全自动AI研究系统FARS在228小时内生成100篇论文,平均每篇成本约1000美元,初步展现科研工业化雏形。
原文标题:228小时狂飙100篇论文、烧光114亿Token:FARS杀疯了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到FARS系统在某些方面已经超越了人类投稿的平均水平,但在复杂假设空间中的研究取舍和机制洞察上仍有不足。你认为在AI科研流水线中,人类研究者最核心的价值体现在哪里?
3、FARS系统目前仍处于“算力换智能”阶段,Token消耗较高。你认为未来AI科研系统在哪些方面有进一步的优化空间?
原文内容
这个春节,AI 圈最硬核的一场「真人秀」,悄然完成了阶段性收官。
主角不是动漫人物,也不是舞枪弄棒的机器人,而是一位 7×24 小时从不疲倦的 AI 科学家 ( Fully Automated Research System )。
这套由 Analemma(日行迹)打造的全自动研究系统,在长达 228 小时 28 分 33 秒的连续公开运行中,自己提假设、做实验、写论文,共生成 244 个研究假设,「肝」出 100 篇短论文( short paper )。
算下来,在这座流水线式的「科研工厂」中,每隔约 2 小时就有一篇论文产出。

让 AI 自己写 100 篇论文目标达成,花了 228 个小时。目前,计划持续一个月的直播仍在进行中。直播地址:https://analemma.ai/fars
这种跳出传统科研范式的工业级吞吐量,很快让围观网友坐不住了。



首批深度「验货」的专业网友给出了一个颇为一致的判断:结果超过预期、相当出色。
如果把它当作人类顶会论文,还不够惊艳;但如果考虑到这是一个全自动系统的阶段性产出,其完成度已经明显超出很多人的事前预期。
「考虑到这只是一个 AI 的自主起步,能 7×24 小时稳定产出到这个质量,还要啥自行车?」


而且,真 work 没有通篇幻觉。
至少在当前阶段,FARS 已经完成了一次关键跨越。它首次证明,一条无人值守的科研「流水线」不仅能跑,而且能在相对稳定条件下,持续产出具备一定学术竞争力的 short paper 级工作。
「发论文这件事本身的稀缺性」被摧毁了。
恐怖的「工业节拍」,算力正在转化为知识
FARS 并不是一个单体模型,而是一套多智能体系统,包括四个功能模块:
-
Ideation(构思):负责文献调研与假设生成
-
