上海交大、深势科技等开源Innovator-VL科学大模型,无需海量数据,实现多领域科学数据理解和推理,及科学与通用能力融合。
原文标题:完全开源!打破「数据暴力」迷思,上海交大、深势科技等发布 Innovator-VL:开启科学大模型新范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、Innovator-VL 在科学与通用能力之间取得了平衡,这种平衡对于科学大模型的实际应用意味着什么?它会如何影响科研人员使用 AI 的方式?
3、Innovator-VL 团队强调全流程开源,你认为这种做法对科学大模型的发展有哪些积极意义?是否会带来一些潜在的风险或挑战?
原文内容

在通用大模型(LLM)如火如荼的今天,AI for Science(科学智能) 正成为人工智能角逐的下一座高地。
然而,摆在科研人员面前的现实是残酷的:现有的科学多模态模型往往依赖海量且难以获取的数据,且训练过程如同 “黑盒”,难以复现和改进。我们是否真的需要数以亿计的数据才能教会 AI 理解科学?
近日,来自上海交通大学、深势科技(DP Technology)、记忆张量(MemTensor)、中国科学院理论物理研究所等机构的研究团队联合发布了 Innovator-VL。这不仅是一个性能卓越的多模态大模型(MLLM),更是一份献给开源社区的 “科学智能实战指南”。它用事实证明:无需盲目堆砌数据,通过精巧的数据筛选与透明的训练策略,仅需极小的数据量,同样能锻造出顶尖的科学推理引擎。

-
论文链接: https://arxiv.org/pdf/2601.19325
-
代码链接: https://github.com/InnovatorLM/Innovator-VL
-
模型 & 数据链接: https://huggingface.co/collections/InnovatorLab/innovator-vl
-
主页链接: https://innovatorlm.github.io/Innovator-VL
科学发现的 「新眼睛」:Innovator-VL 是什么?
Innovator-VL 是一款专为科学领域定制的多模态大模型。它不仅能看懂日常图像,更能深度理解化学结构、物理公式、生物图像等多领域的复杂科学数据。
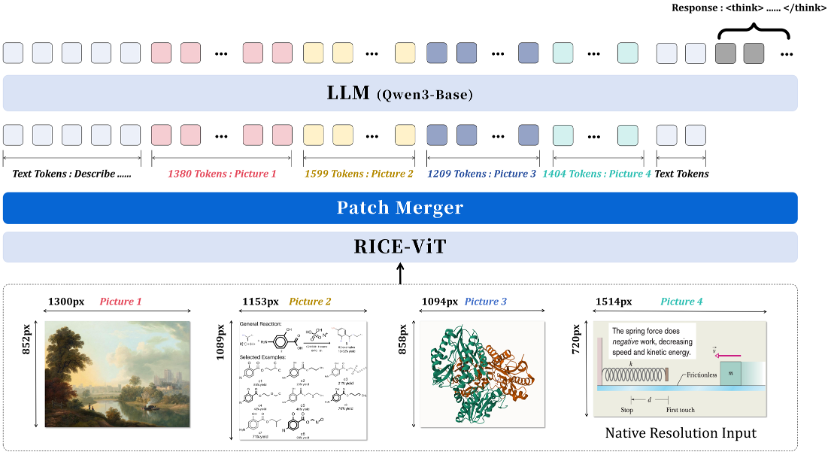
不同于业内追求参数与数据规模的 “暴力美学”,Innovator-VL 走出了一条 “四两拨千斤” 的道路:以更少的数据,换取更强的智能。
仰观宇宙,俯察毫末:All in One 的全能科学视野
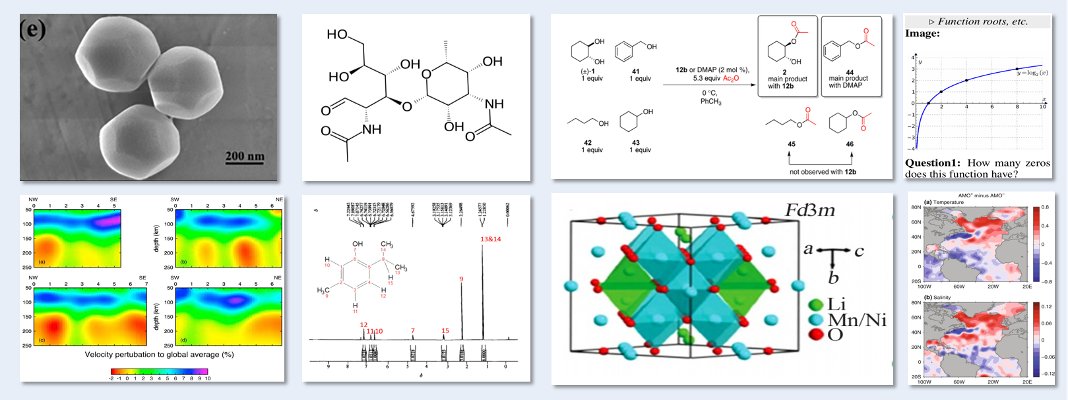
科学研究往往跨越巨大的尺度,从微观粒子的跃迁到宏观星系的演化。Innovator-VL 实现了 "All in One" 的宏观微观全理解,打破了学科间的壁垒。
-
微观世界: 分子式、反应式、NMR 谱图、冷冻电镜图、晶体结构、蛋白质;
-
宏观世界: 地理图像、天文观测、遥感影像、光学成像;
-
数理逻辑: 数学几何图像、复杂表格、算法流程图。
让我们通过两个真实的评测案例,看看 Innovator-VL 如何像科学家一样思考。
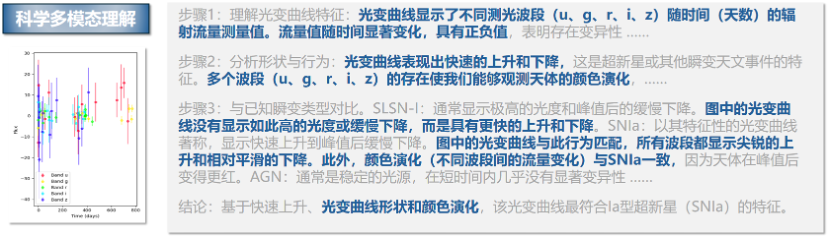
案例一:仰观宇宙 —— 天文光变曲线分析
在天文学中,通过光变曲线判断天体类型是一项硬核技能。Innovator-VL 展现了惊人的逻辑推理能力:

