Vision-DeepResearch通过多模态深度研究,让模型像人一样在噪声环境中进行长视野、可试错、可验证的检索和推理,已在多个基准测试中达到SOTA。
原文标题:多模态DeepResearch,成了!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、VDR-Bench 强制模型进行视觉检索,避免了依赖文本捷径的问题。那么,在实际应用中,我们应该如何平衡视觉信息和文本信息的重要性?在什么情况下应该更侧重视觉信息,什么情况下应该更侧重文本信息?
3、Vision-DeepResearch 的成功在很大程度上归功于高质量的长轨迹数据合成。那么,如何保证合成数据的质量?在数据合成过程中,有哪些关键的挑战需要克服?
原文内容

DeepResearch 的价值在于把「查资料」变成「做研究」:不是搜到一条就回答,而是会连续多轮地提出问题、去不同地方找证据、互相对照核实、再把信息整理成结构清晰的结论。这样做能显著降低「凭感觉瞎编」的风险,特别适合那些信息分散、容易混淆、需要多步推理和多来源佐证的复杂问题。
工业级 deepresearch LLM(如 tongyi-deepresearch、MiroThinker),将文本 DeepResearch 性能从探索级提高到了与闭源模型的 agentic reasoning pipeline 相当的性能,但多模态 DeepResearch 依然处在初期。
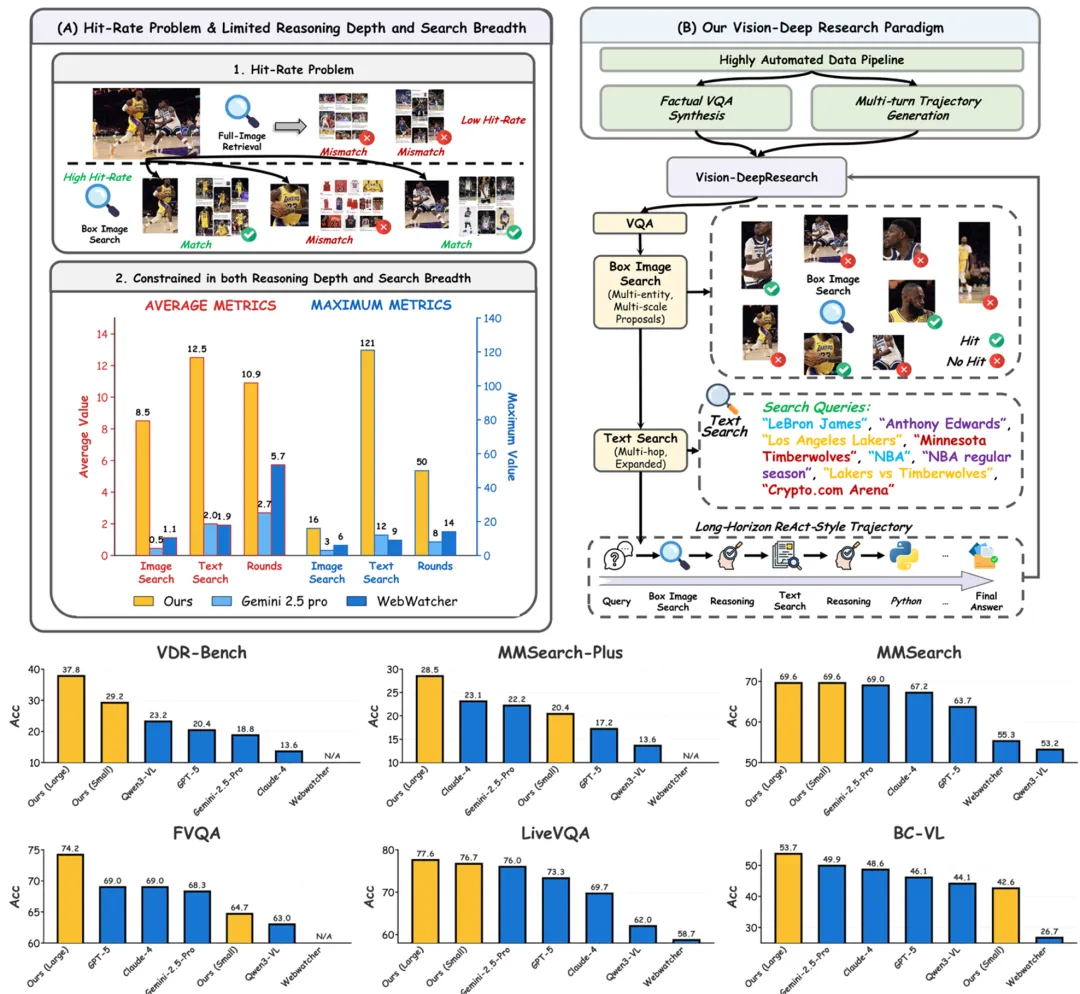
