智谱GLM-5技术报告发布,揭示其在架构和异步强化学习上的创新,尤其Slime框架成为关键,助力Agentic Engineering。
原文标题:揭秘GLM-5技术底牌:「异步强化学习框架Slime」成终极杀招
原文作者:机器之心
冷月清谈:
怜星夜思:
2、GLM-5的Slime框架通过异步强化学习提升效率,这种方法是否可以推广到其他需要大量计算和反馈的AI训练任务中?会面临哪些挑战?
3、GLM-5在软件工程领域的应用,对于未来的程序员来说,意味着什么?是会被AI取代,还是会迎来新的工作方式?
原文内容
一边放出新一代旗舰基座模型 GLM-5 技术报告,展现其从底层架构到异步强化学习基准设施的深层创新硬实力;一边马年港股首个交易日收盘暴涨近 43%,市值突破 3200 亿港元。这一波,智谱属实「两开花」了。
到今天,对于打工人来说,这个「AI 味」浓厚的马年春节即将迎来尾声!
过去一周多的时间,机器人无疑是顶流中的顶流,「机器人全面入侵春晚」的词条更是一度占据了各大社交平台的热搜榜首。与此同时,作为当前主流机器人「大脑」的 AI 大模型,其范式与技术创新同样值得我们复盘。
这个春节,DeepSeek V4「鸽了」,但以字节 Seedance、智谱为代表的大厂及 AI 明星独角兽相继发布模型,同样是在技术路径上的一次「强势亮剑」。
其中,凭借新一代旗舰基座大模型 GLM-5 引爆全球开发者社区的智谱,在几天前将该模型完整的技术报告放了出来。

我们先来回顾一下 GLM-5 的核心亮点:
它面向 Agentic Engineering 打造,凭借更强的代码能力、更长的 200K 上下文、更好的 Agent 工具调用能力,尤其擅长处理复杂系统工程与长程 Agent 任务,准确率攀升明显。
在 Coding 与 Agent 任务上,GLM-5 在 SWE-bench、Terminal-Bench、BrowseComp、MCP-Atlas 等多个主流基准测试中取得开源 SOTA 级表现。这使得 GLM-5 成为构建通用 Agent 助手的理想基座选择,并推动 Agent 从「跑通 Demo」的玩具阶段跨越到「解决现实世界复杂工程问题」的生产力临界点。
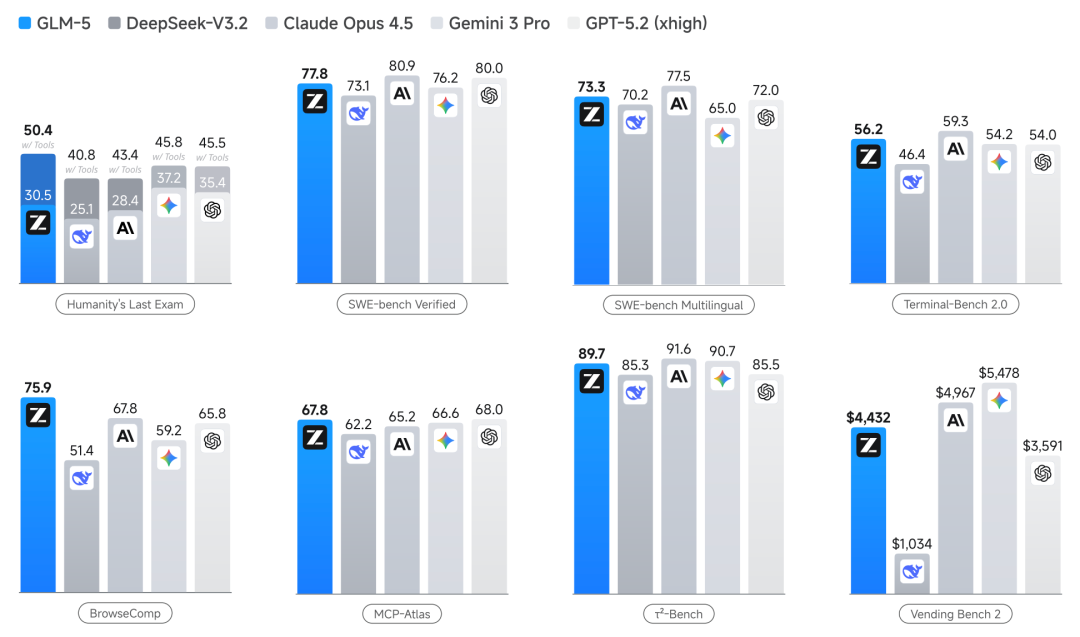
随着技术报告的释出,我们得以揭开其强悍性能背后的技术秘诀。总结来看,GLM-5 的核心创新点可以归纳为三点:
首先,GLM-5 在底层架构层面采用 DSA(DeepSeek Sparse Attention),在「长文本推理能力」与「训推成本」之间取得绝佳平衡。
其次,GLM-5 通过异步强化学习基础设施 —— Slime 框架,将「生成过程」与「训练过程」解耦,显著提升后训练阶段的效率。
