DeepMind研究表明,AI智能体并非越多越好。任务属性决定了智能体架构的选择,盲目增加数量可能适得其反。
原文标题:DeepMind:智能体越多越乱,Agent天花板出现了?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里提到了“工具协调权衡”,说任务需要的工具越多,多智能体协调的成本就越高。这个“成本”具体指的是什么?是计算资源、时间消耗,还是别的什么?有没有办法降低这种成本?
3、DeepMind的研究发现,独立的多智能体系统容易放大错误。那么,在实际应用中,如果必须使用独立的多智能体系统,有没有什么方法可以降低错误放大的风险?
原文内容
在最近 AI 领域内,智能体(Agent)的研究和应用越来越多,原生多智能体工作的基础模型也已开始出现。
作为一个能够推理、规划和行动的系统,智能体正逐渐成为现实世界人工智能应用的常见范式。从编程助手到私人健康教练,AI 应用正从单次问答转向持续的多步骤交互。尽管研究人员长期以来一直利用既定指标来优化传统机器学习模型的准确性,但 AI 智能体引入了新的复杂性。
与孤立的预测不同,AI 智能体必须应对持续的多步骤交互,其中单个错误可能会在整个工作流程中引发连锁反应。这种转变促使我们超越标准的准确性进行思考:究竟该如何设计这些系统才能实现最佳性能?
在实践上,我们常常依赖启发式方法,例如「智能体越多越好」的假设,认为增加专业智能体就能持续提升结果。论文《More Agents Is All You Need》指出,大语言模型(LLM)的性能会随着智能体数量的增加而提升,而《Scaling Large Language Model-based Multi-Agent Collaboration》发现,多智能体协作「…… 通常通过集体推理超越单个智能体的性能」。
在 Google DeepMind 的新论文中,研究人员对这一假设提出了挑战。通过对 180 种智能体配置进行大规模受控评估,DeepMind 推导出了智能体系统的首个定量规模化原则,揭示了「增加智能体数量」的方法往往会遇到瓶颈,如果与任务的具体属性不匹配,甚至会降低性能。

-
论文:Towards a Science of Scaling Agent Systems
-
链接:https://arxiv.org/abs/2512.08296
定义「智能体」评估
为了理解智能体如何扩展,研究人员首先定义了「智能体任务」的构成要素。传统的静态基准测试衡量模型的知识水平,但无法捕捉部署的复杂性。其认为智能体任务需要具备三个特定属性:
1. 与外部环境持续进行多步骤互动;
2. 在部分可观测性条件下进行迭代信息收集;
3. 基于环境反馈的自适应策略改进。
