BridgeV2W通过具身掩码连接视频生成模型与机器人世界模型,让机器人学会“预演未来”,解决动作画面“语言不通”等难题,无需URDF或相机标定即可利用海量无标注人类视频。
原文标题:仅凭"动作剪影",打通视频生成与机器人世界模型!BridgeV2W让机器人学会"预演未来"
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到BridgeV2W可以利用海量无标注的人类视频进行训练,那么,仅仅通过观看人类操作视频,机器人能学到哪些知识?这种学习方式存在哪些局限性?
3、BridgeV2W在不同机器人平台和场景下都表现出了良好的泛化能力,那么,这种方法是否适用于更复杂的任务,例如需要多机器人协同完成的任务?
原文内容

机器人如何 "脑补" 未来?
想象一下,你面前摆着一杯咖啡,你伸手去拿,在你的手真正触碰到杯子之前,你的大脑已经在 "脑补" 了整个过程:手臂将如何移动、杯子会是什么触感、抬起后桌面的样子…… 这种对未来场景的想象和预测能力,正是人类操控世界的核心认知基石。
那么,能否赋予机器人同样的 “预演能力”,先在 “脑海” 中模拟动作后果,再付诸执行?这就是具身世界模型要做的事情:让机器人在行动前,就能 “看见” 未来。近年来,借助大规模视频生成模型(如 Sora、Wan 等)强大的视觉先验,这一方向取得了令人瞩目的进展。
然而,一个尴尬的问题始终悬而未决:视频生成模型的世界由像素编织而成,而机器人的语言却是关节角度与位姿坐标,它们使用完全不同的 “表征语言” 描述同一个物理世界。
为了解决上述问题,具身智能公司中科第五纪联合中科院自动化所团队推出 BridgeV2W,它通过一个极为优雅的设计,具身掩码(Embodiment Mask),一种由机器人动作渲染出的 “动作剪影”,将坐标空间的动作无缝映射到像素空间,从而真正打通预训练视频生成模型与世界模型之间的桥梁,让机器人学会可靠地 “预演未来”。

-
论文标题:BridgeV2W: Bridging Video Generation Models to Embodied World Models via Embodiment Masks
-
论文链接:
-
项目链接:
困境:三座大山挡住了机器人的 "预演能力"
尽管前景广阔,当前的具身世界模型仍面临三大核心挑战:
1. 动作与画面 “语言不通”。 机器人动作是关节角、末端位姿等坐标数值,而视频生成模型只 “看” 像素。直接拼接动作向量效果有限,往往缺乏空间对齐的 “硬连接”,模型难以理解。
2. 视角一变,世界就 “崩”。同一动作在不同视角下外观迥异。现有方法在训练视角上尚可,一旦换视角,预测质量骤降,而真实场景中,相机位置几乎不可能复现训练设置。
3. 换一个机器人就得 “从零开始”。 单臂、双臂、移动底盘…… 结构千差万别。现有方法往往需为每种机器人定制架构,难以构建统一的世界模型。
核心创新:仅凭 "动作剪影",一举破解三大难题
BridgeV2W 的核心洞察极其直觉:既然鸿沟源于 “坐标 vs 像素”,那就把动作直接 “画” 进画面里!
它提出具身掩码:利用机器人的 URDF 模型和相机参数,将动作序列实时渲染为每帧图像上的二值 “动作剪影”,精准标出机器人在画面中的位置与姿态。
这一设计,一举破解前述三大难题:
-
动作 - 像素对齐: 掩码是天然的像素级信号,与视频模型输入空间完全匹配,无需模型 “猜” 坐标的含义。
-
视角自适应: 掩码随当前相机视角动态生成,动作与画面始终对齐,模型因此天然泛化到任意新视角。
-
跨具身通用: 只要提供 URDF,单臂、双臂机器人都能用同一套框架生成对应掩码,无需修改模型结构。
技术上,BridgeV2W 采用 ControlNet 式的旁路注入,将掩码作为条件信号融入预训练视频生成模型,在保留其强大视觉先验的同时,赋予其理解机器人动作的能力。此外,为防止模型 “偷懒”(只复现静态背景),还引入光流驱动的运动损失,引导其聚焦于任务相关的动态区域。
实验结果:多场景、多机器人、多视角的全面验证
研究团队在多个设置下系统验证了 BridgeV2W 的能力,涵盖不同机器人平台、不同操作场景、未见视角和下游任务应用。
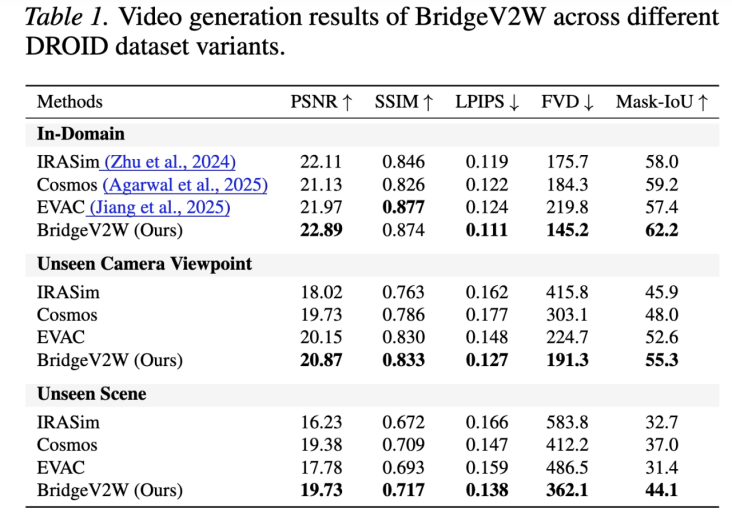
DROID 数据集:大规模单臂操作
DROID 是目前最大规模的真实世界机器人操作数据集之一,数据采集跨越多个实验室和环境。BridgeV2W 在该数据集上的表现尤为亮眼,在 PSNR、SSIM、LPIPS 等核心指标上超越 SOTA 方法。
尤其在 “未见视角” 测试中,对比方法常出现画面崩塌、肢体错位,而 BridgeV2W 依然生成物理合理、视觉连贯的未来视频,充分验证了其视角鲁棒性。在 “未见场景”(全新桌面布局、背景)下,泛化能力同样出色。

