多模态大模型面临长上下文Token爆炸难题?这篇综述深入剖析了图像、视频、音频的Token压缩机制,为高效MLLM指明方向。
原文标题:TMLR 2026 | 首篇多模态长上下文Token压缩综述:浙大、西湖大学等全面解析MLLM效率瓶颈
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到了多种Token压缩方法,例如基于变换、相似度、注意力等。这些方法各有优缺点,那么,在实际应用中,我们应该如何选择合适的方法?有没有一个选择的流程图或者决策树?
3、文章提到了未来可能的发展方向,包括跨模态协同压缩和原生高效架构。你认为哪一个方向更有前景?为什么?
原文内容

随着 GPT-4o、Gemini 3Pro 等模型的爆发,多模态大语言模型(MLLM)正在处理越来越长的上下文(Long Context)。
然而,一张高清图、一段长视频或长音频产生的 Token 数量往往是文本的数千倍,不仅挤占了宝贵的上下文窗口,更因自注意力机制的二次复杂度导致推理成本飙升。如何「给 Token 瘦身」?
近日,来自浙江大学、西湖大学等机构的研究者发布了首篇关于多模态长上下文 Token 压缩的系统性综述,已被 TMLR 2026 接收。该文提出了统一的分类体系,深入剖析了图像、视频、音频模态的压缩机制,为高效 MLLM 的研究指明了方向。

-
论文标题:A Survey of Token Compression for Efficient Multimodal Large Language Models
-
论文链接:https://arxiv.org/abs/2507.20198
-
论文集:https://github.com/cokeshao/Awesome-Multimodal-Token-Compression
-
OpenReview:https://openreview.net/forum?id=G2od9JVHkE
多模态大语言模型(MLLM)在视觉问答、视频理解和语音交互等任务上展现了惊人的能力。这些能力很大程度上源于模型对长而复杂上下文的处理能力 —— 无论是高分辨率图像、长达数小时的视频,还是长语音输入。
