港科大&字节跳动提出WMPO,一种基于视觉世界模型的VLA强化学习方法,使机器人在“想象”中进化,提升策略性能并涌现自我纠错行为。
原文标题:ICLR 2026|在「想象」中进化的机器人:港科大×字节跳动Seed提出WMPO,在世界模型中进行VLA强化学习
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到WMPO涌现了自我纠错能力,但主要在结构化操作任务中观察到。那么,如何提升WMPO在非结构化环境中的泛化能力?例如,如何让机器人在复杂的家庭环境中,也能像在实验室里一样灵活地纠正错误?
3、WMPO通过视觉世界模型进行训练,是否会受到视觉信息本身的局限性影响?例如,在光照条件变化、物体遮挡等情况下,WMPO的性能会受到怎样的影响?如何解决这些问题?
原文内容

香港科技大学 PEI-Lab 与字节跳动 Seed 团队近期提出的 WMPO(World Model-based Policy Optimization),正是这样一种让具身智能在 “想象中训练” 的新范式。该方法无需在真实机器人上进行大规模强化学习交互,却能显著提升策略性能,甚至涌现出 自我纠错(Self-correction) 行为。该文章目前已被 ICLR 2026 接收,目前,论文、代码与模型均已开源。
论文第一作者朱方琪是香港科技大学博士生,研究方向包括世界模型,具身智能,多模态大模型等。第二作者为香港科技大学研究型硕士生严正阳。通讯作者为香港科技大学计算机科学及工程系讲座教授郭嵩教授以及字节跳动 Seed 团队马骁。

-
论文标题:WMPO: World Model-based Policy Optimization for Vision-Language-Action Models
-
项目网站:https://wm-po.github.io
-
论文链接:https://arxiv.org/abs/2511.09515
-
论文代码:https://github.com/WM-PO/WMPO
传统 VLA 训练的 “紧箍咒”:
模仿易碎,交互昂贵
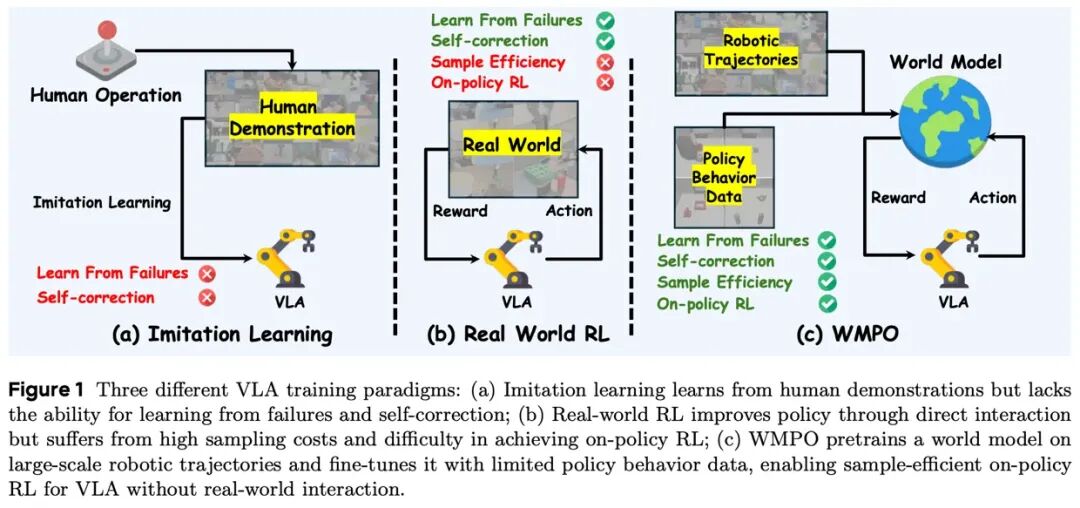
近年来,视觉 - 语言 - 动作(VLA)模型在通用操作任务中展现了令人印象深刻的潜力,但其训练方式长期受制于两大瓶颈。
第一,模仿学习的先天局限。
大多数 VLA 模型依赖专家演示数据进行训练,只学习了 “什么是正确操作”,却几乎没有见过 “犯错之后该怎么办”。在推理时,一旦状态稍微偏离训练分布,错误便会不断累积,最终导致任务彻底失败。这种 “脆弱性” 在长序列操作中尤为明显。