最后,Agent 强化学习算法是 GLM-5 能够更高效地从复杂、长时序交互中学习的关键。
针对 GLM-5 的一系列创新,X 平台上一些大 V 给出了极高评价,「在处理端到端的软件工程挑战时,GLM-5 显著超越现有基线,标志着模型能力从『片段式响应』进化到『系统级交付』。」

图源:X@omarsar0
在大模型的发展历程中,很少有能力是凭空产生的。无论是架构设计、训练范式,还是数据处理与优化技巧,几乎所有领先模型都建立在既有研究成果与工程实践的基础之上。
从 Transformer 的提出到注意力机制的演进,再到强化学习与知识迁移方法的成熟,每一次突破都来自持续的迭代与吸收。
但在仔细研读 GLM-5 的技术报告之后,我们发现了智谱独特的技术品味。

-
技术报告原文链接:https://arxiv.org/pdf/2602.15763
-
GitHub 开源地址:https://github.com/zai-org/GLM-5
DSA:降低训练与推理成本
DSA(DeepSeek Sparse Attention)是 DeepSeek 提出的一种高效注意力机制。要理解它解决了什么问题,我们先要知道注意力机制是干什么的:模型在理解每一个词时,需要参考上下文中其他所有词,句子越长,需要参考的词越多,计算量呈平方级增长。对于动辄十万词的长文本,这个开销是灾难性的。
DSA 的核心思路是:不是每个词都同等重要,大多数词其实可以忽略。它通过动态打分,只挑出真正相关的少数 token 参与计算。实验证明,长文本中约 90% 的注意力计算是冗余的,DSA 把这部分直接省掉,在不牺牲理解能力的前提下,将长序列的计算量压缩了 1.5 到 2 倍。
得益于 DSA,GLM-5 得以将模型参数规模扩展至 744B(40B 激活参数),训练 token 总量提升至 28.5T。但用 DSA 和把 DSA 真正用好之间,有一段不短的工程距离。
当 DSA 与 MLA(Multi-Latent Attention)、自研 Muon 优化器等既有组件叠加时,团队发现模型在多个基准上出现性能退化。
为此,GLM-5 提出 Muon Split 机制:将矩阵拆分为不同头的更小矩阵,并对这些独立矩阵应用矩阵正交化,使得不同注意力头的投影权重能够以不同尺度更新。
另外,针对 MLA 解码计算成本高难题,GLM 团队提出了 MLA-256 变体:把 head dimension 从 192 提到 256,同时把注意力头数减少 1/3,使训练计算量和参数量保持不变,但解码计算量显著下降。
为进一步提升基础模型性能,智谱还提出在训练阶段共享 3 层 MTP 的参数。这样既保持了草稿模型与 DeepSeek-V3 相同的内存开销,又提升了 token 的接受率。
在当前大模型竞争格局中,参数规模已不再是唯一的护城河。真正的壁垒在于如何在算力预算、长上下文忠实度与工程稳定性之间取得平衡。