研究人员评估了五种典型架构:一种单智能体系统 (SAS) 和四种多智能体变体(独立式、集中式、分散式和混合式),并在四个不同的基准测试中进行了测试,包括 Finance-Agent(金融推理)、BrowseComp-Plus(网页导航)、PlanCraft(规划)和 Workbench(工具使用)。智能体架构定义如下:
-
单智能体(SAS):一个独立的智能体,使用统一的记忆流按顺序执行所有推理和行动步骤;
-
独立:多个智能体并行处理子任务,彼此不进行通信,仅在最后汇总结果;
-
集中式:一种「中心辐射式」模型,有中央协调者将任务委派给作业者并综合他们的输出;
-
去中心化:一种点对点网络,其中的智能体直接相互通信,共享信息并达成共识;
-
混合型:结合层级监督和点对点协调,以平衡中央控制和灵活执行。
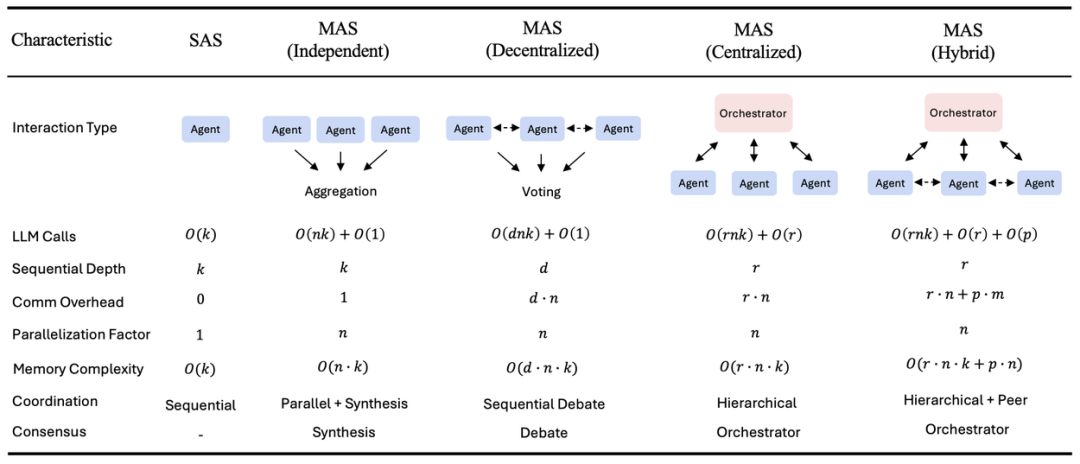
本研究评估了五种典型的智能体架构,并总结了它们的计算复杂度、通信开销和协调机制。k = 每个智能体的最大迭代次数, n = 智能体数量, r = 协调器轮数, d = 辩论轮数, p = 对等通信轮数, m = 每轮平均对等请求数。通信开销统计智能体间的消息交换次数。独立架构以最小的协调实现最大程度的并行化。去中心化架构采用顺序辩论轮次。混合架构结合了协调器控制和定向对等通信。
结果:「增加智能体」只是神话
为了量化模型能力对智能体性能的影响,DeepMind 评估了这些架构在三大主流模型系列(OpenAI GPT、Google Gemini 和 Anthropic Claude)上的表现。结果揭示了模型能力与协调策略之间复杂的关联。
如下图所示,虽然性能通常会随着模型能力的提升而提高,但多智能体系统并非万能解决方案 —— 根据具体配置的不同,它们既可能显著提升性能,也可能意外地降低性能。
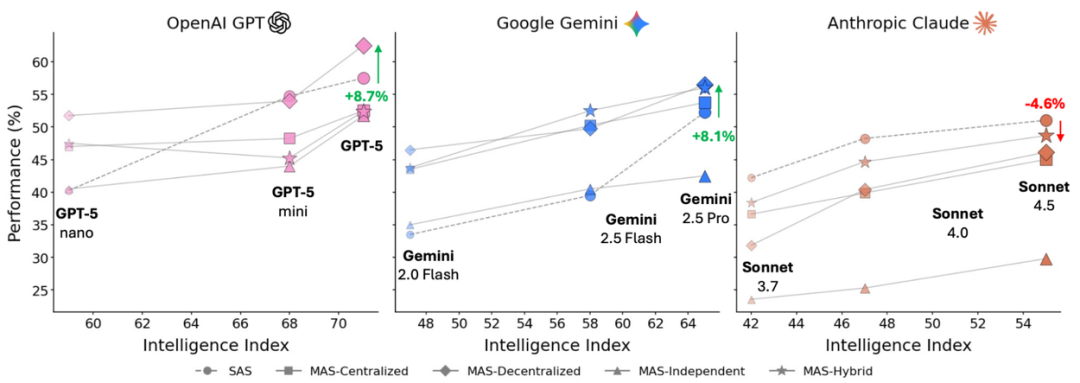
对三大主要模型系列(OpenAI GPT、Google Gemini、Anthropic Claude)的性能比较,展示了不同的智能体架构如何随着模型智能的提升而扩展,其中多智能体系统可能会根据配置的不同而提升或降低性能。
以下结果比较了五种架构在不同领域(例如网页浏览和金融分析)的性能。箱线图表示每种方法的准确率分布,而百分比则表示多智能体团队相对于单智能体基线的相对改进(或下降)。这些数据表明,虽然增加智能体可以显著提升并行任务的性能,但在顺序性更强的流程中,往往会导致收益递减,甚至性能下降。
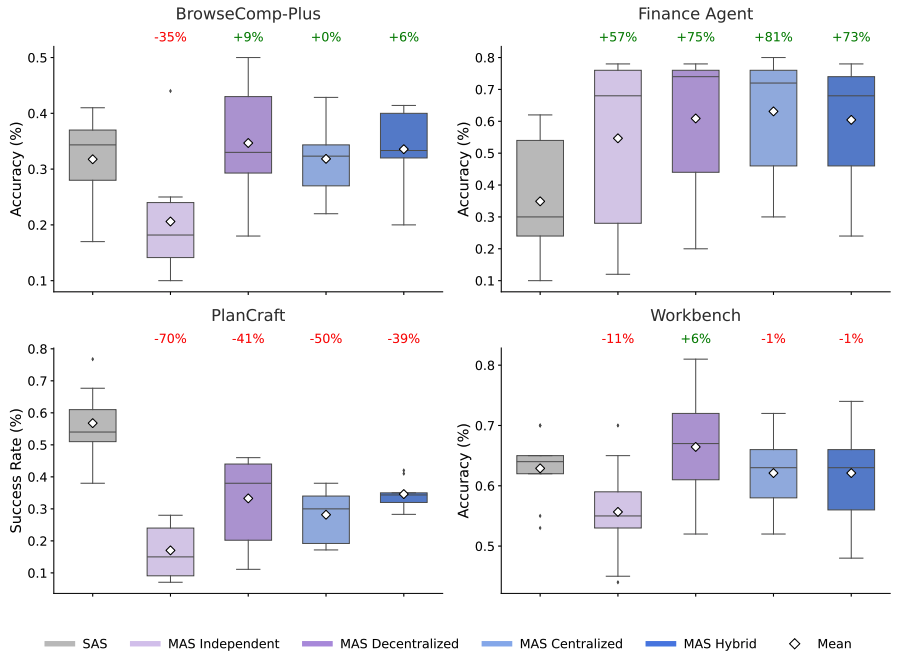
特定任务的性能表明,多智能体协调在可并行化的任务(如 Finance-Agent)上取得了显著的收益(+81%),但在顺序任务(如 PlanCraft)上的性能却有所下降(-70%)。
