ReLE 评估范式深度诊断中文大模型能力各向异性,揭示榜单排名不稳定性,为企业提供更精准的模型选择依据。
原文标题:告别刷榜!ReLE 为大模型做全维度深度体检
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到 ReLE 系统能够显著降低评估成本,其核心技术是“动态方差感知调度器”。这个调度器具体是如何工作的?它在保证评估准确性的前提下,是如何做到降低成本的?
3、ReLE 系统中使用了“符号-落地混合评分机制”,目的是为了解决“LLM 裁判”可能存在的偏好偏差。这种机制是如何具体运作的?它相比于传统的 Embedding 相似度匹配,有哪些优势?
原文内容

本文约2200字,建议阅读5分钟本文介绍 ReLE 评估范式,破解大模型评价危机,深度诊断其能力各向异性。
当 C-Eval、CLUE 等传统榜单逐渐饱和,单纯的“高分”是否还能代表“高能”?
近日,来自非线智能、中山大学、港科大、华为、NSFOCUS、中国平安等机构的研究团队提出了一种全新的评估范式—— ReLE(Robust Efficient Live Evaluation)。
该研究不追求单一的排名,而是通过动态方差感知调度器和正交能力矩阵,对 304 个中文大模型进行了“核磁共振”般的深度诊断。
研究发现,当前模型的排名稳定性(RSA)极差,单纯的标量分数正在掩盖模型严重的“偏科”问题。
随着中文大模型(LLMs)生态的爆发,每个月都有 10-15 个新模型问世。
然而,行业正面临一场“评价危机”:主流基准测试(如 CLUE,C-Eval,AGIEval)的分数分布正在坍缩,GPT-5 和 Gemini 3 Pro 等 SOTA 模型已触及天花板,导致榜单失去了区分度。
更严重的是,传统的静态榜单往往隐含着“通用智能因子(g-factor)”的假设,试图用一个标量分数总结模型的全部能力。

论文标题:
ReLE: A Scalable System and Structured Benchmark for Diagnosing Capability Anisotropy in Chinese LLMs
论文链接:
https://arxiv.org/abs/2601.17399
Github项目链接:
https://github.com/jeinlee1991/chinese-llm-benchmark
在最新发布的论文中,非线智能联合研究团队指出:现代大模型并非“全能”,而是呈现出显著的能力各向异性(Capability Anisotropy)——即为了优化某一领域(如法律)往往牺牲了另一领域(如逻辑推理)的能力。
研究团队提出了一个新指标:排名稳定性幅度(RSA)。简单说,就是当我们根据需求调整考察重点(比如“我更看重逻辑推理”或“我更看重医疗知识”)时,模型排名的波动有多大。
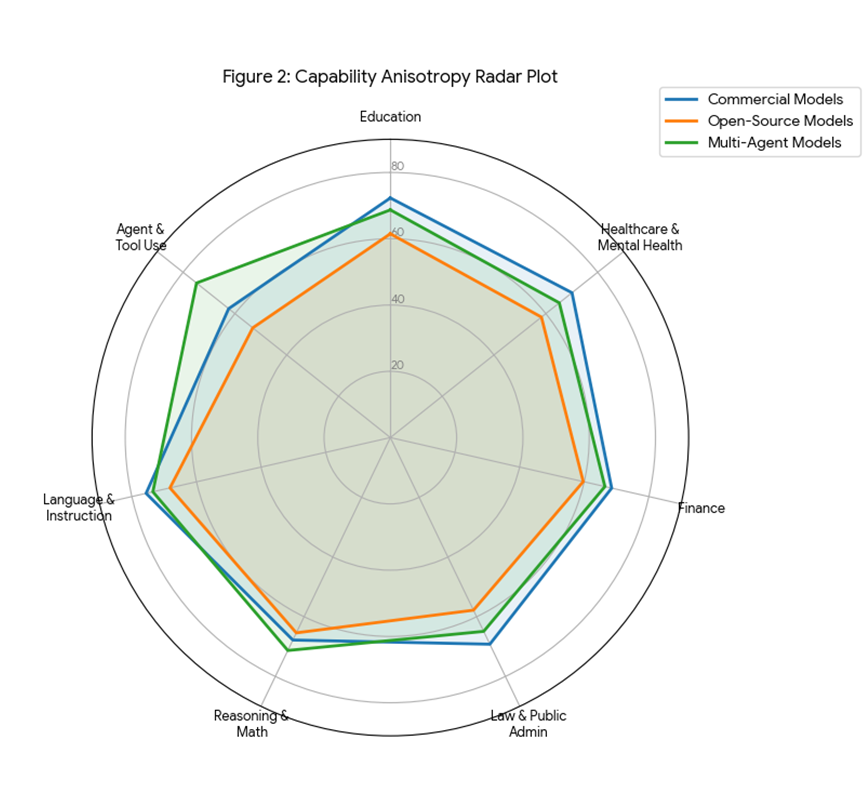