图 1A:指出现有多模态深度研究在图像搜索上的两大瓶颈:忽视搜索引擎命中率问题(单次全图 / 实体检索常失败,不同尺度裁剪结果波动大),以及推理深度与检索广度不足(轨迹短、交互少)。图 1B:展示整体流程:自动合成高质量 VQA 与多轮轨迹,并通过 SFT+RL 把深研能力内化到 MLLM 中,使其能进行多轮、多实体、多尺度的视觉与文本搜索。底部结果对比表明:在统一的 agentic 推理设置下,模型以更小参数规模在 6 个基准上达到 SOTA。
在现实世界中,多模态 DeepResearch 有着重要意义,其将研究能力从「只看文字」扩展到「文字 + 图片 / 图表 / 截图等」。现实世界里很多关键信息就藏在视觉内容里:一张照片里的标志、一个产品细节、一页报告截图里的表格、一张地图或示意图。
多模态 DeepResearch 能把这些视觉线索也当成证据来使用:先从图片中抓住关键点,再去查文字资料验证补全,必要时再回到图片继续核对,最后把图文证据一起整合成更可靠、更完整的答案。这样不仅覆盖的信息更全,也更接近人类真实的研究方式。
基于此,作者构建了一个面向真实世界搜索环境的多模态 deep-research 大模型,通过 VQA 数据合成 + 轨迹合成 + 冷启动 + 大规模强化学习,解决当前工作所忽略的引擎命中率问题,将推理轮数提高到数十轮,与搜索引擎交互次数提高到了数百次。

-
机构:港中文 MMLab,中科大,小红书等
-
HF daily paper:
-
https://huggingface.co/papers/2601.22060
-
https://huggingface.co/papers/2602.02185
-