问题:基于提供的不同波段图像,这是什么类型的光变曲线?
A. SLSN-I(超亮超新星 I 型)
B. SNIa(Ia 型超新星)
C. AGN(活动星系核)
D. SNIbc(Ibc 型超新星)


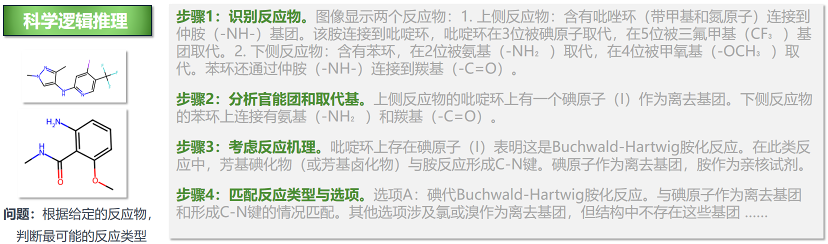
案例二:俯察毫末 —— 有机化学反应预测
面对复杂的有机化学结构,Innovator-VL 能够像资深化学家一样拆解反应机理。
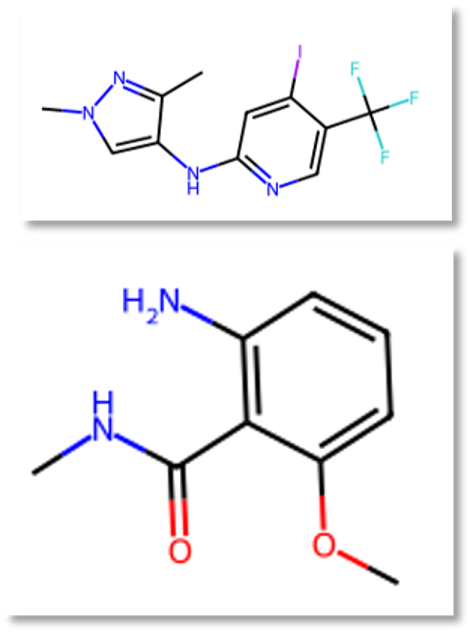
问题:根据给定的反应物,判断最可能的反应类型