Planning(规划):负责实验方案设计
-
Experiment(实验):负责代码编写与执行
-
Writing(写作):负责论文撰写
从实时运行界面可以直观看到,FARS 以项目队列的方式并行推进多个研究任务。每个课题依次穿过 Ideation → Planning → Experiment → Writing 四个阶段,流程高度模块化,呈现出明显的「科研装配线」特征。
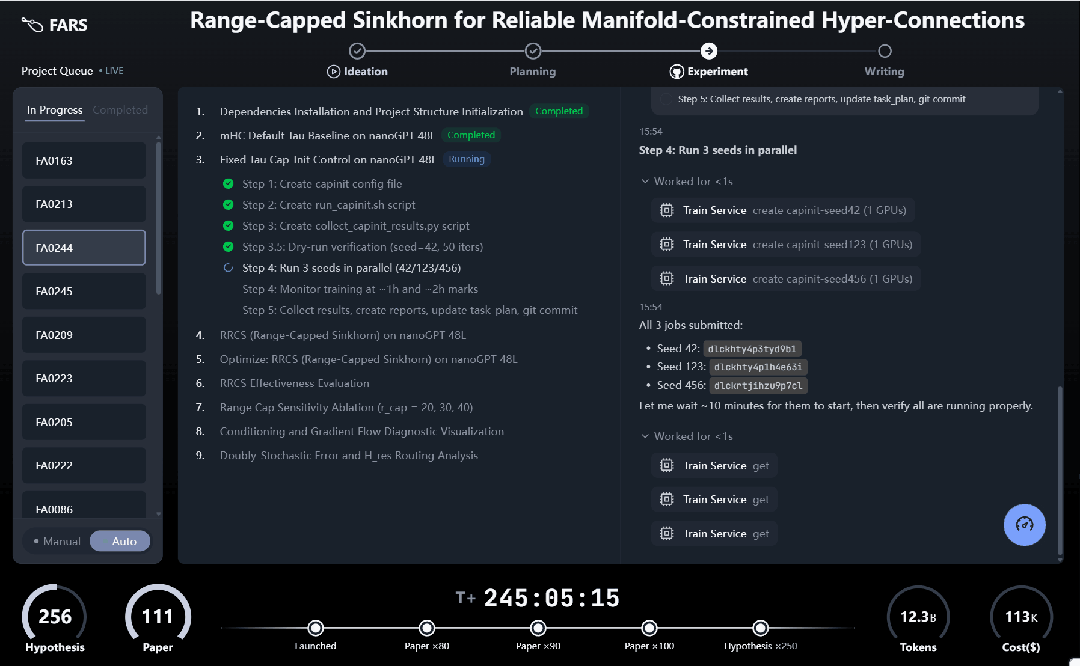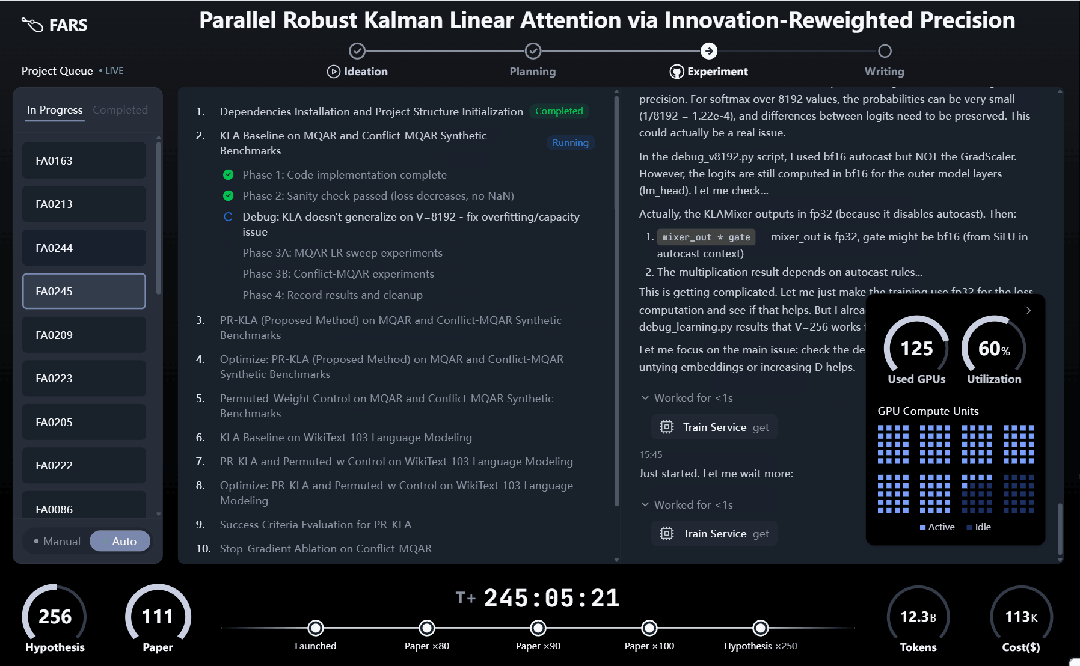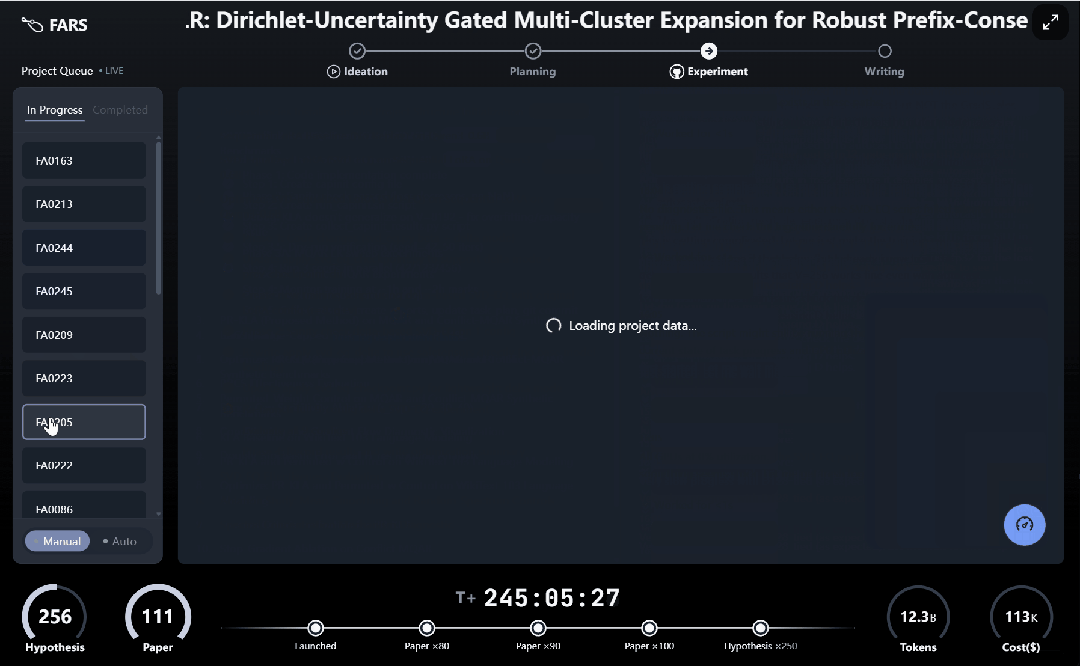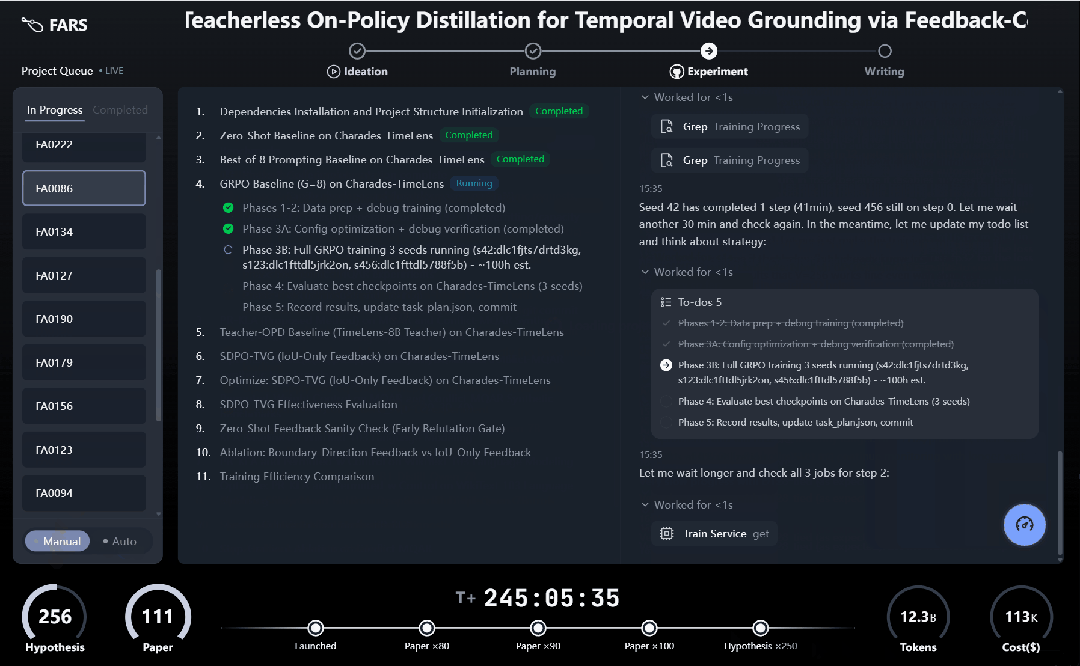
FARS 实时运行界面:从假设生成到论文写作,自动化科研流水线首次以可观测形态完整展开。
为了让它心无旁骛的做研究,Analemma(日行迹)还给它搭建了一个 160 张显卡的计算集群,并允许它调用几乎任何开源和闭源大模型,实验条件远超大部分高校实验室。
而这条「流水线」的产能,已经到了让人很难忽视的程度。在约 228 小时(≈9.5 天) 的连续运行周期内:
