英伟达DreamZero登顶机器人双榜,研究表明数据分布、模型规模和视频预测或是成功的关键。
原文标题:训练机器人方式对了吗?英伟达DreamZero双榜第一新反思
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到“也许从另一种机器人身上额外增加 1 万小时的数据,并不一定比使用手头那些廉价、充足的第一视角视频数据更有效”。这句话对机器人研究有哪些启示?对于数据采集和利用,未来应该更加注重哪些方面?
3、DreamZero 论文中提到模型规模在性能表现上起到了关键作用。那么,在算力资源有限的情况下,如何平衡模型规模和训练效率?除了文中的辅助损失,还有哪些方法可以提高小规模模型的性能?
原文内容
近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。

DreamZero 核心思想是:在同一个模型里,同时预测未来视频和机器人动作。也就是说,DreamZero 让机器人在行动前,先在模型内部想象未来。
但问题也随之而来。
为什么这种边预测世界、边预测动作的设计,会带来如此显著的性能提升?它到底比传统策略模型或世界模型强在哪里?是真正的范式突破,还是数据与模型规模的胜利?
围绕这些问题,近期一篇颇具讨论度的分析文章《Why is DreamZero so good at robotics?》给出了一个更深入的解读:在训练一个通用机器人策略时,你的数据和模型架构需要具备哪些特征?这篇文章的解读,正在对以往的认知提出质疑。
文章作者是一位名叫 Chris Paxton 机器人与人工智能研究者,曾在 Hello Robot 负责具身智能(Embodied AI)方向的研究工作。此前,Paxton 在 NVIDIA Research 以及 Meta 旗下的基础人工智能研究机构 FAIR 工作过。

这篇文章从模型介绍、训练数据分布、模型主干规模、时间上下文长度,以及视频生成作为辅助监督信号等多个维度,拆解了 DreamZero 表现突出的可能原因。
文章地址:https://itcanthink.substack.com/p/why-is-dreamzero-so-good-at-robotics
接下来是文章主要内容。
DreamZero 是什么?
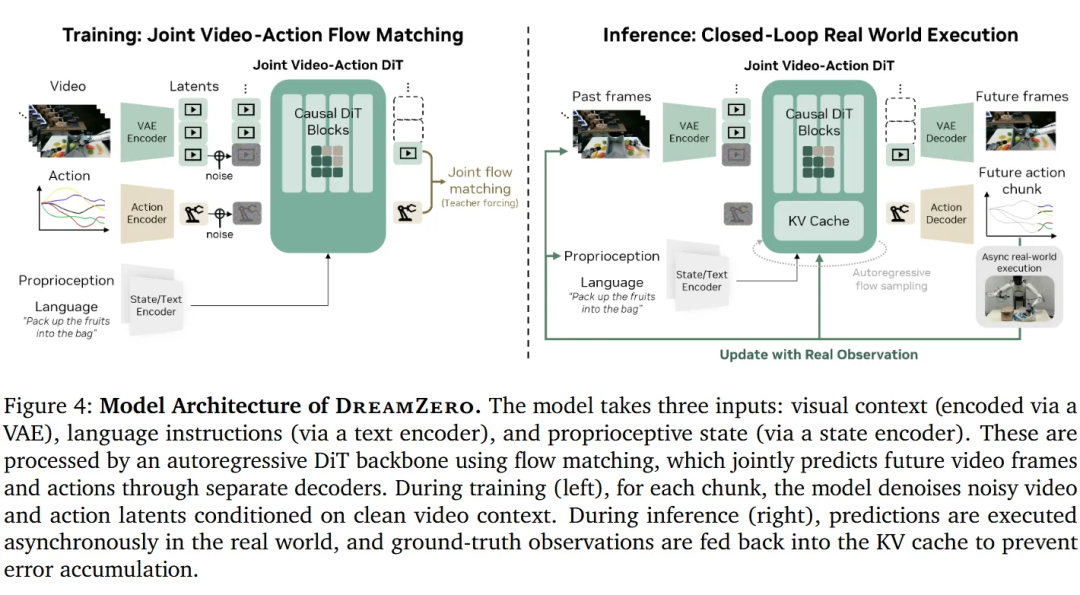
DreamZero 是 NVIDIA 提出的「世界 — 动作模型」(world-action model)。它借鉴了世界模型中的许多核心思想,尤其是视频生成对机器人任务有价值这一理念,但在关键设计上做了几处重要改动。其中最关键的一点是:它联合建模动作生成与视频生成。