Project page: https://osilly.github.io/Vision-DeepResearch/
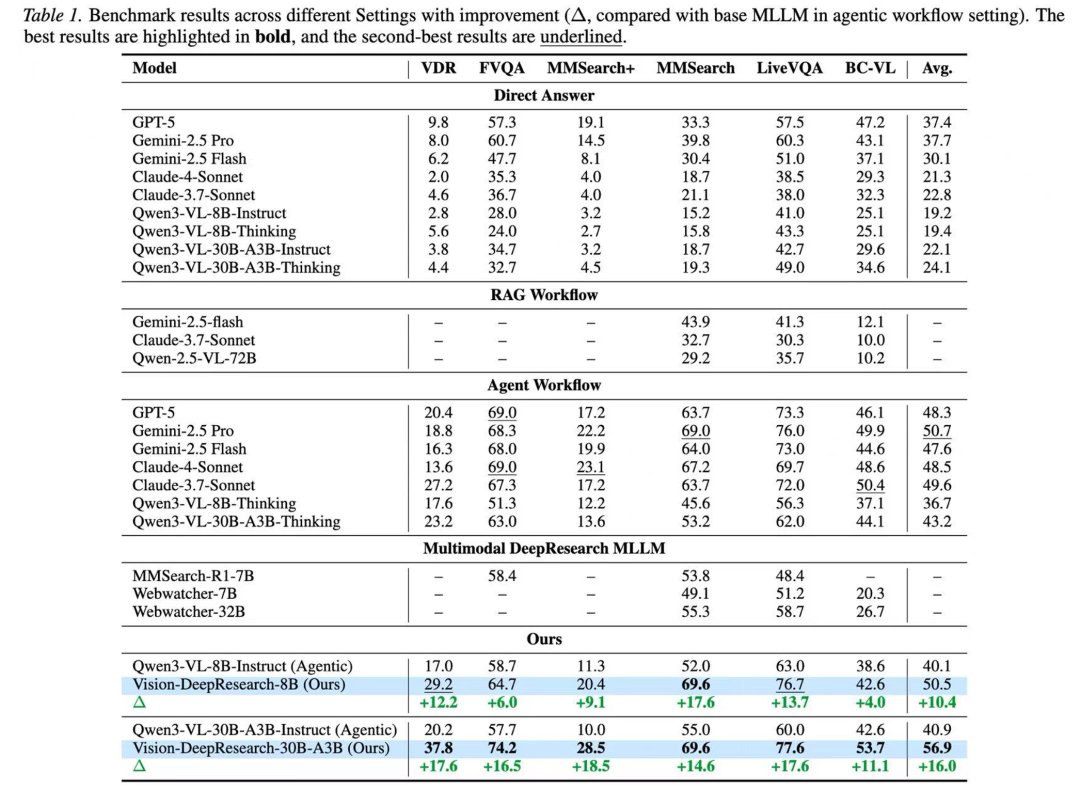
相比于之前的 multimodal deep-research MLLM 在 6 个主流 benchmark 上几乎翻倍性能,对比例如 gpt5、gemini2.5pro、claude4 等强大闭源模型的 agentic reasoning pipeline,使用 30B-A3B 甚至 8B 参数规模几乎都取得了领先或者相当的性能。
基线对比 Demo:
更多 case 展示:
现有一些多模态 DeepResearch 的探索,在真实网页环境里经常卡在两道硬坎,这导致他们缺乏实际应用价值:
-
命中率问题(hit-rate)被忽视:一张全图 / 一次实体级查询往往被背景噪声带偏;同一实体不同尺度裁剪,检索结果差异巨大。
-
推理深度与检索广度不足:多数方法轨迹短、工具调用少,难以完成多跳证据聚合与复杂问题的「试错式搜证」。
Vision-DeepResearch 提出新的多模态深度研究范式:把检索从「一次性操作」升级为多轮试探 — 反馈 — 再检索的长期交互过程,支持几十步推理、上百次引擎交互,让模型像人一样在噪声环境中不断缩小范围、验证证据,最终稳定命中关键事实。
方法核心:多尺度视觉检索 + 文本深研接力 + 端到端内化
整体路线是「高质量长轨迹合成 → 冷启动 SFT → 在线高效异步 RL 内化能力」:
-
多实体 / 多尺度视觉裁剪检索(CIS):模型先定位与问题相关区域,生成多个 bbox 与不同尺度 crop 并行发起视觉搜索,显著提升命中率。