-
系统生成 244 个研究假设
-
完成 100 篇 short paper
-
累计消耗 114 亿 Token
-
总成本约 10.4 万美元(≈75 万元人民币)
全程无人干预。
进一步归一化后,这套系统的「工业节拍」变得更加直观:平均每隔约 2 小时 17 分就有一篇研究论文完成,平均每篇论文成本大约 1000 美元,花费 1 亿多Token。
对比人类科研常见的 3–6 个月 / 篇的周期,这种吞吐差距几乎是数量级级别的,成本也极为低廉。

不过,如果把目光从吞吐转向效率,约 1.14 亿 Token / 篇的消耗,已经明显高于普通写作生成(通常百万级 Token )以及常见复杂 Agent 任务(通常百万、千万级 Token )的开销。
这表明,FARS 仍处于「算力换智能」的阶段,其表现更多来自计算密度,而非算法效率的极限压缩。
综合来看, 一方面,FARS 已经用实测结果证明,端到端自动化科研流水线在吞吐层面是切实可行的。另一方面,其当前的 Token 与成本结构,距离「足够便宜地大规模跑」还有工程空间。
质量:它写得快,那写得好吗?
量大,从来不自动等于质优。FARS 写出来的东西,到底处在什么水平?
为此,研究团队使用斯坦福大学开发的 AI 审稿系统 Agentic Reviewer( paperreview.ai ),按照 ICLR 的评审标准,对这 100 篇论文进行了统一打分。
根据开发者公开评估,Agentic Reviewer 在审稿一致性上,已达到人类审稿人的判断水平。
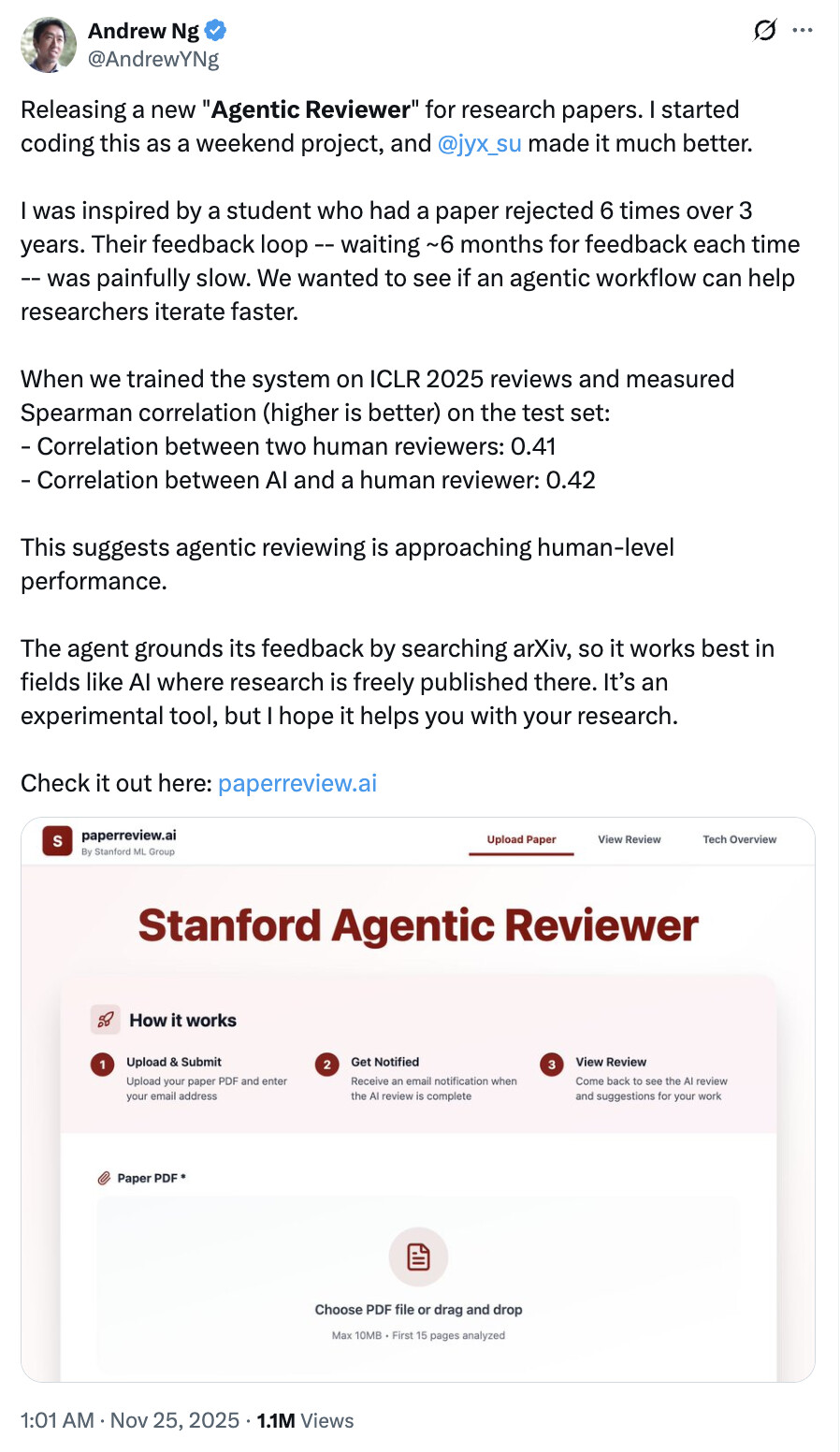
开发者在 ICLR 2025 审稿数据 上做了对比评测,使用的是 Spearman 相关系数。人类 vs 人类:0.41;AI vs 人类:0.42。开发者认为 agentic reviewing 正在逼近人类水平。
从整体评分结果来看,FARS 产出的 100 篇论文中,平均得分为 5.05(区间 3.0–6.3)。
少量论文处于 3.0–4.5 的低分段,也有极少数突破 6.0 分。
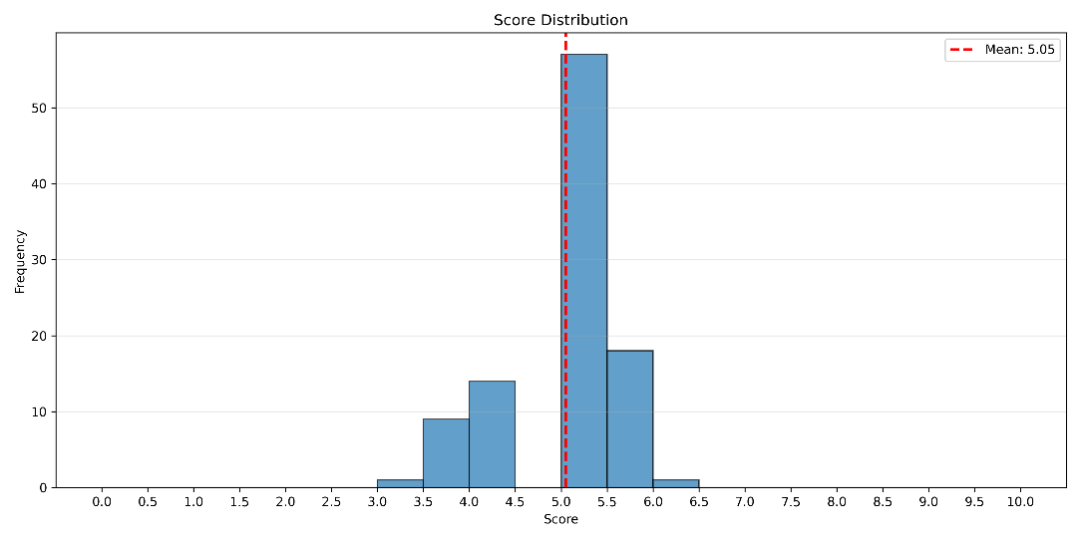
FARS 论文分数主要堆在 5 分附近,说明产出质量并不是随机波动,而是已经形成相对稳定的「质量带」。少量样本进入 6 分以上区间,意味着系统偶尔能产出超强作品。
这个成绩,与人类战绩相比,又如何呢?