GLM-5 在 DSA 体系上的实践提供了一个清晰的答案:不再盲目追求无限堆砌算力,而是通过重构计算路径,让模型在同等资源下完成更高效的工作。 如果说大模型的前半场是在比拼「谁做得更大」,那么 GLM-5 则标志着下半场的开启,在长程推理与 Agent 时代,谁能把计算结构设计得更「聪明」,谁才能在端到端的软件工程等复杂任务中胜出。
异步 RL 基础设施:Slime 框架的工程创新
在从「文本生成」向「自主代理(Agent)」进化的过程中,传统同步强化学习的低效与长程推理的昂贵成本成为了最大的阻碍。
传统同步 RL 的流程是:生成一批轨迹→等所有轨迹完成→送入训练→更新权重→再生成下一批。但问题在于,智能体任务的轨迹长度极度不均匀,修一个简单 bug 可能 3 步,实现一个复杂功能可能需要 50 步以上。同步模式下整批训练的速度由最慢的那条轨迹决定,GPU 在等待中大量空转,造成资源浪费。
GLM-5 的核心解法是将推理引擎与训练引擎部署在不同 GPU 设备上,完全异步并行运行。 推理引擎持续生成轨迹,积累到预定阈值后批量推送给训练引擎;训练引擎持续消费数据、更新参数,每完成 K 次梯度更新后将新权重同步回推理引擎。两条流水线互不阻塞,GPU 利用率大幅提升。
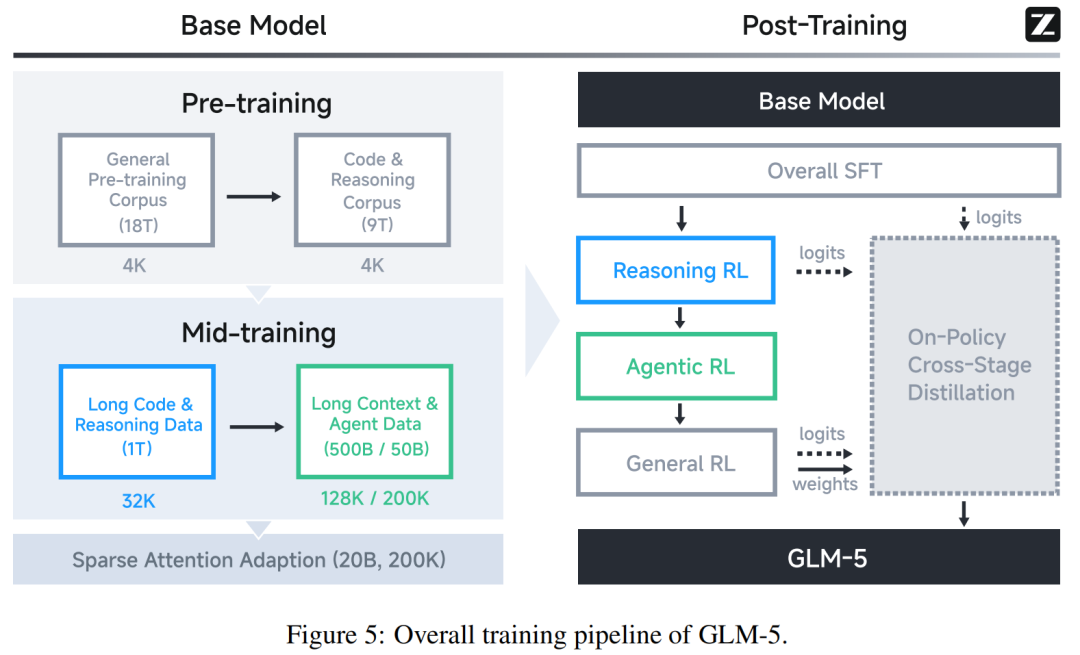
但异步 RL 中有一个看似微小但后果严重的问题:如果推理引擎输出文本,训练端再重新 tokenize,哪怕是空白符处理、特殊 token 位置、截断方式的细微差异,都可能导致 action 和 reward 之间的对应位置出错,这种错位会持续累积,最终破坏 RL 信号的准确性。
TITO Gateway 的解法是直接截获推理引擎产生的 token ID 序列和元数据,绕过任何文本中转,确保训练端使用与采样完全一致的 token 流。
此外,异步训练中,一条轨迹的生成过程中模型可能已经更新了多次,精确追踪行为策略概率几乎不可行,否则需要维护大量历史 checkpoint,存储和通信开销极高。
GLM 团队提出直接双侧重要性采样:直接复用 rollout 时记录的 log 概率作为行为策略代理。并采用双侧 token 级掩码:重要性采样比落在区间范围内的 token 正常计算梯度,超出范围的 token 梯度直接置零。
这些设计听上去像是工程层面的补丁,但它们解决的,其实是一个更根本的问题:如何让大规模 Agent 强化学习在现实算力条件下真正跑得起来、稳得住。如果说同步 RL 更适合短轨迹、规则明确的任务,那么 GLM-5 这一套异步机制,则是为长程软件工程、复杂工具调用、多轮交互决策场景量身打造的。它让模型不再被训练框架拖慢节奏,而是能够在持续交互中不断生成、评估、更新,形成近似在线学习的循环。
