AliSQL集成DuckDB,实现MySQL数据高压缩与高效归档分析。通过列式存储、自适应压缩及AliSQL优化,显著降低存储成本,提升查询效率。
原文标题:AliSQL DuckDB:数据压缩与归档分析实践
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章中提到AliSQL对DuckDB的压缩链路进行了优化,包括压缩/编码策略复用、并发路径优化等。这些优化具体是如何实现的?能否举例说明一下,这些优化在实际场景中带来了多大的性能提升?
3、文章提到AliSQL DuckDB引擎为历史数据归档提供了更低的存储占用和更可控的构建成本,同时让归档数据具备可直接承载AP分析的查询效率。那么,对于TP/AP混合型业务,如何合理地利用AliSQL DuckDB来平衡在线事务处理和离线分析的需求?
原文内容

阿里妹导读
书接上文《》,继AliSQL Innovate用户社区大会之后,我们正式开启《DuckDB技术解读》系列。本文为第一篇,聚焦数据压缩与归档能力,详解AliSQL如何通过深度集成DuckDB,在保留MySQL生态兼容性的前提下,原生支持高密度存储与高效分析。
引言
随着业务增长,存储开销与历史数据可分析性往往同时成为瓶颈:一方面,InnoDB 以行存与索引页为核心组织方式,在宽表、日志类与分析型查询场景下磁盘占用上升很快;另一方面,用户又希望把更长周期的数据保留下来用于 AP 分析与追溯,随时查询和复用归档的数据。
AliSQL引入 DuckDB 作为存储引擎,使 MySQL 在归档与分析场景中具备更强的压缩与扫描能力:数据以列式形态组织落盘,并在 checkpoint 写入阶段对每一列执行自适应编码与压缩选择,从而显著降低落盘体积,同时提升面向列扫描的查询效率。在此基础上,AliSQL还对 DuckDB 压缩过程进一步优化,结合存储层硬件压缩能力,进一步降低存储成本。本文将浅析 DuckDB 的压缩原理,并结合对比与实践说明 AliSQLDuckDB 存储引擎对归档与 AP 分析的价值。
DuckDB 中的压缩
DuckDB 中数据压缩过程
DuckDB 的表存储格式可抽象为四个层次:一张表(Table)首先以行(Row)为单位进行横向切分,形成多个 Row Group;每个 Row Group 再以列(Column)为单位纵向切分为多个 Column Data;每个 Column Data 继续以行(Row)为单位横向切分为多个 Column Segment;而 Column Segment 则对应实际落盘的数据单元,通常映射为一个约 256KB 的 Data Block,但在某些情况下也可能与其他 Column Segment 共享同一个 Data Block。