然而,这种能力并非没有代价。随着 Token 数量的增加,Transformer 架构中自注意力机制(Self-Attention)的计算复杂度呈二次方增长。
Token 爆炸问题有多严重?
如下图所示,一段 90 分钟的视频如果不经处理,可能会产生高达 5400 万个 Token(假设 1fps 采样),这远远超过了当前顶尖模型(如 Gemini 2.5)的百万级上下文窗口。更重要的是,视觉和听觉数据中存在大量冗余 —— 研究表明,推理过程中超过 50% 的 Token 获得的注意力极低。
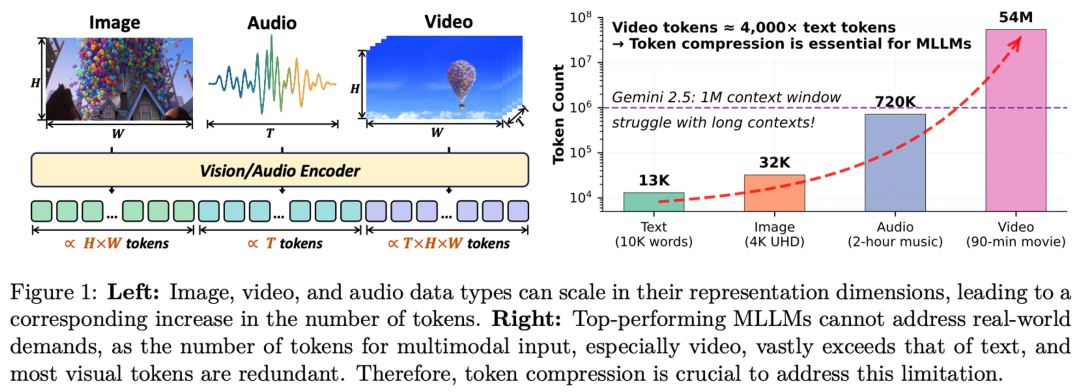
为了解决这一计算瓶颈,Token 压缩(Token Compression)成为了一种关键技术。它旨在训练或推理阶段,在保留关键语义信息的前提下,大幅减少传递给 LLM 的 Token 数量。
全新的分类体系:从模态到机制
由于不同模态的数据冗余特性各不相同(例如图像的空间冗余 vs. 视频的时空冗余),该综述首先依据数据模态将现有工作分为三大类:
-
以图像为中心的压缩(Image-centric): 解决视觉数据的空间冗余。
-
以视频为中心的压缩(Video-centric): 解决动态序列中的时空冗余。
-
以音频为中心的压缩(Audio-centric): 解决声学信号中的时间和频谱冗余。
在此基础上,作者进一步根据底层算法机制,将方法细分为四种类型:
-
基于变换(Transformation-based): 如池化、卷积,直接改变特征的物理形态。
-
基于相似度(Similarity-based): 如聚类、合并,将相似的 Token 融合成一个。
-
基于注意力(Attention-based): 利用 Attention Score 剪枝,保留高显著性区域。
-
基于查询(Query-based): 使用 Learned Queries(如 Q-Former)或文本引导来筛选信息。