-
视觉→网页→摘要→验证的证据管线:视觉搜索返回 URL 后,访问网页并用辅助模型做摘要与图文一致性验证,过滤噪声,提炼可用证据。
-
桥接文本 DeepResearch 能力:利用强文本 DeepResearch 基础模型生成对应的文本搜索长轨迹,实现跨模态长视野推理迁移。
-
训练策略:先用约 30K 长轨迹做 SFT 教会「怎么搜、怎么查、怎么写轨迹」,再用在线强化学习在真实在线搜索环境中优化策略(纯准确率奖励 + 多种工程稳定化技巧),把深研行为真正「内化」为模型能力。
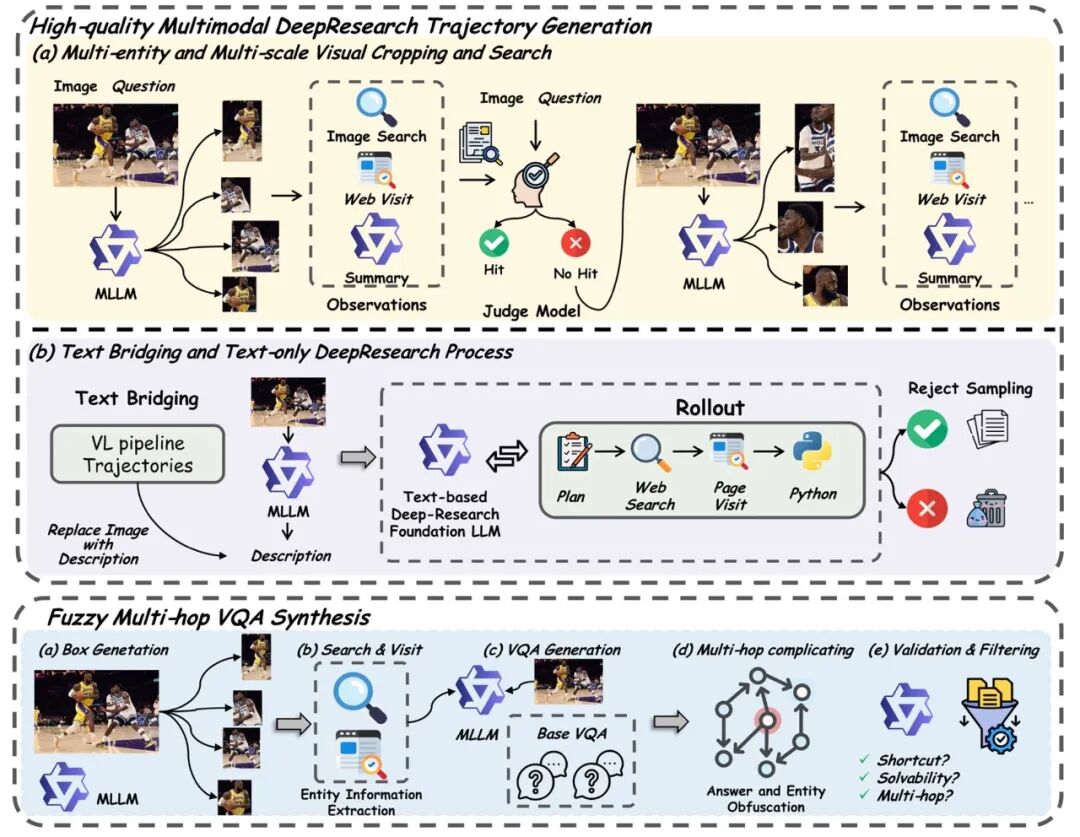
图 2 数据管线高质量轨迹数据生成;多跳复杂 VQA 合成
实验:小参数也能打到 SOTA,长视野交互是关键增益来源
性能强大:在 VDR、FVQA、MMSearch (+)、LiveVQA、BC-VL 等 6 个基准上:
-
Vision-DeepResearch-8B 在同等 agent 设置下,相比 Qwen3-VL-8B-Instruct(Agentic)平均提升约 + 10.4%。
-
Vision-DeepResearch-30B-A3B 进一步把整体成绩推到更高水平(平均提升约 + 16.0%),在多个基准上持续扩大优势。超越 GPT-5、Gemini-2.5-Pro、Claude-4-Sonnet 等强大闭源模型构成的 deep-research 系统的性能。
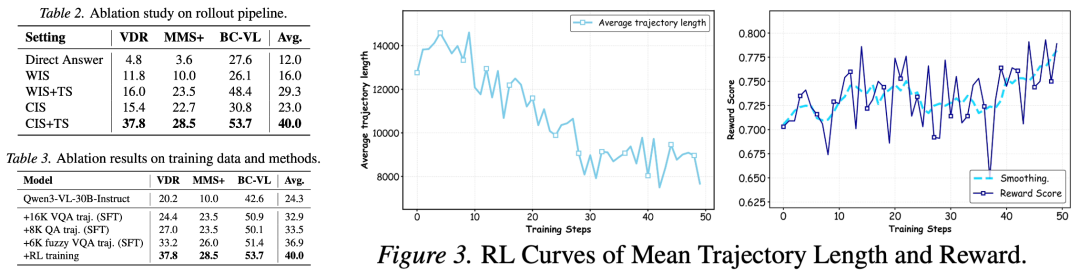
消融结论明确:
-
仅全图检索(WIS)收益有限且易受噪声干扰;
-
