阿里开源Qwen3.5三款新模型,消费级显卡可跑,性能超GPT-5 mini。混合注意力机制+MoE架构,成本更低,速度更快!
原文标题:消费级显卡可跑!刚刚,阿里Qwen3.5又开源3款新模型
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到Qwen3.5采用了混合注意力机制和MoE架构,你认为这些技术对模型性能提升起到了什么作用?它们可能会带来哪些挑战?
3、阿里这次开源Qwen3.5,并且降低了API价格,你认为这对国内AI生态会产生什么影响?会对其他大模型厂商造成什么压力?
原文内容
刚过完年,阿里又卷起来了。
2 月 25 日,继除夕开源 Qwen3.5-397B-A17B 之后,阿里继续开源千问 3.5 系列模型,而且是一口气开源三款中等规模的新模型,分别是 Qwen3.5-35B-A3B、Qwen3.5-122B-A10B、Qwen3.5-27B。
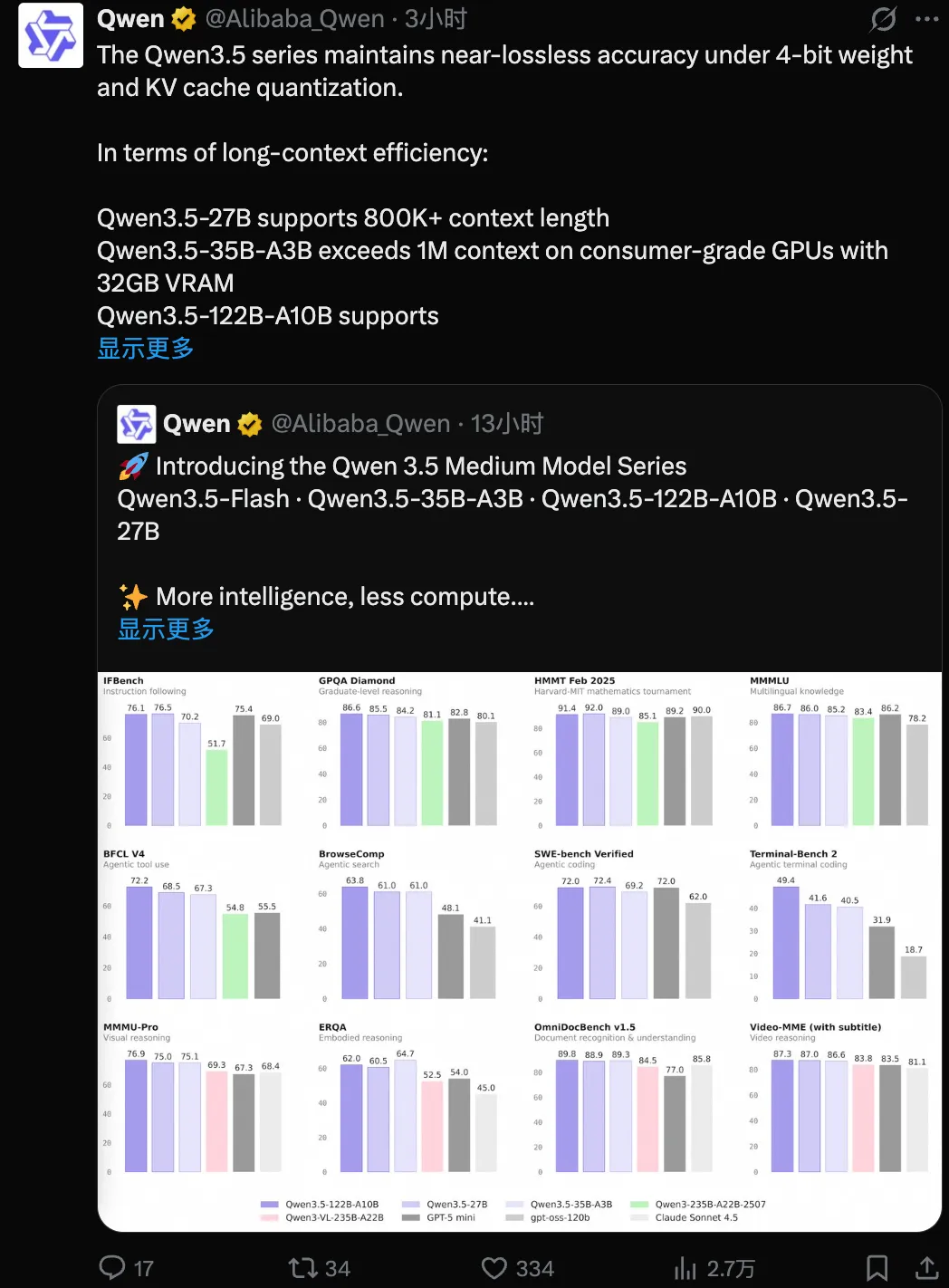
此次开源的三款千问 3.5 模型,凭借架构创新和训练突破,均创下中等尺寸模型的性能新高,不仅超越了更大尺寸的上代旗舰模型 Qwen3-235B-A22B 和 Qwen3-VL,更在多榜单表现上均明显优于 GPT-5 mini。
千问 3.5 新模型甚至可直接部署于消费级显卡,对开发者极为友好。目前,基于 Qwen3.5-35B-A3B 的托管模型 Qwen3.5-Flash 已上线阿里云百炼,每百万 Token 输入低至 0.2 元。
更小的参数,更强的性能
千问 3.5 模型采用混合注意力机制,结合高稀疏的 MoE 架构创新,并基于更大规模的文本和视觉混合 Token 上训练,新模型以更小的总参数和激活参数量,实现了更大的性能提升。
Qwen3.5-122B-A10B 与 Qwen3.5-35B-A3B,就是这一新范式在中等规模下的最新模型成果,在指令遵循(IFBench)、博士级别推理(GPQA)、数学推理(HMMT 25)、多语言知识(MMMLU)、Agent 工具调用(BFCL v4)、Agentic Coding(SWE-bench Verified)等多个权威榜单上,新模型均超越了远大于其规模的 Qwen3-235B-A22B 模型及 Qwen3-VL,以及 GPT-5 mini、gpt-oss-120b 等模型。