在表存储格式的层级中,DuckDB 数据压缩的处理单位是 Column Data。在 Column Data 内部,与压缩密切相关的成员主要包括三个:检查点状态集 checkpoint_states、压缩函数集 compression_functions 以及压缩分析状态集 analyze_states。其中,checkpoint_states 用于保存列在 checkpoint 过程中的上下文信息;在一般的 Column Data 中,checkpoint_states 的 size 通常为 2:checkpoint_states[0] 关联数据列本身,checkpoint_states[1] 关联校验列(validity)。compression_functions 是一个二维数组,用于保存各列可用的候选压缩函数列表,记作 compression_functions[i][j](第 i 列的第 j 个候选压缩函数)。analyze_states 同样是二维结构,用于保存特定列在特定压缩算法下的分析状态/压缩效果信息,记作 analyze_states[i][j](第 i 列的第 j 个算法的分析状态)。
在真正执行压缩之前,DuckDB 会先通过扫描分析来确定每一列的最佳压缩算法。对于一个 Column Data,选择最佳压缩算法的主要流程可以概括为:
1. 查压缩相关配置。
2. 初始化分析状态集 analyze_states。
3. 遍历该 Column Data 内的所有 Column Segment;在每个 Column Segment 内,遍历其中的各列(即 checkpoint_states 中的列);对每一列,依次使用其候选压缩算法进行分析,并将分析结果写入 analyze_states;若某算法在分析过程中被判定不适用,则会被淘汰。
4. 遍历 analyze_states,对候选算法进行最终评分,选择“得分最低(压缩后空间最小)”的算法作为最佳方案。
5. 返回确定的压缩算法集。
每列可选的候选压缩算法与列的数据类型及相关配置有关,这里不展开。下面用一个简化例子说明 DuckDB 压缩的执行过程,假设表中只有一列 id,类型为 INT,则压缩流程大致如下:
1. checkpoint 会透传到 Column Data 来执行。ColumnDataCheckpointer 创建时会将 id 的数据列和检验列填充到 checkpoint_states 之中。
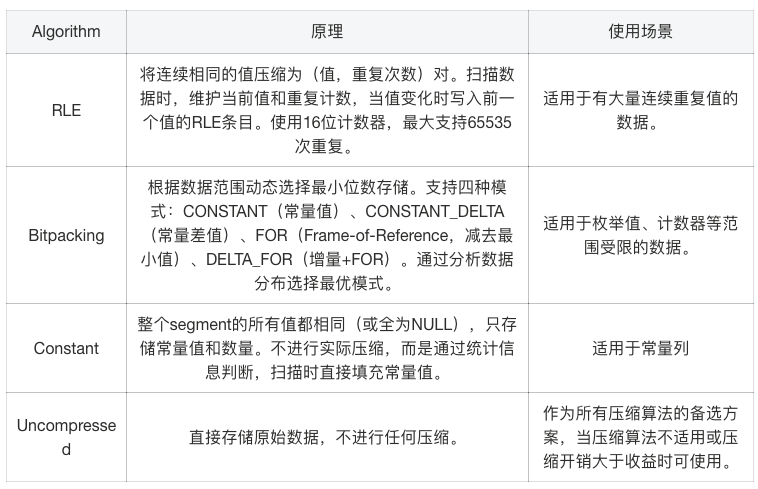
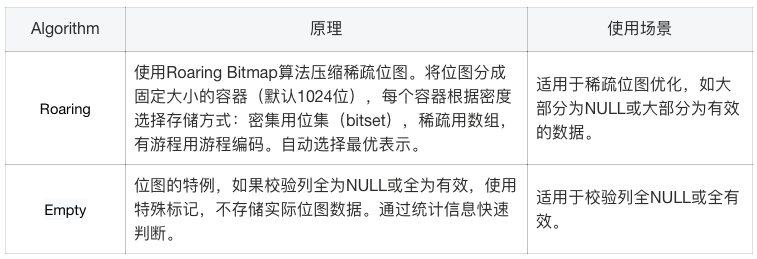
2. 分别初始化这两列候选的压缩函数。如 id 数据列候选的压缩函数可能包括:UncompressedFun、RLEFun、BitpackingFun 和 ZSTDFun,id 校验列候选的压缩函数可能包括 UncompressedFun 和 RoaringFun。
3. 初始化分析状态集。分别对 id 数据列和 id 校验列调用后续的压缩函数集的 init_analyze 接口,完成二维数组 analyze_states 的填充。
4. 扫描数据确定最佳压缩算法。对 id 的数据列依次执行 4 个压缩函数的分析,对 id 的校验列依次执行 2 个压缩函数的分析,将分析结果保存到分析状态集。接着遍历分析状态集,确定各列最优的压缩算法并保存。
5. 数据最终落盘时,将按照此前选定的最佳压缩算法对对应列进行压缩写入。
DuckDB 中的压缩算法
-
数值/布尔类型
-
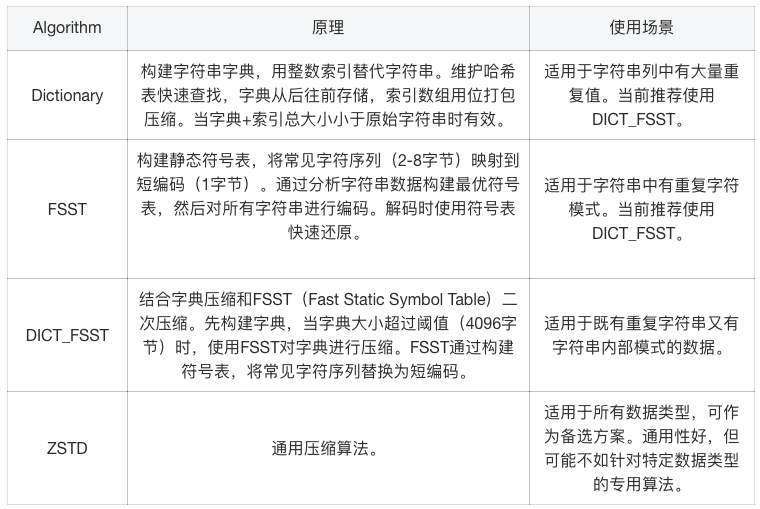
字符串
