LightMem通过模仿人类记忆分层机制,在保证准确率的前提下,显著降低大模型长期记忆的成本,为长对话应用提供新的解决方案。
原文标题:ICLR 2026 | LightMem:把大模型「长期记忆」的成本打下来
原文作者:机器之心
冷月清谈:
怜星夜思:
2、LightMem 将记忆更新从在线推理中剥离,改为离线并行更新,这种策略有哪些潜在的风险和限制?
3、LightMem 强调了类人记忆的分层机制,那么在实际应用中,如何确定不同层级记忆之间的信息流动和转换规则?
原文内容

大模型已经很强,但一旦进入 “长对话、跨多轮、多任务” 的真实智能体交互场景,模型很快就会遇到两类老问题:
一是上下文窗口有限,越聊越长时不可避免地 “塞不下”;二是经典的 lost in the middle,即使塞得下也未必用得好。
于是,给大模型配 “外部记忆系统” 尤为重要:把对话写进长期记忆、需要时再检索出来。但现实很快给出了代价 —— 记忆系统往往非常贵:频繁调用大模型做总结 / 抽取、实时做冲突消解与更新、长链路的维护开销,最终让 “有记忆的智能体” 在工程上难以承受。
这篇工作提出 LightMem:一个在 “效果” 和 “效率” 之间更平衡的记忆系统。核心目标很直接:
在不牺牲准确率的前提下,把 token、API 调用次数和运行时延降下来。

-
论文标题:LightMem: Lightweight and Efficient Memory-Augmented Generation
-
论文链接:https://arxiv.org/abs/2510.18866
-
代码链接:https://github.com/zjunlp/LightMem
为什么现有记忆系统 “能用但太贵”?
从主流范式来看,LLM 记忆系统大多是这样工作的:把原始对话按 turn/session 切分;每一段都让 LLM 做总结 / 抽取,写入向量库 / 知识图谱;新信息到来时,再让 LLM 在线做更新 (add/delete/merge/ignore);推理时检索相关记忆拼到 prompt 里回答。

问题在于,不管是 user 侧还是 assistant 侧,真实对话场景中含有非常多的冗余信息:寒暄、重复确认、冗余解释等等。现有系统往往 照单全收,导致:
1) 冗余信息直接进入管线:token 消耗飙升,而且可能反而干扰 in-context learning;
2) 切分粒度僵硬:按 turn 太细会导致总结调用爆炸,按 session 太粗又容易主题混杂,最后总结不准;
3) 在线更新太重:更新与遗忘在 test time 强绑定,长任务延迟高,而且 LLM 还可能在更新时 “误删” 信息。
LightMem 的出发点是:人类记忆并不是 “所有信息都进长期记忆”,而是有一套高效的分层机制:
感官记忆先过滤 → 短时记忆组织整合 → 长时记忆在睡眠时离线巩固。
LightMem 的核心思路:三段式 “类人记忆” 管线
LightMem 把记忆系统拆成三个轻量模块 (对应如下的 Light1/Light2/Light3):
Light1:感官记忆 (Sensory Memory)
目标:快速过滤无用信息、把输入压缩到 “值得记” 的部分,并进行主题切分。
Light2:短时记忆 (Short-Term Memory, STM)
目标:按主题把对话组织成结构化单元,降低总结调用次数,同时减少主题混杂。
Light3:长时记忆 (Long-Term Memory, LTM)+ 睡眠更新 (Sleep-time Update)
目标:把昂贵的记忆更新从在线推理中 “拿出来”,在离线并行地做去重、合并、修复与巩固。