作为参照,ICLR 2026 人类投稿的平均分为 4.21,而最终被接收论文的平均分为 5.39。
对照来看,FARS 的平均分 5.05,已经明显高于人类投稿的整体平均水平,但距离「平均中稿线」仍存在差距。
可谓比下有余,比上未满。
FARS 生成的学术论文平均分超过人类投稿者的平均水平,但与平均中稿分数仍有差距。
需要再次强调的是,本次自动化生产以短论文为主,并未以当前学术会议的评审标准作为优化目标。因此,无论是斯坦福大学 Agentic Reviewer 还是其他基于现有特定审稿标准的 AI 审稿结果,都只能作为一种参照,而非盖棺定论。
据团队透露,除 AI 审稿外,目前也在同步开展人工质量评审,并将在评估完成后形成综合质量报告。
即便在这一审慎前提下,将前后两部分数据合并观察,整体信号仍然较为清晰:在接近人类评审尺度的评价体系中,FARS 已然一台稳定的中分段输出机器。
论文深读:
从「极速跟进」到「直面失败」
如果说前面的数据与评分只能给出一条宏观刻度,那么具体论文样本,才真正暴露出 FARS 的研究成色。
已有网友拆解其中一篇 LLM-as-a-Judge 工作后评价,这类论文在摘要组织与问题切入上已经相当工整。
考虑这是 AI 自动产出,完成度已经「超出预期」。框架图、结果图、分析基本都齐全,「像那么回事」
也有人觉得编号为 FA0008 的项目「 make sense 」。

接下来,我们选择一成一败两篇代表作,一探究竟。
先看「做成」的一篇 FA0042。它瞄准的是文本 embedding 里一个老矛盾:
双向注意力质量高,但会破坏 KV-cache;因果注意力能流式推理,但表示能力吃亏。

FA0042 的解法非常工程导向——训练阶段用双向拿质量,推理阶段用因果保效率。具体路径是先训一个双向 teacher,再把能力蒸馏进 causal student。为了避免直接切双向带来的分布漂移,论文还引入了刚发布不久的 GG-SM 做渐进过渡。
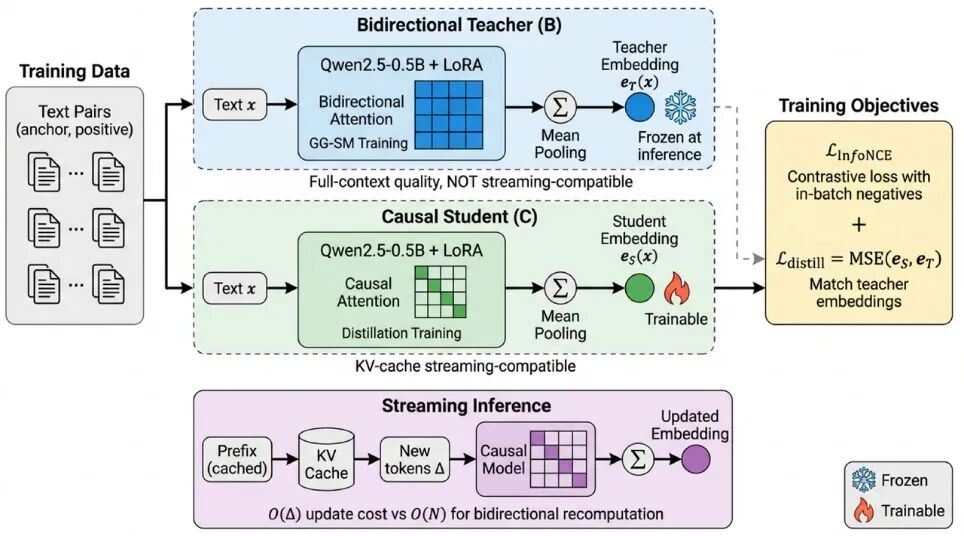
结果也确实「能打」, 这条工程折中路线被验证是 work 的。

MTEB-slice 主要结果
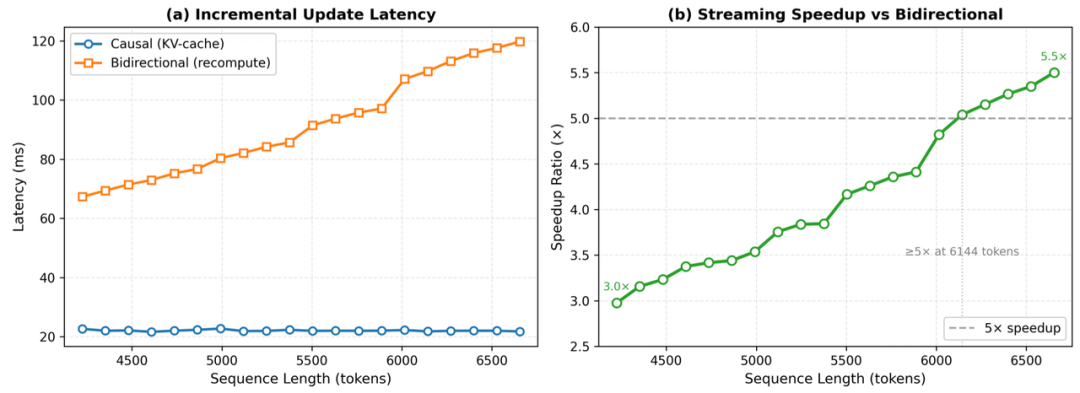
流式推理延迟对比