-
浮点数

-
校验类型
DuckDB 压缩效果
DuckDB 的列式存储与自适应编码/压缩能显著降低数据落盘体积,从而直接带来存储成本与运维成本的下降:例如在 sysbench(25 张表、每表 2000 万行)场景下,InnoDB 约 127GB,而 DuckDB 仅 43GB;TPC-H SF100 场景下,InnoDB 约 168GB,而 DuckDB 仅 26GB。更大规模的生产归档场景中,某本地生活服务平台将 InnoDB 的约 133TB 数据归档到 DuckDB 后仅约 66TB,某互联网消费金融平台从约 94TB 降至约 49TB。上述平台均将 DuckDB 作为归档库并承载 AP 查询,在保持 MySQL 使用习惯的同时,通过更高的压缩率获得更低的存储占用、更高的单位容量性价比,并使长期历史数据的分析查询更具成本优势。
编码与压缩机制和效果对比
在 MySQL 中,业务表通常默认使用 InnoDB 引擎进行存储。InnoDB 属于以 B+Tree 页(page) 为核心组织形式的行存引擎,默认配置下一般不启用压缩,因此在分析型/宽表场景下,数据与索引往往会占用较大的磁盘空间(尽管 InnoDB 也支持如 ROW_FORMAT=COMPRESSED、透明页压缩等能力,但压缩收益、CPU 开销与写放大之间需要权衡,线上一般不开启)。
HBase、ClickHouse 和 Doris(SelectDB)在存储组织上更偏向面向分析的压缩友好形态,但各自路径不同。HBase 基于 LSM-tree(MemStore + HFile)的结构,数据排序和编码后落盘到 HFile,并在 block 级别启用通用压缩(如 LZ4、ZSTD、Snappy 等)。压缩主要发生在块层,收益相对稳定,通常取决于数据的重复度与排序特征。ClickHouse 采用列式存储,列数据数据流/part 持久化。其压缩通常由列级 codec(如 Delta、Gorilla、Dictionary 等变换/编码) 与底层通用压缩算法叠加实现:先对列级数据做更贴合分布特征的编码,再通过通用压缩进一步压缩,从而获得较好的空间效率与扫描性能。Doris(SelectDB) 以列式 segment/page 组织数据,通常会对不同类型/数据分布采用合适的编码(如字典、RLE 等)并结合通用压缩,将数据以更高密度写入磁盘,因此在典型分析型数据集上往往能获得较好的空间节省效果。
OceanBase 在存储层对“编码 + 压缩”的分层设计更细:其 SSTable 内部以 micro block 为基本组织单元,在 micro block 内对列数据进行 encoding(面向类型与分布特征的编码/变换) 以提升可压缩性与扫描效率;当 micro block 聚合并写入 macro block 时会叠加通用压缩,目标是在保证读写效率的前提下尽可能降低磁盘空间占用。
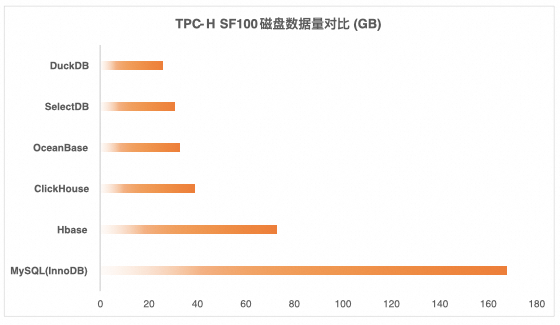