Light1:感官记忆 —— 先压缩,再切主题
轻量压缩:把冗余 token 在系统输入端过滤掉
LightMem 使用一个轻量压缩模型 (论文默认采用 LLMLingua-2) 对原始输入做预压缩:
保留信息量更高、语义更关键的 token,把大量冗余 token 提前过滤掉并挡在 pipeline 之外。
论文实验也验证:在合理压缩率下 (50% 到 80%),LLM 依然能理解压缩后的上下文,准确率基本不受影响。
混合主题切分:避免 “按窗口切” 的粗暴做法
仅靠固定窗口 (turn/session) 很难适配开放对话。LightMem 做了一个混合切分策略:
-
用注意力信号找到候选 topic 边界 (局部峰值);
-
再用相邻片段的语义相似度做二次确认;
-
取二者交集作为最终切分点,降低 attention sink、注意力稀释等噪声影响。
Light2:主题感知 STM—— 用 “内容边界” 替代 “窗口边界”
在拿到 topic segments 后,LightMem 把它们以 {topic, turns} 的结构送入 STM buffer。
当 buffer 达到 token 阈值时,才触发一次 LLM 总结,对每个 topic 生成更结构化的 summary,并写入 LTM。
相比 “每一轮都总结一次”,这种做法直接带来两点收益:
-
调用次数降低:总结不再是 N 次,而是按 buffer 触发的更少次数;
-
总结更准确:输入被 topic 约束,不容易 “把 A 主题的细节总结进 B 主题里”。
论文的消融实验也显示:去掉 topic segmentation 会带来明显准确率下降 (GPT/Qwen 都一致)。
Light3:睡眠更新 —— 把开销最高的部分从在线推理中剥离
记忆系统最贵、也最容易出错的一步,往往是 “更新 / 遗忘”。
现有系统经常在 test time 做 hard update:合并、删改、冲突消解都在线执行,延迟高且风险大。
LightMem 的策略是 “两段式更新”:
在线只做 Soft Update:先写入,不纠结
测试时新记忆条目到来,LightMem 直接插入 LTM (带时间戳),不做复杂更新。
这极大降低了在线延迟,并避免 LLM 在实时更新中误判冲突导致信息丢失。
离线做 Parallel Update:每条记忆维护 “可更新队列”
离线阶段 (sleep time) 触发更新:
对每个条目构建一个 update queue (只允许 “新的更新旧的”,即时间戳约束 tj ≥ ti),然后把这些更新操作并行执行。
并行化的关键好处是:
传统在线更新存在顺序依赖 (读写约束) 导致串行累计延迟;而 LightMem 把更新拆成多个独立队列,可以离线并行,整体更快。
结果:不仅更准,而且便宜很多
论文在两个长记忆基准上验证了 LightMem 的效果与效率:
-
LongMemEval (LongMemEval-S)
-
LoCoMo
并在不同 backbone 上测试:GPT-4o-mini 、 Qwen3-30B-A3B、GLM4.6。
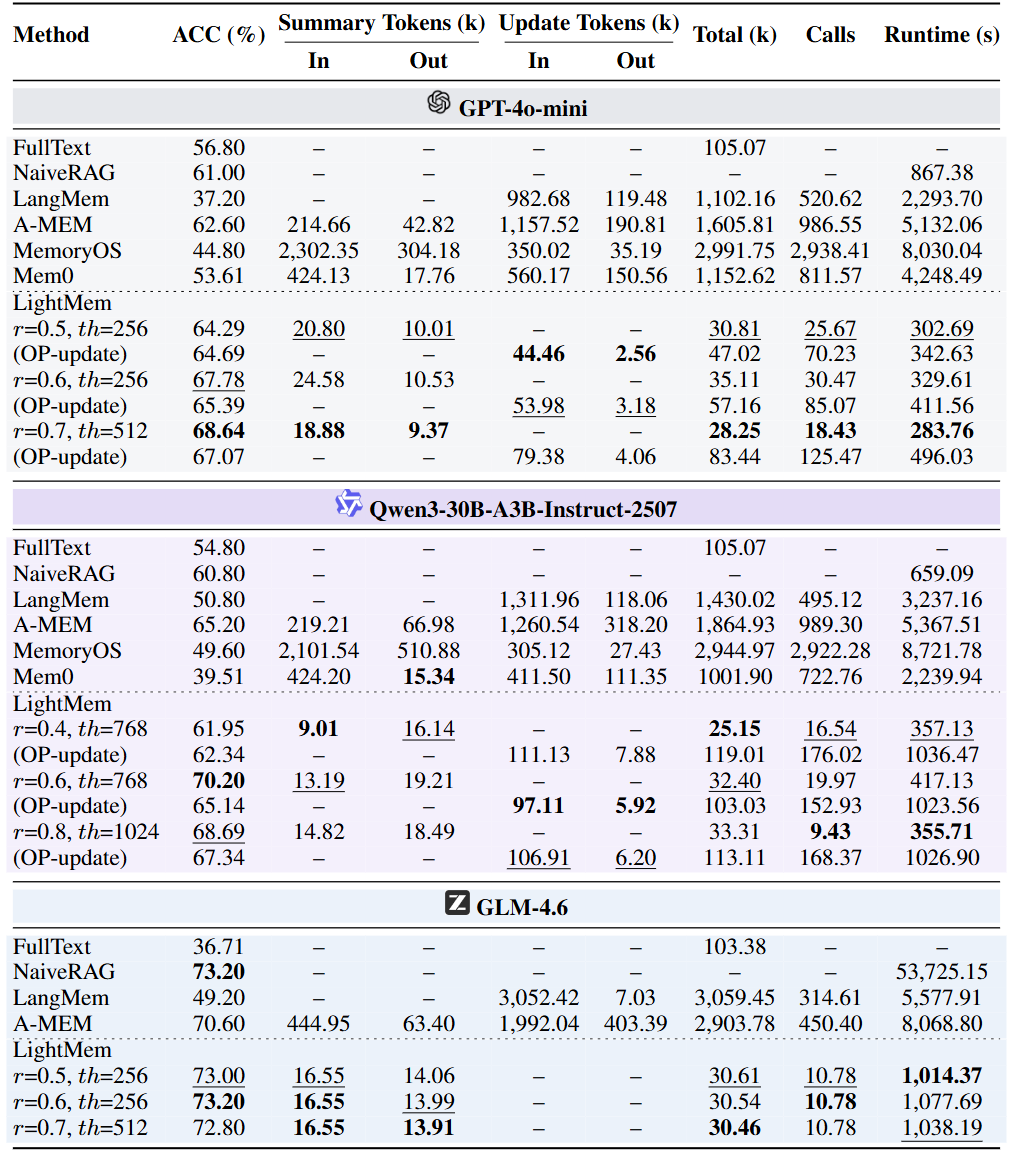