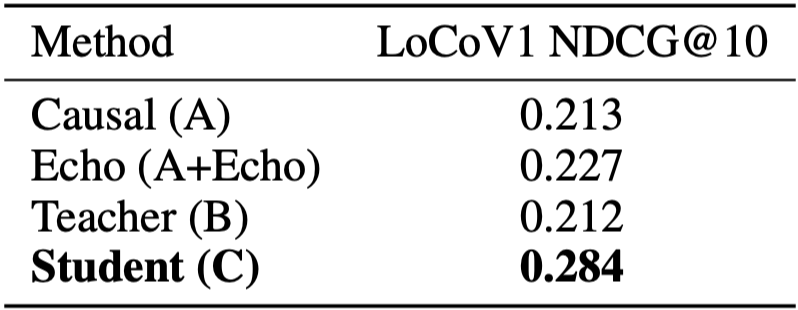
LoCoV1 长文档检索结果。student 模型以 0.284 的 NDCG@10 大幅领先所有 baseline(包括 teacher 的 0.212 ),出人意料。
当然,short paper 气质也很足:细粒度成对任务提升有限,长文档检索反超 teacher 的机制还没完全讲透。
但更值得注意的是,蚂蚁集团的 GG-SM 发布 3 天就被接入实验流程,这种紧跟前沿的速度,本身就是 FARS 系统敏捷性的一个信号。
再看一篇「没做成」的 FA0121。
它的文献调研很给力,盯上了 DeepSeek 新提出的 Engram 稀疏架构,并抓到了一个很研究味的问题——
hot-to-cold advantage flip , 即 Engram 中的门控( gate )在训练过程中难以准确根据 n-gram embedding 的实际效用进行调整,存在高频( hot )和低频( cold )偏置。

为了打破这种「马太效应」,FARS 尝试了一个直觉上非常硬核的方案:试图通过「反事实门控监督( CGS )」修复 DeepSeek Engram 架构中的「冷热偏置」问题。
在特定训练步骤中分别强制 gate 全开和全关,计算两种情况下的 loss 差值来估计当前 n-gram embedding 的实际效用,以此作为辅助监督信号来训练 gate。
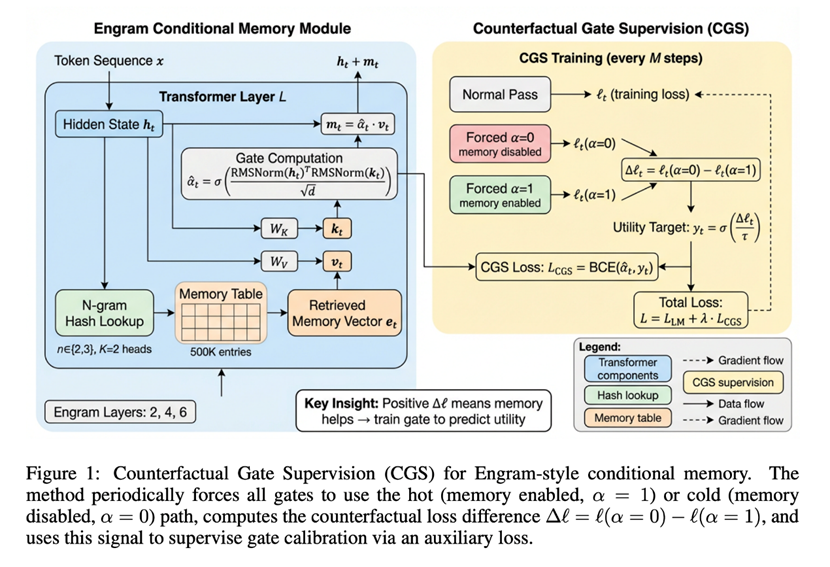
FA0121 方法示意图

主实验结果
思路很直觉。但结果很诚实——基本没救回来。
CGS 带来的那点提升,甚至不如让模型多训练几步来得实在。这说明,要解决 AI 的偏见,光靠「教练现场打分」是不够的,得从更深层的制度(架构)上下功夫。
论文给出的复盘也很到位:Gate 和 n-gram embedding 的训练是一个相互耦合的系统动力学问题,不是简单加监督就能补的。
这篇工作的价值正在于:它没有试图掩盖负面结果,没有为了追求正面结果而篡改数据或强行解释,而是通过一套严密的诊断性实验(Diagnostic Experiments ),反思 CGS 的失败。
这种「算法诚实」是当前学术界稀缺的品质。


舆论场:
从「又一个 Demo」到「科研流水线雏形」