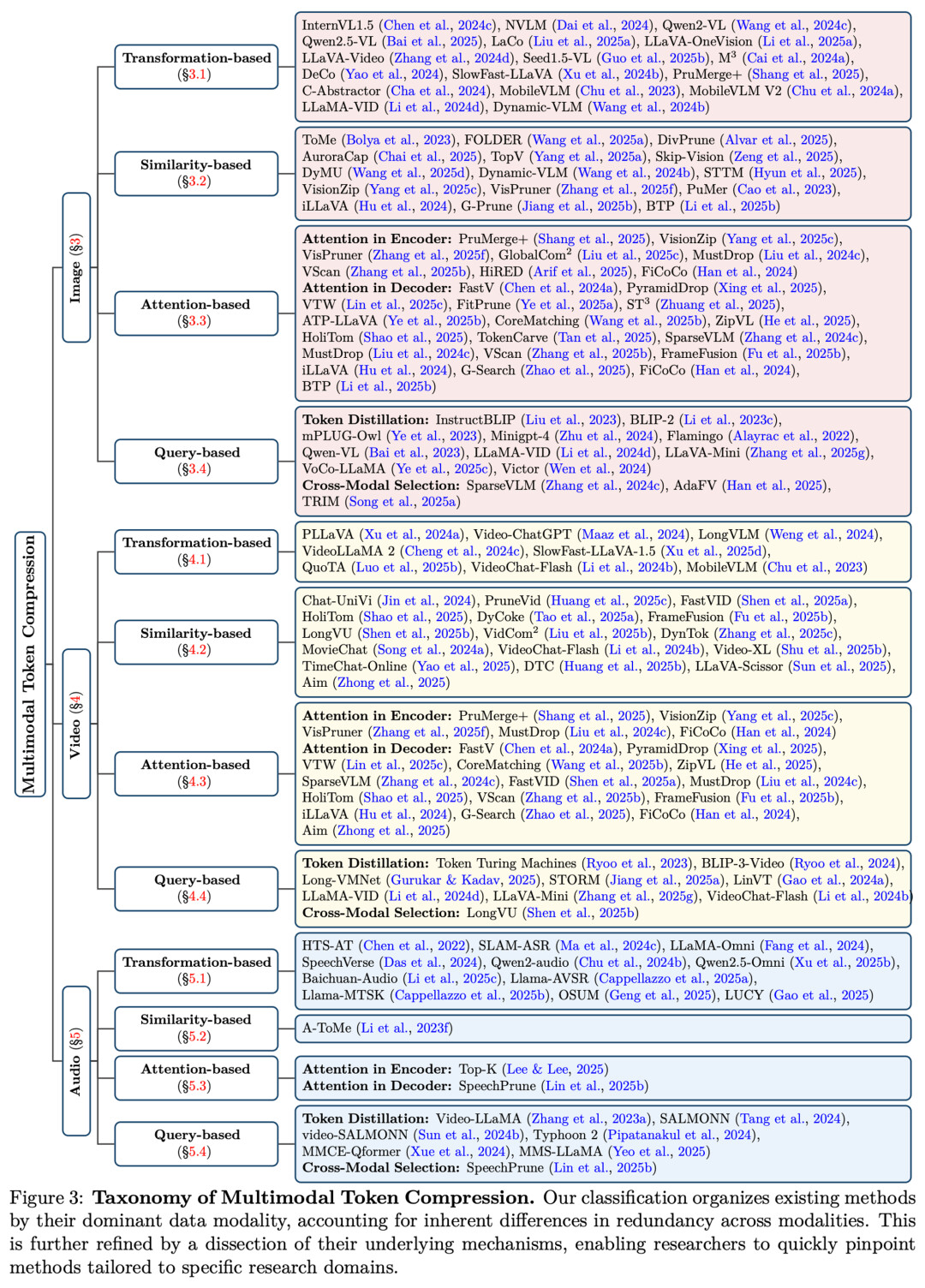
同时,作者总结了这四类机制的优缺点,为研究者选择合适的方法提供了直观参考。
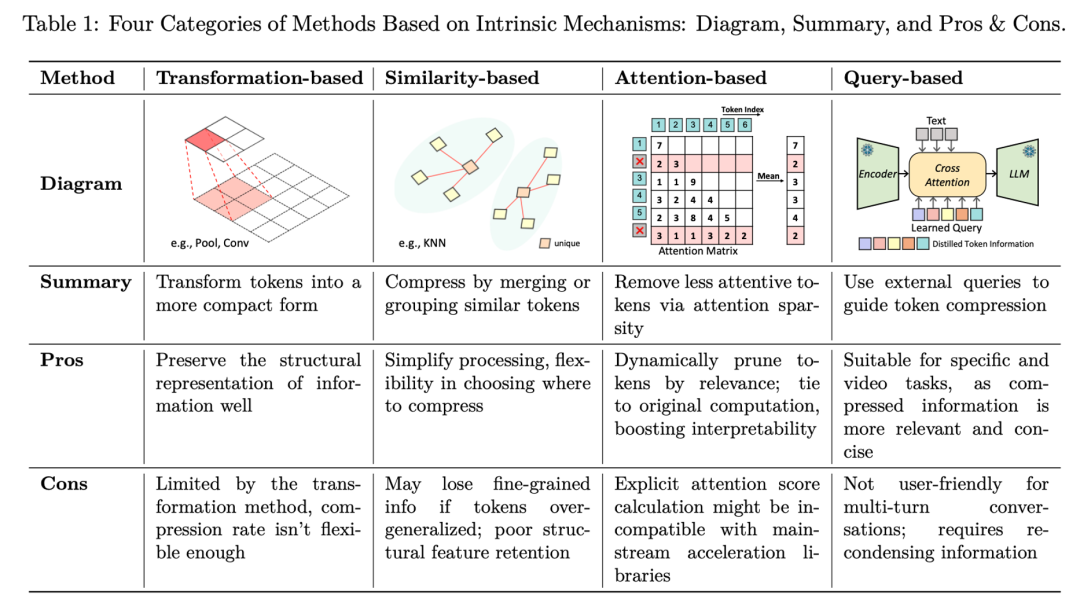
1. 图像 Token 压缩:从空间冗余入手
图像 Token 是 MLLM 中最主要的输入来源之一。高分辨率图像虽然带来了丰富的细节,但也引入了巨大的计算开销。
-
基于变换(Transformation-based): 如 InternVL 和 LLaVA-OneVision 采用的 Pixel Unshuffle 或双线性插值。这类方法不筛选 Token,而是通过改变特征的物理形态(如降低分辨率但增加通道数)来保留所有信息的结构化表示。
-
基于相似度(Similarity-based): 如 ToMe 和 VisionZip。利用图像块(Patch)之间的视觉相似性,将冗余的背景或纹理进行聚类合并,减少计算量。
-
基于注意力(Attention-based): 分为编码器端(如 PruMerge+)和解码器端(如 FastV)。前者利用 ViT 的注意力分数在进入 LLM 前剔除 Token,后者则发现 LLM 深层对视觉 Token 的关注极低,从而在推理过程中动态剪枝。
-
基于查询(Query-based):如 Q-Former、LLaMA-VID 则通过少量的 Query Token 来「蒸馏」整张图像的信息。
2. 视频 Token 压缩:攻克时空冗余
视频不仅包含空间信息,还包含时间维度。视频压缩的核心挑战在于:如何在压缩海量帧的同时,保留运动和时间动态。
-
时空冗余消除: 视频中相邻帧往往高度相似。Chat-UniVi 等方法采用基于相似度的聚类算法,将静态背景或重复帧合并为一个代表性 Token,仅保留发生变化的动态区域。
-
查询引导的帧选择: 针对长视频理解,LongVU 等方法利用用户的文本提问作为 Query,计算每一帧与问题的相关性。这种方法能跳过大量无关帧,仅将与问题最相关的「关键帧」Token 输入 LLM,从而在有限的上下文窗口中处理小时级视频。