多尺度裁剪(CIS)显著提升视觉命中;
-
CIS + 文本搜索(TS)组合最好,同时满足「视觉锚点精准 + 长尾知识补全」;
-
RL 进一步把长视野决策做稳:模型学会用更少但更有效的步骤拿到更高回报。
VDR-Bench:重新定义视觉深研评测!2,000 条「必须做视觉搜索」的真实难题,专治文本捷径与全图完美检索
多模态深度研究系统越来越多,但评测却长期「不对题」:很多基准存在两类系统性漏洞:
-
不够「视觉搜索中心」:答案常被问题文本线索泄露,甚至可用模型先验知识 / 纯文本检索绕过视觉验证,导致分数虚高。
-
检索场景过于理想化:全图反搜经常命中几乎一模一样的「近重复图片 + 标题元信息」,形成「完美检索(perfect retrieval)」,没测到真实环境下的定位、裁剪、试错与跨模态核验能力。文搜搜索深度太浅,无法反映真实世界的复杂性。

图 3 现有评测基准两大缺陷
VDR-Bench 为此提出一套更贴近现实的评测基准:2,000 条多跳 VQA,覆盖 10 个视觉域,强调必须通过局部实体发现 + 迭代裁剪检索 + 文本多跳推理才能可靠作答,从源头减少捷径与「全图一把梭」
基准构建核心:从「视觉实体」出发,强制闭环证据链
VDR-Bench 采用严格的「视觉优先」多阶段流程:
-
人工裁剪 + Web 级视觉搜索:标注者优先裁剪显著局部(logo / 人物 / 地标 / 产品等)而非整图,模拟真实搜图行为。
-
实体抽取与验证:从检索结果标题 / 描述抽取候选实体,经 MLLM 过滤一致性,再由人工核验,确保实体不是「全图轻松搜到」的近重复泄露。
-