更紧凑的模型,更好的性能,千问 3.5 家族中的首个密集(Dense)模型 Qwen3.5-27B 此次惊艳亮相。
Qwen3.5-27B 同时拥有更强的 Agent 能力和原生多模态能力,在工具调用、搜索、编程等多个 Agent 评测中均超过了 GPT-5 mini,在视觉推理、文本识别和理解、视频推理等多项视觉理解能力榜单中超过了 Qwen3-VL 旗舰模型和 Claude Sonnet 4.5。
Qwen3.5-27B 可运行于单个 GPU,对于本地部署极为友好。
阿里开源再次引爆AI社区
此前,基于 Qwen3.5-397B-A17B 的 Qwen3.5-Plus 模型已上线阿里云百炼,性能媲美 Gemini 3 但 API 价格仅为其 5%,适用于高性能的 AI 编程、Agent 等场景。
此次,百炼上线基于 Qwen3.5-35B-A3B 的 Qwen3.5-Flash,支持 1M 的上下文长度,提供官方的内置工具调用,企业和开发者每百万 Token 输入成本低至 0.2 元。Qwen3.5-Flash 响应速度快、性价比高、门槛低,适合处理工作、生产、生活的日常 AI 任务。
此外,Qwen3.5-35B-A3B 的基座(Base)模型也一并开源。
千问 3.5 的系列开源引发全球 AI 开源社区热议,有开发者指出,这将加速机器人产业的 VLA 模型发展,或将衍生出一批基于 Qwen3.5 的多模态模型。
据了解,除夕开源的 Qwen3.5-397B-A17B 模型已登顶 Hugging Face 全球榜首,截至目前,阿里已开源千问模型超 400 个,全球下载量突破 10 亿次,衍生模型数超 20 万,千问稳居全球第一开源模型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com