锻造工业级长程智能体,非一役之功
解决了训推效率与工程落地难题,接下来就要进入长程软件工程的实战环节了。
GLM 团队发现,在将底层 DSA 架构与大规模 RL 训练结合时,短短数步之内就会出现崩溃、损失异常以及模型能力快速退化等情况。在一番摸查之后,根源定位到了 DSA 内部使用的非确定性 CUDA top-k 算子,其输出的不稳定性干扰了 RL 的梯度更新。
因此,在将该算子替换为确定性的 torch.topk 之后,虽然牺牲了微小的运行速度,但可以让训练立刻恢复稳定并带来显著的性能收益。同时,为了避免 RL 阶段的无效学习干扰,还对索引器参数(Indexer)进行了冻结。
不仅如此,GLM 团队还通过以下一系列创新性解法,全方位克服 RL 在复杂智能体任务中的数据短缺、审美、遗忘等其他难题。
首先,软件工程任务的 RL 训练最缺的是「考场」,现有数据集不仅规模小,还极易受到数据污染。
GLM 团队基于 RepoLaunch 框架,构建了 10000 + 可验证的 SWE 环境,覆盖了 Python、Java、Go 等 9 种主流编程语言。并且,每个环境支持从依赖安装到测试解析的全流程自动化。这意味着,模型对代码的修改是否有效,全凭单元测试说了算,不再依赖主观且低效的人工打分,从而实现 RL 信号的真实可靠。
其次,智能体不仅要会写代码,还要懂设计。GLM-5 引入了以 HTML 幻灯片为载体的三级奖励体系,在结构化文档生成的「审美」方面形成了自己的风格:
-
Level-1(静态规则):检查布局、间距、字体等基础属性,并利用 AI 识别幻觉与重复图片。
-
Level-2(运行布局):通过分布式渲染,抓取渲染后 DOM 节点的宽高、边界框等真实几何指标,搞定静态代码看不出的排版冲突。
-
Level-3(视觉感知):直接从视觉层面检测异常空白或构图失衡,确保看起来舒服。
一套流程走下来,效果立竿见影,GLM 团队识别并修复了两类奖励破解行为,将 16:9 合规率从 40% 提升至 92%。
接下来要面对多阶段 RL 训练中的灾难性遗忘问题。GLM-5 的后训练依次分为推理 RL、智能体 RL、通用对齐 RL 等三个阶段,遗忘问题会导致后续阶段覆盖前序积累的能力。
为此,GLM 团队引入了「跨阶段蒸馏」,将当前策略与各个前序阶段的最优教师模型进行对数概率对比。这样既可以让模型掌握新能力,也会靠拢之前的最优状态。一种设计达成两个目标:在克服遗忘的同时通过简化算法逻辑提升训练效率。
最后还要为搜索智能体配上「长短期记忆」。GLM 团队发现,当上下文超过 100K 时,传统的清空所有工具记录的方案会造成浪费,而保留所有记录又可能导致混乱。
