行动空间,却没加新工具。
学会像Agent一样思考
如果你在等一套 rigid 的工具设计规则,那这篇文章帮不了你。给模型设计工具,既是科学也是艺术。它高度依赖你在用什么模型、Agent的目标是什么、它运行在什么环境。
多做实验,多读输出,多尝试新东西。学会像Agent一样思考。