为了量化这种不平衡和排名波动性并解决全量评估的高昂成本,团队构建了 ReLE 系统。
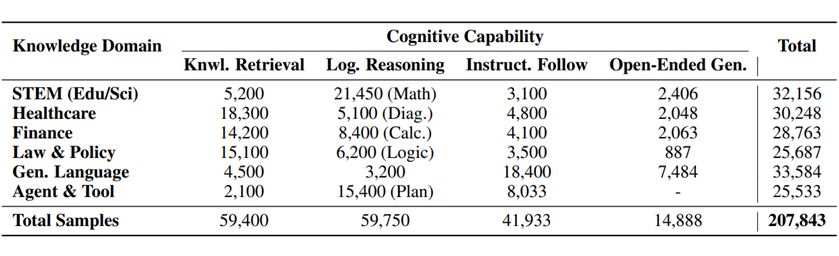
该系统评估了 304 个模型(含 189 个商业模型与 115 个开源模型),覆盖 207,843 个样本,在保证排名相关性( )的同时,将评估算力成本降低了 70%。
1、核心方法论:从“静态刷榜”到“动态诊断”
ReLE 并不仅仅是一个新的数据集,而是一套完整的评估系统架构,其核心技术贡献集中在以下三个维度:
1. 动态方差感知调度器(Dynamic Variance-Aware Scheduler)
面对 300+ 模型和数十万样本,传统的全量评估成本高达 6.9 万美元,且耗时极长。
ReLE 将评估形式化为一个分层序贯估计(Stratified Sequential Estimation)问题,引入了基于 Neyman 分配的两阶段采样策略 :
-
方差探测(Stage 1):对每个模型进行小样本探测,计算其在特定维度上的性能方差 。
-
动态分配(Stage 2):根据方差大小动态分配测试预算。对于表现稳定的模型(方差趋近于 0),系统自动剪枝冗余样本;而对于处于“能力边界”的高方差模型,则分配更多计算资源。
这一机制使得 ReLE 能够像计算机自适应测试(CAT)一样,以最小的计算代价捕捉模型的真实能力边界,将总评估成本压缩至 20,700 美元。
2. 符号-落地混合评分机制(Symbolic-Grounded Hybrid Scoring)
为了解决 “LLM 裁判” 可能存在的自我偏好偏差(Self-Preference Bias)和嵌入相似度匹配的假阳性问题,ReLE 设计了一套严密的评分流水线:
-
客观任务(68%): 对于数学和逻辑题,采用符号求解器(如 SymPy)进行确定的等式检查,而非模糊的文本匹配。
-
半客观任务(24%): 摒弃单纯的 Embedding 相似度。ReLE 采用“语义过滤 -> LLM 裁判 -> 偏差校准”的三级级联结构。特别是通过引入对抗样本对 GPT-4o 裁判进行了微调,惩罚“推理幻觉”,使其与人类专家的一致性(Cohen's )达到了 0.81。
3. 领域 x 能力的正交矩阵
不同于以往基准将“医疗”和“推理”混为一谈,ReLE 构建了一个正交矩阵:纵轴为 7 大行业领域(Domain),横轴为 22 个认知能力维度(Capability)。
这使得研究者可以明确区分:一个模型无法回答法律问题,究竟是因为缺乏“法律知识”,还是因为缺乏“逻辑推理”引擎。
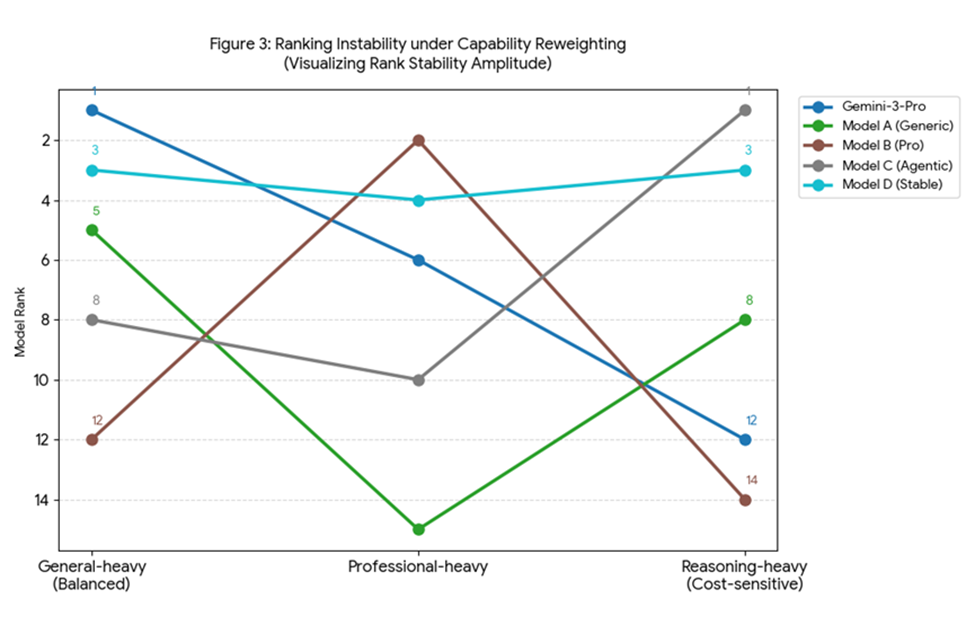
2、深度洞察:排名并不像你想象的那么稳定
基于 ReLE 系统,研究团队揭示了当前中文大模型生态中几个反直觉的现象:
洞察一:排名的剧烈动荡与 RSA 指标
如果在评估中稍微改变一下权重的侧重(例如更看重推理而非知识),模型的排名会发生变化吗?