Seed VQA 生成:围绕已验证视觉实体生成需要显式识别与落地的问答。
-
知识图谱随机游走做多跳扩展:把问题升级为「从视觉实体出发」的多跳推理(总部城市 / 创始人 / 年份 / 关联组织等)。
-
可解性与去捷径审核:自动与人工双重检查,确保必须依赖记录下来的视觉检索证据与推理路径,避免歧义与 shortcut。
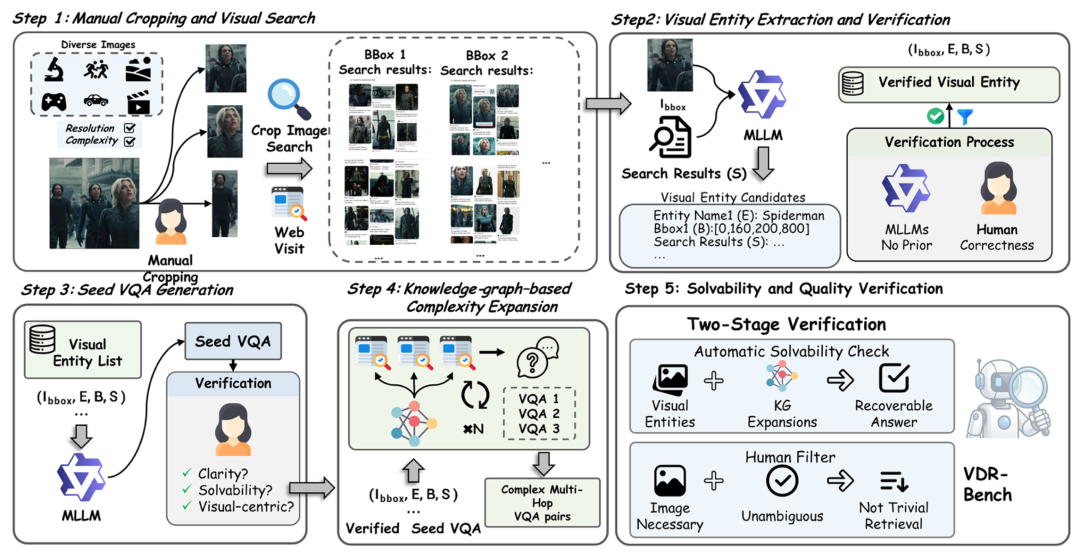
图 4 多阶段数据标注管道
在 VDR-Bench 上,模型必须主动检索才有明显提升,并且作者发现「Lazy Search(懒搜索)」:越强的模型越可能依赖先验知识、反而不愿意充分调用视觉检索,导致深研题表现不匹配其基础能力。
为缓解这一点,作者提出 Multi-turn Visual Forcing(MVF):在推理流程上强制多轮、多尺度裁剪与验证,大幅提升深度检索性能。
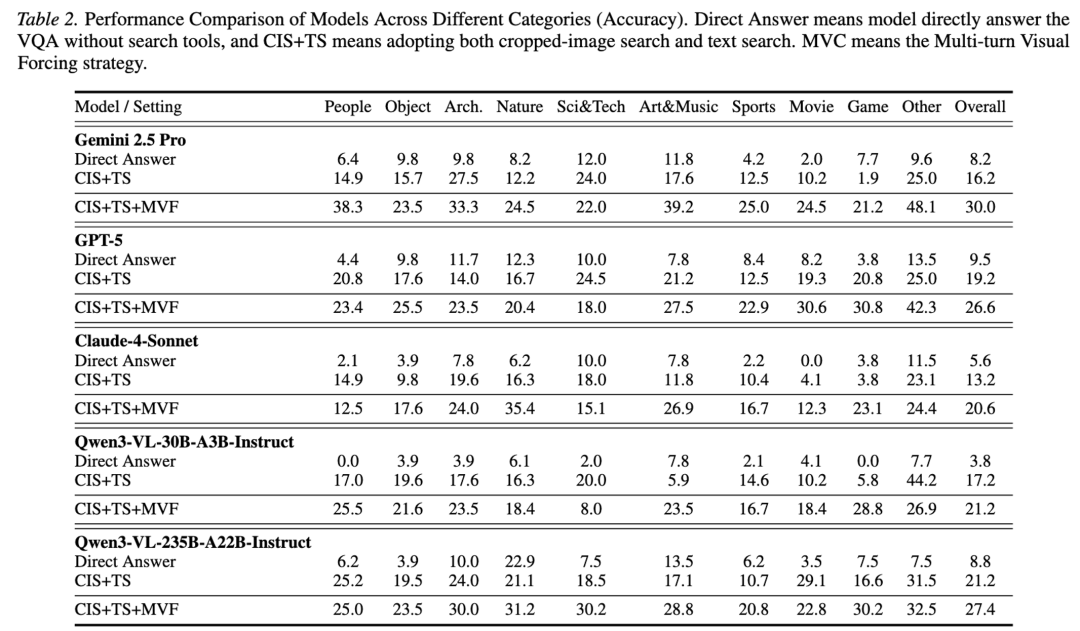
意义与未来
Vision-DeepResearch 证明:多模态深研能力的关键不只是「会调用工具」,而是要在噪声世界里形成长视野、可试错、可验证的检索 — 推理闭环;并且通过可规模化数据合成与 RL,可以把这种行为从 workflow 变成模型的内生能力。
VDR-Bench 把「视觉深研」从「能不能答对」升级为「能不能在噪声世界里定位 — 检索 — 验证 — 多跳推理」,为后续模型与 Agent 训练提供更真实的测试平台,也让社区更清楚:下一代多模态深研系统的瓶颈到底在哪里?
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com