通常来说,世界模型大致可以分为两类:
动作条件世界模型:学习状态与动作到下一状态的映射,即 x′=f (x,a)。其中 x 表示当前观测状态,a 表示动作。例如 V-JEPA 2 或近期 RISE 论文中的世界模型就属于这一类。
逆动力学世界模型(inverse dynamics world models):例如 NVIDIA 的 DreamGen 或 1X 的世界模型。这类方法先学习 x′=f (x),然后再通过一个逆动力学模型学习 a=g (x,x′)。
相比之下,DreamZero 更像一个传统的机器人策略模型,但它同时还会预测未来视频。因此,它学习的更接近于:(x′,a)=f (x)。
也就是说,它在同一个模型中同时预测未来状态和对应动作。
我们也可以把它与传统的视觉 — 语言 — 动作模型(vision-language-action model)进行对比:DreamZero 不仅预测动作,还预测未来画面。这为模型提供了一种更丰富的监督信号,不仅告诉它该做什么,还告诉它世界接下来会变成什么样,从而帮助模型更好地学习环境演化的规律。
基准
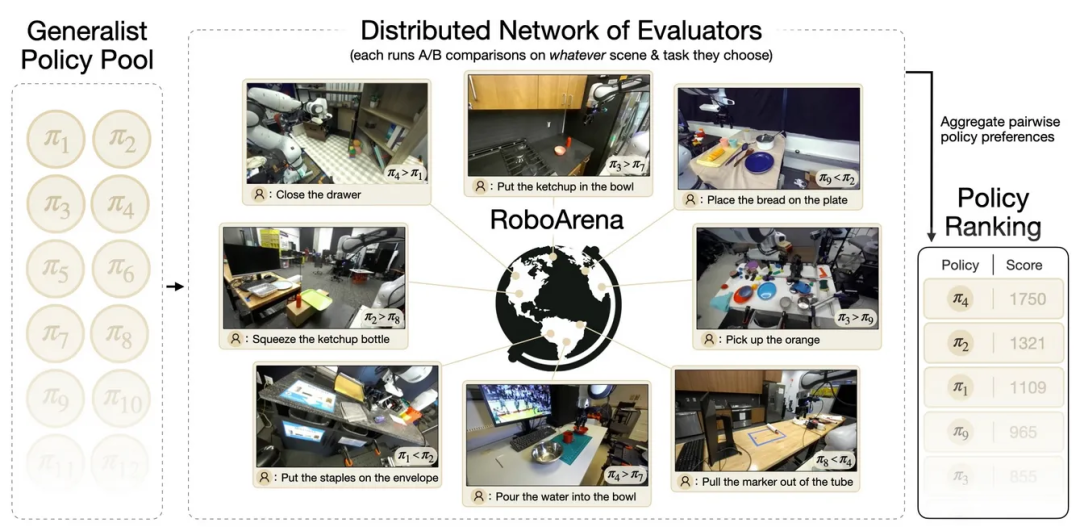
RoboArena 是一个基于 Droid 构建的分布式真实世界基准测试。全球各地的评测者拥有相对相似的机器人和实验设置,并根据不同的自然语言指令,运行一系列开放式的机器人任务评测。
这意味着,从数据分布的角度来看,它在某种程度上属于 DreamZero 的分布内(in-distribution)场景。因为 DreamZero 本身就是在 Droid 数据上训练的,而 Droid 中包含了非常相似的任务和实验环境。但与此同时,这仍然是一个真实世界的评估环境,意味着会存在各种现实中的复杂性和变化;而且具体任务是由评测者自行选择的。
RoboArena 还是一个 head-to-head 式的比较基准,有点类似于在大模型发展中产生重要影响的 Chatbot Arena。

MolmoSpaces 是一个新的基准测试平台,具备高保真物理模拟能力和多样化、程序化生成的环境。
其中,MolmoSpaces-Bench 重点测试在多种受控变化条件下的任务表现,包括抓取(pick)、放置(place)、开合(open and close)等基础操作,以及这些操作的组合任务。
这是一个尚未接近性能饱和的新基准,也就是说,模型之间仍然存在明显差距,仍有较大提升空间。而 DreamZero 在这些测试中都取得了优异表现。
我们能从中学到什么?