第二,现实强化学习的高昂代价。
强化学习理论上可以解决上述问题,但在真实机器人上进行 RL 交互往往需要数百万次尝试,不仅采样效率极低,还伴随着硬件磨损、安全风险和高昂的实验成本。
已有研究 [1] 尝试借助潜空间世界模型(Latent Space World Model)来缓解现实交互压力,但这类模型通常与预训练 VLA 所使用的真实图像表征存在差异,难以直接用于现有 VLA 框架中的策略优化。
WMPO 的核心突破:
像素级 “想象” 与 Online GRPO
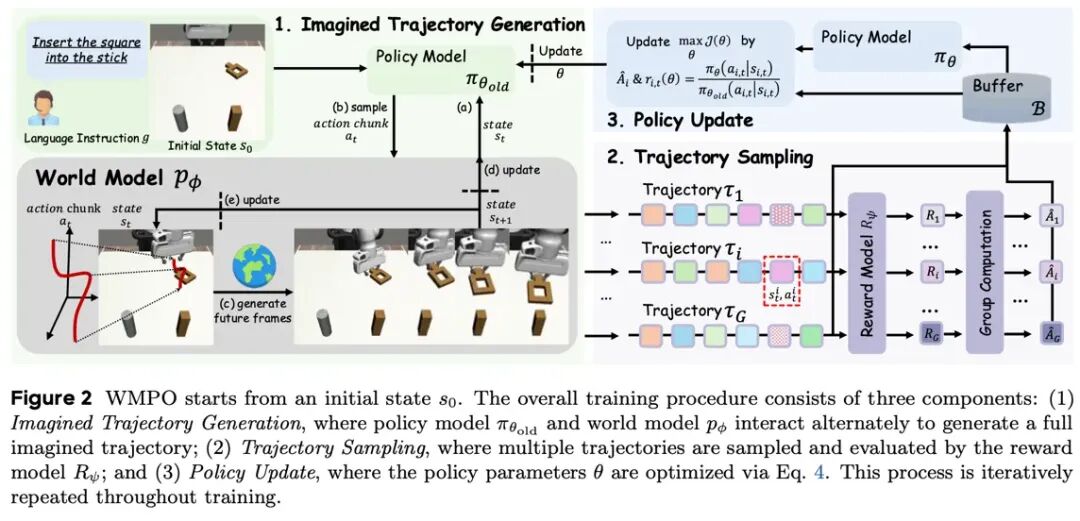
WMPO 提出了一种新的训练范式:将策略优化过程完整地迁移到视觉世界模型中完成,让具身代理在 “想象” 的轨迹中学习如何从错误中恢复。其核心设计包含三个关键要点:
像素级视觉世界模型,让错误也能被真实模拟
与以往在潜空间中进行预测不同,WMPO 构建的是像素级视觉世界模型。模型直接在图像空间中,根据当前观察和动作预测下一帧视觉反馈,从而生成完整的 “想象轨迹”。为了保证世界模型不仅能复现专家行为,还能覆盖策略执行过程中可能出现的各种偏差,研究团队引入了策略行为对齐(Policy Behavior Alignment) 机制:在专家数据预训练的基础上,进一步对策略生成的非专家轨迹进行对齐训练,使世界模型能够准确模拟 OOD 动作及其失败后果。
在想象空间中进行 Online GRPO
在高保真的视觉世界模型中,WMPO 进一步将强化学习过程引入 “想象空间”。具体而言,对于同一初始状态,VLA 模型会在世界模型中生成一组不同的候选轨迹;通过训练得到的奖励函数判断每条轨迹是否成功,并在组内进行相对比较,从而估计优势。这种 Online GRPO(Group Relative Policy Optimization) 的方式不依赖额外的价值网络,显著降低了内存与训练复杂度,同时在长序列生成中表现出更好的稳定性。更重要的是,“组内竞争” 机制使模型能够自动偏好那些即使犯错、也能恢复并完成任务的动作路径。
攻克长时生成难题:让 “想象” 不崩坏
长时间视频预测一直是视觉世界模型面临的核心挑战。为防止想象画面随时间退化,WMPO 引入了:
-
噪声帧增强(Noisy-frame conditioning)
-
帧级动作控制机制
这些设计确保模型在生成数百帧 “想象轨迹” 时,仍能保持画面清晰、动作对齐,为策略优化提供稳定可靠的训练环境。
WMPO 架构解析:
像素级演化,三步跨越现实
构建高保真 “沙盒”:视觉世界模型建模
WMPO 不依赖抽象的隐空间预测,而是通过像素级生成直接模拟物理反馈。给定当前观察 和动作 预测下一帧图像: .