GLM 团队提出了分层上下文管理(HCM,Hierarchical Context Management)策略,在实践中先试着折叠早期记录,并保留最近 5 轮记忆。如果还是太大,则清空所有工具调用历史,然后重置。结果显示,这种分层组合方案让 GLM-5 在 BrowseComp 任务上的准确率从 55.3% 暴涨至 75.9%,一举超越了现有已知的开源上下文管理方案。
可以看到,通过对长程交互中每一个细节的极致掌控,包括底层算子、环境构建以及如何让模型长记性,GLM 团队全给理顺了。
当然,GLM-5 还全栈适配了国产 GPU,包括华为昇腾、摩尔线程、海光、 寒武纪、昆仑芯、沐曦、燧原等七家主流国产芯片平台,进一步拓宽算力生态。
以上构成了 GLM-5 技术底色的完整轮廓,它们不是调参的结果,不是重新包装的已有工作,而是在真实工程实践中遇到真实问题、提出真实解法的过程。
写在最后
十天前,图灵奖得主、RL 大佬 Richard Sutton 以远程连线的方式,在加州大学洛杉矶分校(UCLA)的纯粹与应用数学研究所(IPAM)发表了名为《AI 的未来》(The Future of AI)的最新演讲。

图源:https://www.youtube.com/watch?v=lieqoaBV6ww
演讲中,Sutton 表达了这样一种观点:尽管当下的 AI 仍受限于对人类数据的学习,但未来的 AI 将立足于从交互经验中学习。这样的范式能让模型持续获取新知识,从而爆发出远超现状的演进潜力。
这一观点与 GLM-5 发力 Agentic Engineering 并推进「系统级交付」的范式选择不谋而合:让 AI 脱离人类预设的指令集,转而在长程真实或虚拟环境中通过 RL 实现自我进化。
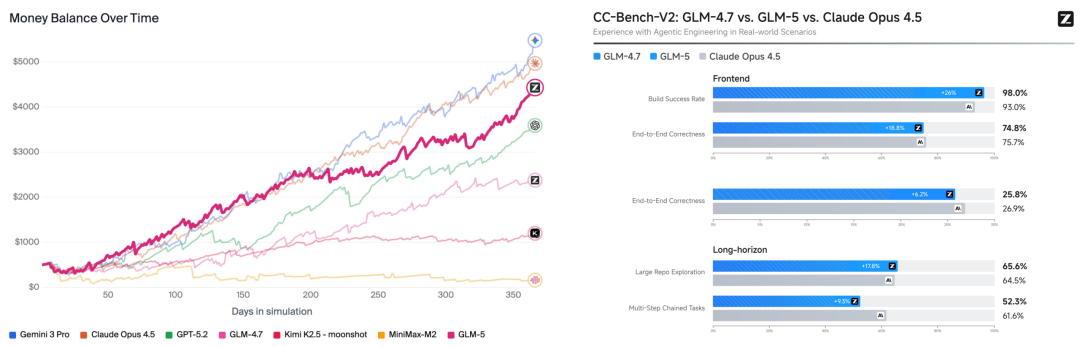
在长程规划与资源管理能力上,GLM-5 证明了其实力。如下图左的 Vending-Bench 2(让 AI 模拟自动售货机一整年)和图右的 CC-Bench-V2(智谱 AI 官方内部测试)基准结果所示,GLM-5 的表现接近并在一些任务上能够超越 Claude Opus 4.5。
根据 Artificial Analysis 最近的一项数据显示,相较于 Anthropic 最强的 Claude Opus 4.6,作为开源模型的 GLM-5 与其之间的智能差距已经缩小到史无前例的程度。
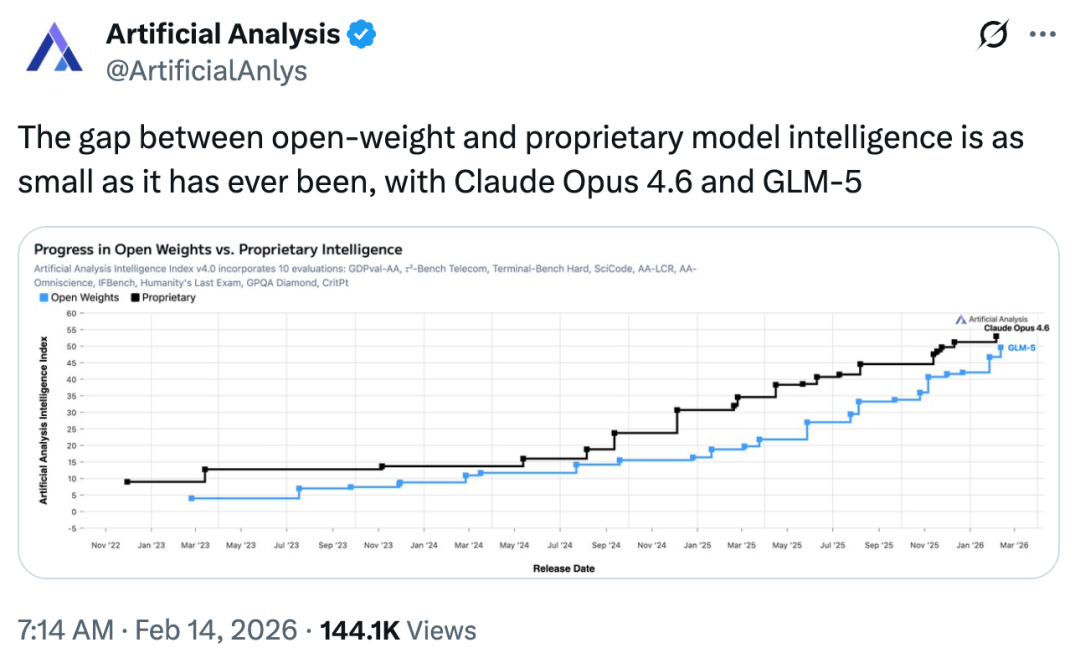
在开源步步逼近闭源竞品的路上,GLM-5 交出了一份令业界惊叹的答卷。
而这仅仅是智谱在 Agentic Engineering 路径上的首次出手,下一代 GLM 旗舰模型又将进化到何种程度,我们拭目以待。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com