我们可以具体对比一下 DreamZero 和 pi-0.5,因为 pi-0.5 是目前排名第二的模型。
训练数据方面
pi-0.5 使用了超过 1 万小时的真实机器人数据、视觉语言模型(VLM)数据,以及 Droid 数据集进行训练。而 DreamZero 则根据不同的模型版本(checkpoint),使用 DROID 数据或 AgiBot 数据进行训练。
训练数据的分布很可能在这里起到了至关重要的作用。可以注意到,在 DreamZero 的论文中,它在 AgiBot 数据集上的表现明显优于 pi-0.5(而 AgiBot 并不包含在 pi-0.5 的训练数据中);但在双方都使用过的 DROID-Franka 设置下,两者的性能差距则要小得多。
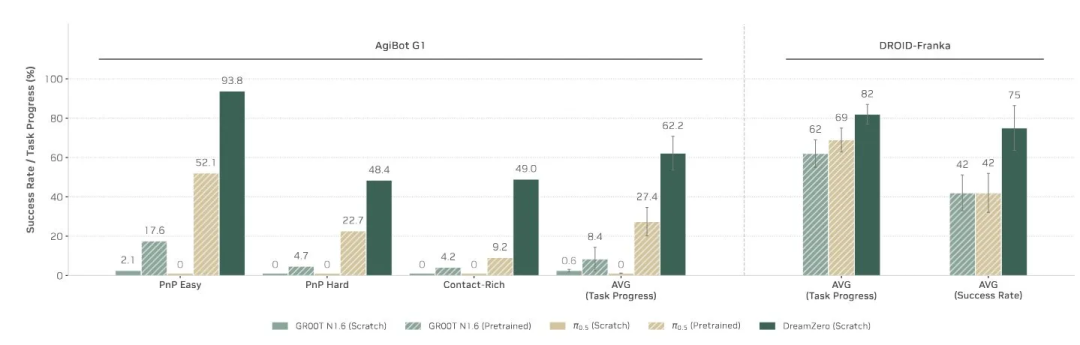
这似乎也在暗示:那额外的 1 万小时机器人数据,可能并不像人们想象中那样万能有效。
更关键的,或许不是数据量本身,而是是否在正确分布的机器人数据上进行预训练。在另一篇近期博客文章中,Physical Intelligence 展示了一个非常显著的结果:当模型在与目标任务分布高度一致的合作方数据上进行预训练时,性能会出现大幅提升。
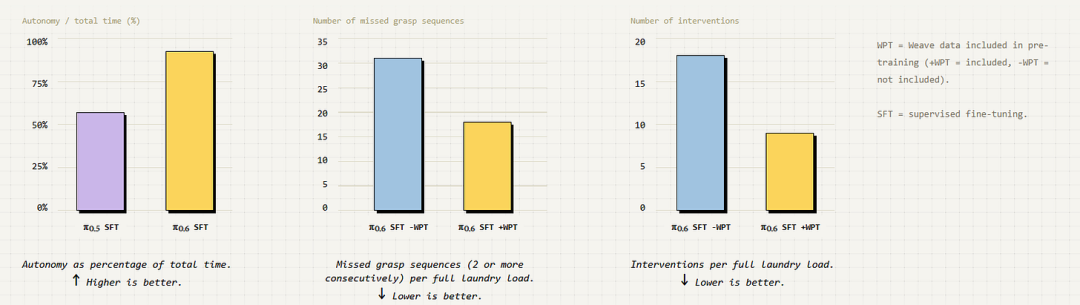
因此,也许从另一种机器人身上额外增加 1 万小时的数据,并不一定比使用手头那些廉价、充足的第一视角视频数据更有效。对于那些希望训练跨机体通用机器人大脑的研究者来说,这可能并不是一个好消息。换句话说,从不同机器人形态中获得的收益,可能并不会比单纯加入大量低成本的第一视角视频数据更多。
模型主干
首先是主干模型规模之差。
DreamZero 基于 Wan2.1-I2V-14B-480P 构建,是一个 140 亿参数的视频生成模型,相比之下,pi-0.5 基于 30 亿参数的开源视觉语言模型 PaliGemma 进行训练,参数规模差了将近 5 倍。
其次是信息输入方式不同。
DreamZero 最多可以接收 8 帧上下文输入,等于让模型看一个短视频片段。pi-0.5 只能输入单帧图像,每次决策只看当前一张照片。