策略行为对齐:为了让世界模型能模拟策略生成的 OOD 动作及其后果,研究团队不仅在专家数据上训练,还针对策略生成的非专家轨迹进行对齐,确保模型能够准确预测 “失败案例”。
策略评价与改进:想象空间内的 Online GRPO
WMPO 针对同一初始状态 ,模型在 “想象” 中生成一组不同的轨迹: .
优势估计通过训练一个奖励函数 ,判断每条轨迹是否成功,并计算组内各轨迹奖励 的相对好坏来估计优势:
这种 “组内竞争” 机制让模型能够自动识别并强化那些能从错误中恢复的动作路径。
学习目标:自监督式参数优化
在 “想象” 出的轨迹上,WMPO 最小化以下目标函数,将 VLA 模型从单纯的模仿者转化为自我进化的决策者:
伪代码算法如下:

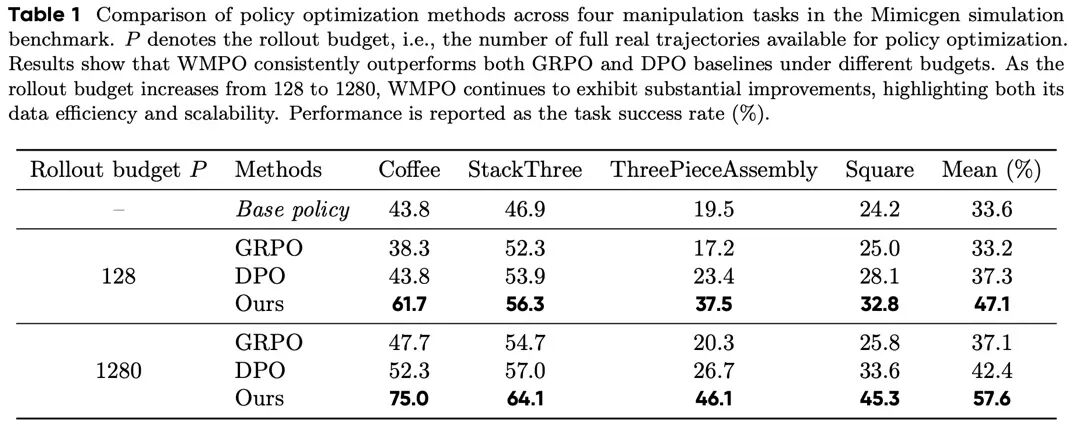
实验结果:样本效率,
涌现能力,执行效率的惊喜
研究团队在 MimicGen 模拟环境和真实 ALOHA 机器人上对 WMPO 进行了系统评估。
采样效率显著提升。
在仅使用 128 条真实轨迹作为数据预算时,WMPO 的成功率已超过最优 Offline RL 基线 9.8%;当预算提升至 1280 条时,领先优势进一步扩大至 15.2%。
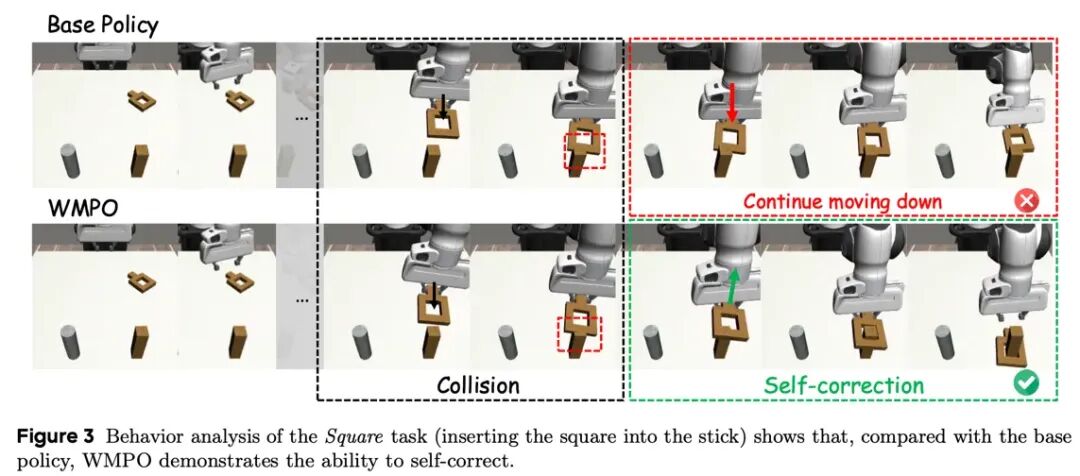
自我纠错行为的涌现。