以 TPC-H SF100 为例,不同系统的落盘数据量差异明显:MySQL(InnoDB)约 168GB;而在列式存储的系统中,整体空间占用显著下降,HBase 约 73GB,ClickHouse 约 39GB、OceanBase 约 33GB、SelectDB(Doris)约 31GB。在同一数据集与规模下,DuckDB 仅约 26GB,不仅相较 InnoDB 实现约 6.5 倍的空间节省,也在与多种主流分析型系统对比中具备最低落盘体积,意味着在归档与分析场景下可进一步降低存储成本、提升单位磁盘可承载的数据规模。
AliSQL压缩优化
AliSQL将 DuckDB 作为 MySQL 的存储引擎后,对 DuckDB 的压缩链路做了进一步工程化优化,重点提升写入与构建阶段的吞吐与并发效率,包括:
1. 压缩/编码策略复用:对 DuckDB 在列级别进行的 encoding/compression 策略选择(通常依赖列类型与数据分布特征的统计/采样)进行固化与缓存复用,减少重复探测带来的 CPU 开销与延迟抖动。
2. 并发路径优化:在压缩相关的关键路径中降低锁竞争,提升多线程并发压缩时的吞吐稳定性。
3. 采样与并行化:通过采样降低策略选择/统计的成本,并结合多线程流水线进一步提升压缩阶段整体吞吐,从而加快数据写入与存储构建速度。
此外,AliSQL支持在存储层对用户数据进行压缩存储,以减少写入存储介质的数据量并节省存储空间,使单位容量数据的存储成本最高可降低 50%;该能力基于智能自研硬件芯片与企业级 NAND 闪存介质,在物理磁盘层面实现实时压缩与解压缩,不额外占用实例计算资源,开启后对数据库性能几乎无影响;同时提供数据持久性与稳定性保障。
结语
DuckDB 的压缩优势来自“列式组织 + 自适应算法选择”的组合:以 Column Data 为决策单元,在 checkpoint 过程中对数据列与校验列分别建立候选压缩函数集合,通过扫描分析确定最终方案;结合 RLE、Bitpacking、Dictionary/FSST、ALP/Chimp、Roaring 等针对不同类型与分布特征的专用编码,使数据以更高密度落盘,同时降低分析查询的 I/O 与解码成本。这也是在大规模生产归档中,DuckDB 往往能显著小于 InnoDB 落盘体积的根本原因。
AliSQL 在 DuckDB 高效压缩的基础上进一步优化:通过策略固化与缓存减少重复探测带来的 CPU 消耗与延迟波动,通过并行化与锁竞争优化提升写入与构建阶段吞吐,并可结合存储层硬件压缩继续压缩落盘数据量。AliSQL DuckDB 引擎为历史数据归档提供了更低的存储占用与更可控的构建成本,同时让归档数据具备可直接承载 AP 分析的查询效率,使历史数据的长期存储与低成本分析查询可以在统一的 MySQL 入口与使用习惯下同时实现。
参考
1.
2. https://github.com//oceanbase
3. https://github.com/apache/hbase
4. https://github.com/ClickHouse/ClickHouse
5. https://github.com/apache/doris
6. https://github.com/duckdb/duckdb
7. https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/storage-compression