在真实世界中,机器人任务几乎都具备几个典型特征:环境往往是部分可观测的,存在复杂的物理动态过程,并且高度依赖对时间连续性的理解。例如,一扇门可能刚刚被推开了一点、某个物体正在滑动、机械臂上一刻的速度和加速度都会影响下一步动作的结果。
如果模型只能看到单帧图像,它往往无法判断物体是在运动还是静止,也难以推断当前状态是否由之前的动作所引发,更无法理解惯性等物理效应。
而如果模型能够观察连续的多帧画面,比如 8 帧历史信息,它就能捕捉到运动趋势和状态变化,更容易学习到潜在的物理规律,从而在控制和决策上表现得更加稳定和准确。
模型规模
DreamZero 是一个体量巨大的模型,而论文中相当一部分工作其实是在解决如何让这个 140 亿参数的庞然大物实现实时运行。论文中的消融实验似乎表明,模型规模在性能表现上起到了非常关键的作用。
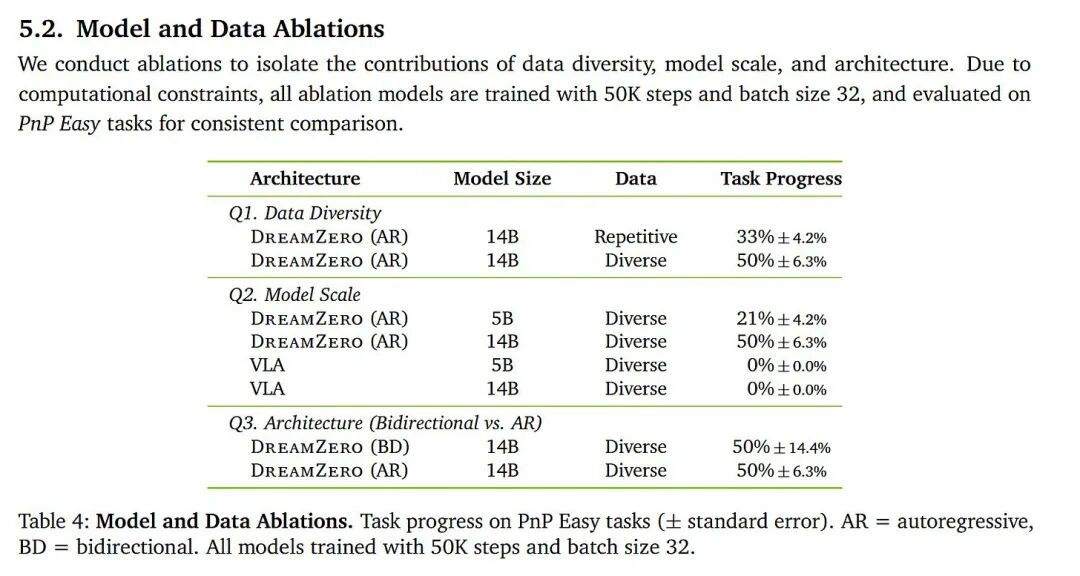
同时引入更长的历史信息、扩大模型规模,通常都会带来一个问题:模型更难训练,而且在低数据环境下更容易过拟合。与大语言模型不同,后者由于拥有海量数据,几乎不用担心过拟合问题。机器人领域本质上始终处于一个低数据环境中。即便是现在,DROID 数据集相比最小规模的 LLM 数据集,也依然小得多。
因此可以提出一个猜想:视频生成目标在这里充当了一种辅助损失(auxiliary loss)。它为 DreamZero 模型施加了一种结构约束,迫使模型学习某种内部的世界模型。与来自机器人动作的稀疏信号相比,视频预测提供了一种更强、更密集的监督信号。这可能使模型更容易适应那些它并未直接训练过的、多样化的 MolmoSpaces 环境。
最后的思考
仅凭这些论文,我们仍然无法得出全部结论。我们无法获得 Physical Intelligence 所使用的全部数据;NVIDIA 用于推理的 GB200 设备目前也并不容易获取。但对很多人来说,可以得出一个经验,也许我们并不需要此前认为那么多的数据,就能够在真实世界机器人任务中取得强劲表现。
最后,作者表示,接下来几周会推出一期 RoboPapers 播客节目,专门讨论 DreamZero;此外,下周也会发布一篇更深入的分析报告,感兴趣的读者可以关注一下。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com