在 “方块套圈” 等任务中,当基座模型因碰撞或姿态偏移而卡死时,WMPO 训练得到的策略会主动调整动作:例如抬起方块、重新对准目标并再次尝试。这类纠错行为并未出现在专家演示数据中,而是通过 “想象中的失败与比较” 自然涌现。
执行效率更高。
WMPO 训练的策略动作更加连贯、果断,成功轨迹长度明显缩短,减少了犹豫和重复尝试。
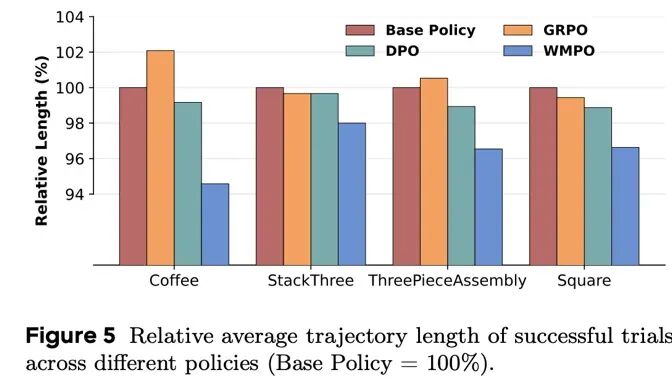
需要注意的是,这种自我纠错能力目前主要在结构化操作任务中被系统观察到,其泛化边界仍有待进一步探索。
启示与展望
WMPO 的成功证明了:高质量的 “想象” 足以替代昂贵的 “实践”。通过将 VLA 的强化学习过程解耦到生成式世界模型中,我们不仅解决了采样效率的难题,更让机器人学会了在挫折中自我完善。
正如达芬奇所言,“简单是终极的复杂”,WMPO 用纯粹的视觉模拟,为具身智能走向通用化指明了一条充满想象力的道路。
更多方法细节与实验分析请见原论文。
[1] Hafner, D., Pasukonis, J., Ba, J. et al. Mastering diverse control tasks through world models. Nature 640, 647–653 (2025). https://doi.org/10.1038/s41586-025-08744-2
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com