对齐原则
对于像金融推理这样可并行化的任务(例如,不同的智能体可以同时分析收入趋势、成本结构和市场对比),集中式协调比单个智能体的性能提升了 80.9%。将复杂问题分解为子任务的能力使得智能体能够更高效地工作。
顺序处罚
相反,在需要严格顺序推理的任务(例如 PlanCraft 中的规划)中,研究人员测试的每个多智能体变体的性能都下降了 39% 到 70%。在这些情况下,通信开销会打断推理过程,导致实际任务所需的「认知预算」不足。
工具使用瓶颈
DeepMind 研究人员发现了一个「工具协调权衡」。随着任务需要更多工具(例如一个编码代理需要访问 16 种以上的工具),协调多个智能体的「成本」会不成比例地增加。
安全特性
或许对实际部署而言最重要的是,该工作发现了架构与可靠性之间的关系。DeepMind 测量了误差放大率,即一个智能体的错误传播到最终结果的速率。
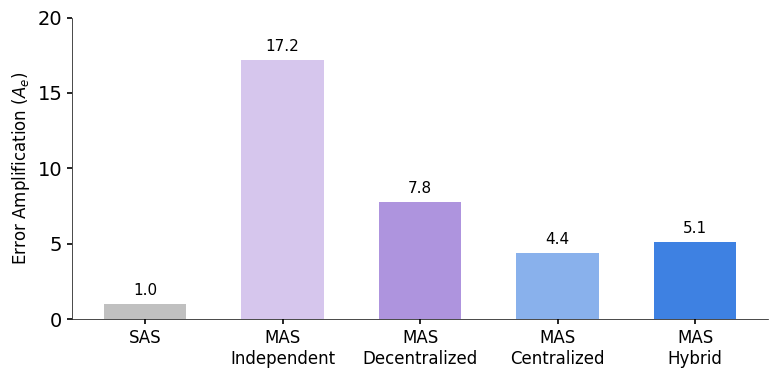
跨架构的综合指标显示,集中式系统在成功率和错误控制之间实现了最佳平衡,而独立的多智能体系统将错误放大了高达 17.2 倍。
研究发现,独立的多智能体系统(智能体并行工作但不进行通信)会将错误放大 17.2 倍。由于缺乏相互检查机制,错误会不受控制地级联传播。集中式系统(带有协调器)则将这种放大倍数控制在 4.4 倍。协调器有效地充当了「验证瓶颈」,在错误传播之前将其捕获。
智能体设计的预测模型
最后,作者不再局限于回顾性分析,而是开发了一个预测模型(R² = 0.513),该模型利用工具数量和可分解性等可测量的任务属性来预测哪种架构性能最佳。该模型能够正确识别 87% 未见过的任务配置的最佳协调策略。
这表明我们正在迈向智能体扩展的新科学。开发者不再需要猜测是使用智能体集群还是单个强大的模型,而是可以根据任务的特性,特别是其顺序依赖关系和工具密度,做出基于原则的工程决策。
结论
随着 Gemini 等基础模型的不断发展,Google DeepMind 的研究表明,更智能的模型并不能取代多智能体系统,而是加速了其发展,但这只有在架构正确的情况下才能实现。通过从启发式方法转向定量原则,我们可以构建下一代 AI 智能体,它们不仅数量更多,而且更智能、更安全、更高效。
参考内容:
https://research.google/blog/towards-a-science-of-scaling-agent-systems-when-and-why-agent-systems-work/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com