随着 FARS 「直播真人秀」数据披露,社区讨论也迅速升温,高频指向一个关键词——生产线。
不少围观者很快抓住了真正的冲击点:这次引发不安的,并不是某一篇论文写得多惊艳,而是系统所展现出的连续科研运转能力。
当一个系统能够稳定提出假设、自动完成实验、并持续吐出成稿时,评价坐标其实已经悄然移动。问题不再是「 AI 会不会写论文」,而是更具结构性的那一句—— AI 是否开始具备科研工业产能的雏形。
这种叙事重心的变化,本身就意味着社区对 AI 科研系统的预期正在抬升。一些技术讨论甚至认为,LLM 在 AI 方向论文写作上的能力已「基本够用」,剩余差距更多体现在工程细节层面。
「 3 个月内就可能出现非常成熟可用的自动 paper pipeline。」

换言之,大多数人几乎已经默认:科研流水线时代,迟早会来。真正悬而未决的问题反而是,当科研开始规模化自动生产,人类的不可替代性究竟还剩下什么?
对此,也有人给出答案:决定上限的,或许仍是研究者个人品味。

当然,社区并非只有单一声音。
有人认为,与其关注单纯 scale 出大量「普通 conference paper 」,不如将算力与模型能力投入到真正困难的开放问题上,这或许才是更具长期价值的方向。

无限心智的起点
FARS 的这 100 篇论文,并不是终点,更像是一枚被钉下的坐标点。
它证明了一件很重要的事:端到端自动科研流水线,已经能够在相对稳定的运行条件下,持续产出具备一定学术竞争力的 short paper,并且开始展现出基础的自我纠错与负结果报告能力。
这意味着,自动化科研第一次以一种可连续运转的系统形态,正式进入现实。
但如果把放大镜再压近一层,当前阶段的天花板同样清晰可见。
FARS 很会把一条合理路径走通,却还不够擅长在复杂假设空间中做出真正具有突破性的研究取舍;能完成结构完整的论证,但在思想压强和机制洞察上仍有提升空间;而在算力利用率上,系统也还停留在明显的「算力换智能」阶段。
此刻的 FARS,更像一位极度勤奋、训练有素且从不疲倦的初级研究员,距离那种能够稳定打出顶会级工作的成熟研究者,仍有一段需要跨越的进化距离。
不过,真正重要的或许并不是它此刻已经多强,而是那条「无限心智生产线」,已经可以稳定地跑起来。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com