DeepSeek V4 优先向国内厂商开放,V4 Lite 绝密参数曝光:100 万 tokens 上下文窗口,原生多模态架构。
原文标题:曝DeepSeek新模型提前给华为等国内厂商“开绿灯”,V4 Lite 绝密参数外泄
原文作者:AI前线
冷月清谈:
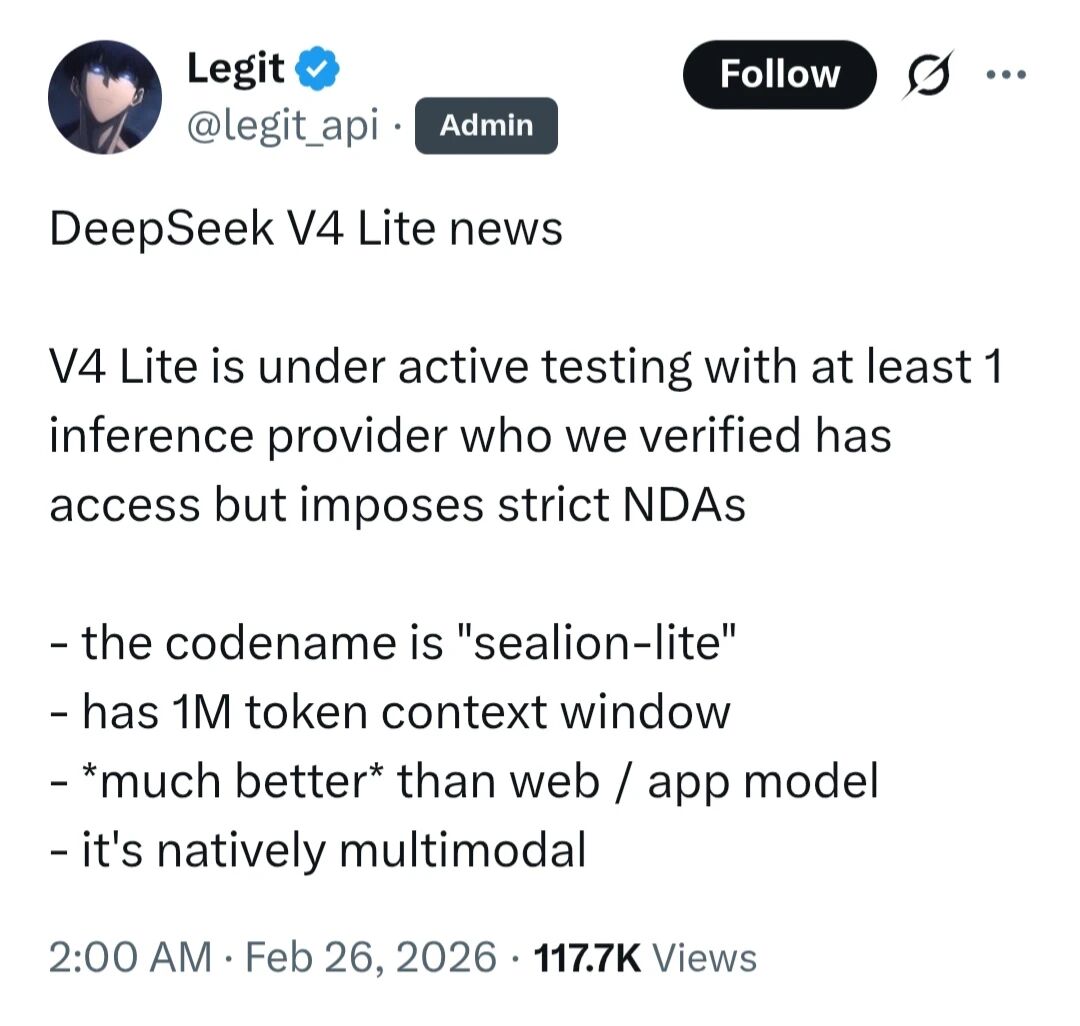
DeepSeek 最新旗舰模型 DeepSeek V4,打破行业惯例,在发布前优先向包括华为在内的国内供应商开放访问权限,以便国内芯片厂商能够提前进行软件适配和性能优化。这一举动表明 DeepSeek 更加重视与国内厂商的合作。同时,DeepSeek V4 Lite 的部分参数也已曝光,该模型代号为“sealion-lite”,拥有 100 万 tokens 的上下文窗口,效果优于网页端/APP 端模型,并且是原生多模态架构。V4 Lite 目前正处于密集测试阶段,至少有一家推理服务商获得了访问权限,但签署了严格的保密协议。
怜星夜思:
1、DeepSeek 优先给国内厂商“开绿灯”进行适配优化,你怎么看待这种策略?
2、DeepSeek V4 Lite 的 100 万 tokens 上下文窗口,会对哪些应用场景带来提升?
3、DeepSeek V4 Lite 是原生多模态架构,和传统的“单模态 + 桥接”方式相比,有哪些优势?
2、DeepSeek V4 Lite 的 100 万 tokens 上下文窗口,会对哪些应用场景带来提升?
3、DeepSeek V4 Lite 是原生多模态架构,和传统的“单模态 + 桥接”方式相比,有哪些优势?
原文内容

左右滑动查看更多图片
整理|华卫
刚刚,有两位知情人士透露,去年凭借低成本模型震撼全球市场的DeepSeek,已提前向包括华为技术在内的国内供应商开放即将推出的旗舰模型DeepSeekV4的访问权限。
消息称,DeepSeek并未向美国芯片制造商展示V4以进行性能优化,反而给包括华为在内的中国芯片厂商留出了数周时间,提前为其处理器做软件适配与性能优化,这打破了在重大模型更新之前进行性能优化的行业惯例。
通常,大型模型在发布前会向英伟达、AMD等头部芯片厂商提供预览版,以确保软件能在主流硬件上高效运行。此前,DeepSeek也曾与英伟达技术团队保持密切合作。
与此同时,另有消息称,DeepSeek V4 Lite 正处于密集测试阶段,至少已有一家推理服务商获得访问权限,但签署了严格的保密协议。目前已知的是,V4 Lite 的代号为“sealion-lite”,拥有 100 万个tokens的上下文窗口,效果显著优于网页端 / APP 端模型,并且是原生多模态架构。