三大核心突破:重新定义科学 MLLM
除了上述强大的实战能力,Innovator-VL 在技术路线上也做出了三大突破:
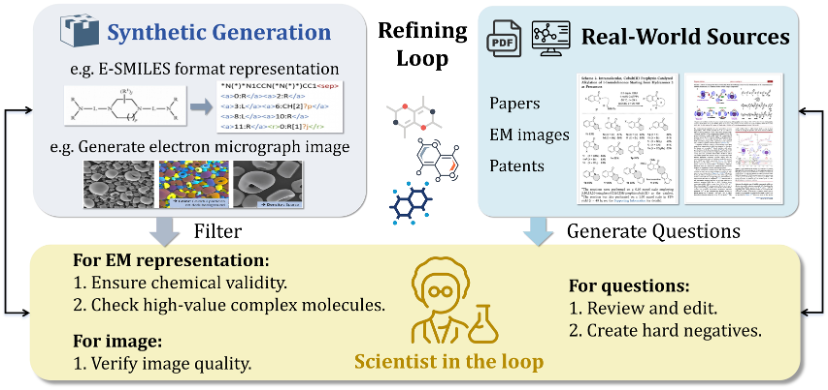
1. 拒绝 “黑盒”:全流程极致透明
目前的 “开源” 往往只停留在权重层面,训练细节讳莫如深。Innovator-VL 团队选择了一条彻底的开源之路。
我们不仅发布了模型权重,更提供了端到端可复现的完整流水线:
-
数据工程: 详尽的数据采集、清洗与预处理方法论;
-
训练细节: 完整的 SFT(指令微调)与 RL(强化学习)策略;
-
优化秘籍: 详细的超参数配方与评测框架。
这使得 Innovator-VL 成为了一套 “教科书级” 的方案,任何科研团队都可以在此基础上,快速构建属于自己领域的科学大模型。
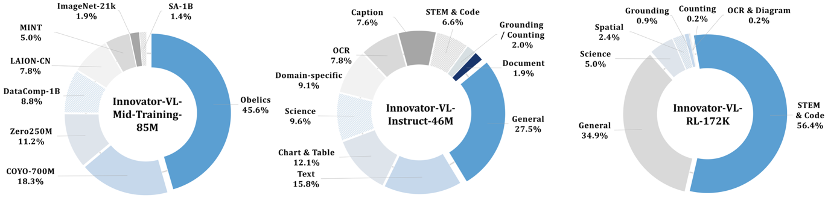
2. 数据效率的奇迹:不到 500 万条科学数据足矣
行业内训练多模态大模型,数据量动辄上亿。而 Innovator-VL 创造了一个效率奇迹:
仅凭不到 500 万条精心挑选的科学训练样本,便在多项科学基准测试中超越了许多依赖海量数据的模型。
-
核心逻辑:Quality > Quantity。
团队通过从文献中提取高质量图文对,并生成多样化的指令微调数据,让模型学会了像科学家一样 “思考” 和 “推理”,而非简单地死记硬背像素模式。
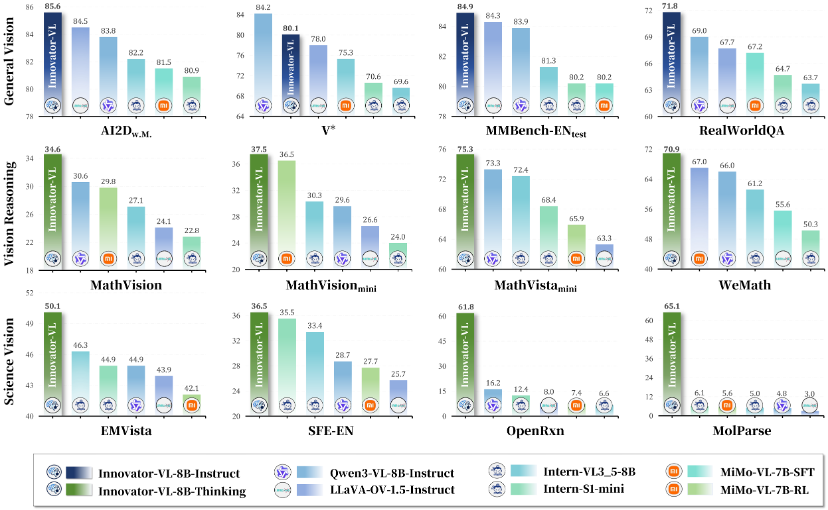
3. 文武双全:科学与通用性能的双向奔赴
以往的科学模型往往是 “偏科生”—— 懂了科学,忘了通用。
Innovator-VL 成功打破了这一魔咒,实现了科学能力与通用能力的完美融合:
-
科学领域: 在化学、生物、地理等多学科基准测试中表现卓越。
-
通用领域: 在通用视觉理解、多模态逻辑推理任务上,完全不逊色于同规模的顶尖通用模型。
这意味着,你不需要在 “科学专家” 和 “生活助手” 之间做选择,Innovator-VL 两者兼得。
探索未来:构建科学智能的基石
Innovator-VL 的意义远超模型本身。它验证了一条高效、透明、可复现的 AI for Science 开发路径。
它告诉我们:即使没有科技巨头般的算力与数据资源,高校与研究机构依然可以构建出世界一流的科学大模型。
正如团队在论文中所言:
“在缺乏大规模数据的情况下,高效且可复现的科学多模态模型不仅是可能的,更是通向未来科学发现的实用途径。”
Innovator-VL 现已全面开源,我们诚邀全球开发者与科研人员共同探索,让 AI 成为照亮科学探索之路的火炬!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com