在传统基准(如 C-Eval)中,这种变化很小,排名稳定性幅度(RSA)仅为 ~ 5.0。但在 ReLE 中,模型的平均 RSA 高达 11.4。这意味着,一个在均衡榜单上排名第 8 的模型,在专业场景下可能会跌至第 32 名。
结论:并不存在一个通用的 “SOTA” 模型。当前的 Leaderboard 排名对权重设置高度敏感,单一的聚合分数具有极大的误导性 。
洞察二:商业模型 vs 开源模型的护城河
-
专业领域:商业模型在医疗、法律等垂直领域依然保持显著优势,平均分差约 12 分。
-
通用推理:顶尖的开源模型正在快速缩小差距,但在处理复杂的长链条推理时仍显吃力。
-
性价比发现:价格并不总是与能力成正比。数据显示,定价在 1-5 元区间的模型,在 22 个维度中的 8 个维度上,表现与高价(>5元)的专有模型相当,差异小于 3.2%。
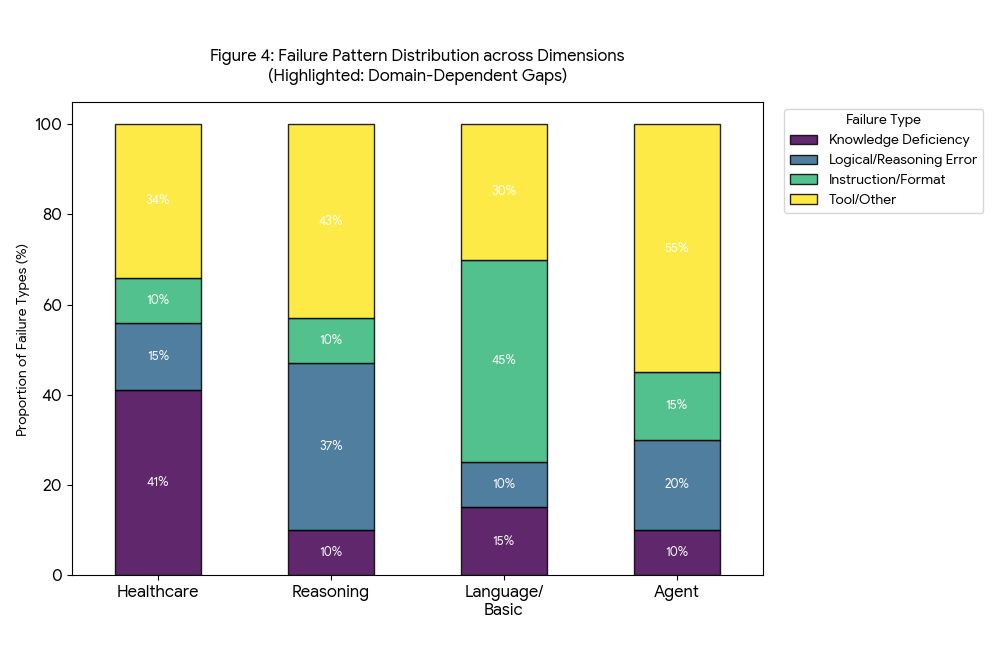
洞察三:Agent 能力的“格式”壁垒
在工具使用(Tool Use)任务上,专门优化的 Agent 模型得分为 74.8,远超通用商业模型的 62.4。
深入分析发现,这并非因为通用模型推理能力弱,而是因为它们在格式对齐(Format Alignment)上存在缺陷——经常输出冗长的解释而非标准的 JSON 调用。这揭示了“潜在能力”与“接口依从性”之间的鸿沟。
3、总结与展望
ReLE 的发布标志着大模型评估正从“静态排行榜”时代迈向“动态诊断”时代。该研究不仅提供了一份详尽的 304 模型体检报告,更重要的是,它证明了“能力各向各性”是当前大模型的固有属性。
对于开发者和企业而言,ReLE 的启示在于:停止寻找那个并不存在的“完美模型”。
未来的 AI 落地将转向“能力组合管理(Capability Portfolio Management)”——根据具体的业务场景(是重推理还是重知识?是重成本还是重精度?),从“偏科”的模型池中选择最合适的工具。
目前,ReLE 团队计划开源其包含 210 万个失败案例的资源库以及评估脚本,以推动社区建立更透明、更具诊断性的 AI 评价体系。