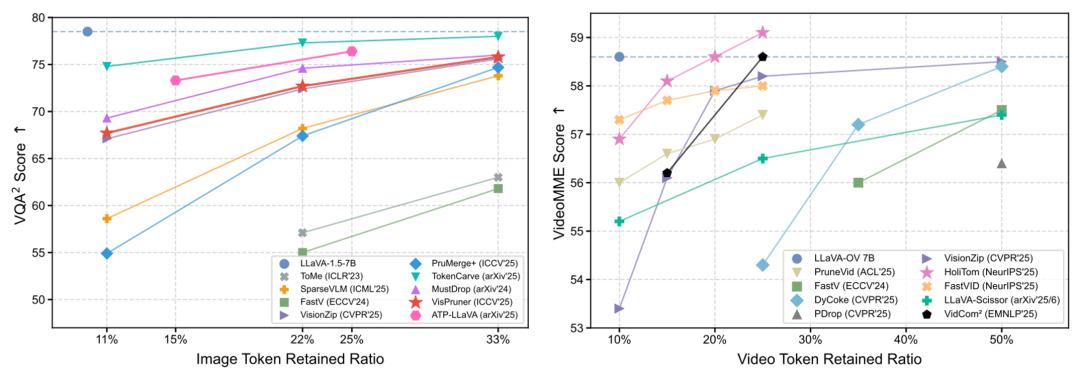
3. 音频 Token 压缩:处理静音与噪声
音频数据具有高采样率特性(1 秒音频可能包含数万采样点),且存在独特的冗余。
-
序列降维: 由于音频通常被处理为 Mel 频谱图或一维序列,Qwen2-Audio 等模型采用一维卷积(1D Convolution)或 Token 堆叠(Stacking)技术,直接在时间维度上进行下采样,大幅缩短序列长度。
-
跨模态语义过滤: 音频中常包含静音片段或背景噪声。SpeechPrune 等方法利用文本 - 音频的对齐关系,通过注意力机制识别并保留包含语音语义的有效片段,剔除无意义的噪声 Token,实现「听觉 - 语义」层面的高效压缩。
挑战与展望
尽管 Token 压缩技术已经取得了显著进展,综述最后也指出了当前面临的几个关键挑战:
-
性能与效率的权衡: 极高的压缩率往往会导致细粒度任务(如 OCR、微小物体检测)的性能急剧下降。
-
部署难题: 部分基于 Attention 动态剪枝的方法依赖于实时计算 Attention Score,这与 FlashAttention 等现代加速库不完全兼容。
-
多轮对话的适应性: 现有的 Query-based 方法在多轮对话中可能需要针对新问题重新计算,效率受限。
未来方向
-
Omni-modal 联合压缩: 随着 GPT-4o 等全能模型的出现,利用音频引导视频压缩、文本引导图像压缩的跨模态协同压缩(Cross-modal Synergy)将是巨大的潜力点。
-
原生高效架构: 从模型设计之初就通过线性 Attention 或状态空间模型(如 Mamba)来解决长序列问题,而非仅依靠后处理压缩。
总结
这篇综述为多模态大模型的效率优化提供了一份详尽的「路书」。对于希望在资源受限设备上部署 MLLM,或希望处理超长视频 / 文档的研究者和工程师来说,理解并应用 Token 压缩技术将是必经之路。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com