整体结论非常清晰:LightMem 在准确率上超过基线,同时把成本打下来。
论文报告的代表性结果包括:
-
在 LongMemEval 上,LightMem 相比强基线准确率最高提升约 7.7% / 29.3% (不同设置与 backbone);
-
总 token 消耗降低最高可达 38× / 20.9×,API 调用次数降低最高可达 30× / 55.5×;
-
如果只看在线 test-time 成本,节省幅度更夸张:token 最高 106× / 117×,API 调用最高 159× / 310×。
写在最后
LightMem 是一套面向真实长交互场景的 “轻量记忆系统” 答案:
它不追求让记忆机制越来越复杂,而是用更接近人类记忆分工的方式,把冗余挡在入口,把维护放到离线,把代价控制在可部署的范围内。
如果你正在做长对话助手、长期在线 agent、或者任何需要 “记忆但又怕贵” 的系统,这篇工作值得细读。
我们将 LightMem 的方法论与工程经验沉淀到 OpenMem 社区 ,推动记忆机制的开放共建与演进。
OpenMem 旨在共建一个 AI 记忆科学探索与产业实践的全球协作社区,让记忆成为 AI 的新 computer layer,促进 Memory Engineering 开源开放,成为 “记忆研究者的家” 与 “记忆技术的标准化基地”,支撑企业级学术级开发者级的记忆应用生态。
作者简介
方继展,浙江大学人工智能硕士在读,师从张宁豫副教授。研究方向为 Continual Learning、LLM/Agent Memory 与大模型知识编辑,聚焦记忆系统、自进化 Agent 与模型可控更新。以第一/共一作者身份在 ICLR、ACL、ACM MM等国际顶级会议发表/接收多篇论文。提出并开源面向 Agent 的轻量化长期记忆框架 LightMem,获得较高社区关注(GitHub 600+ Star),受到MIT technology review邀请专访,并收到国内多家投资机构/大模型厂商的创业交流邀请。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com