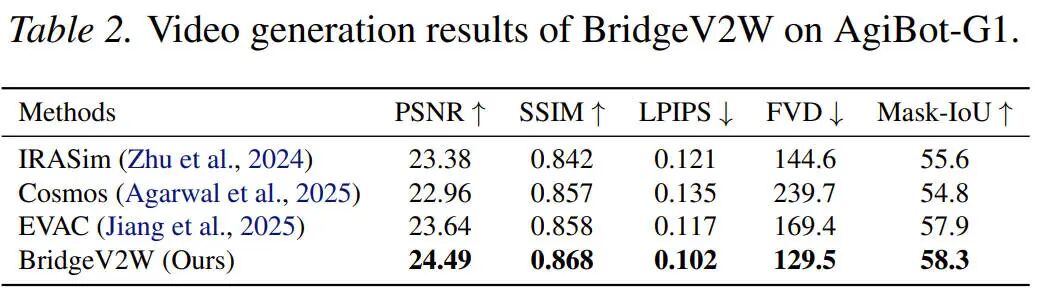
AgiBot-G1 数据集:双臂人形机器人
AgiBot-G1 是一个完全不同的双臂平台,自由度与运动模式与 DROID 截然不同。
关键结果:无需修改模型架构,仅替换 URDF 并重新渲染掩码,BridgeV2W 就能无缝适配,并取得媲美单臂的预测质量,这是迈向通用具身世界模型的重要一步。

下游任务应用:从 "想象" 到 "行动"
BridgeV2W 不仅仅是一个 "能生成好看视频" 的模型,研究团队进一步在真实世界的下游任务中验证了其实用价值:
策略评估: 在世界模型中 “试跑” 不同策略,无需真实机器人反复试错。实验显示,BridgeV2W 的评估结果与真实成功率高度相关,大幅降低策略迭代成本。
目标图像操作规划: 给定一张目标图像(如 “把杯子放到盘子上”),BridgeV2W 能在 “想象空间” 中搜索出可行动作序列,实现从视觉目标到物理动作的闭环规划。
关键亮点:海量无标注人类视频,全都能用!
你可能会问:具身掩码不是需要 URDF 和相机参数吗?没有这些几何信息的数据怎么办?
BridgeV2W 的巧妙之处在于:
-
推理时需轻量几何信息(URDF + 相机参数)渲染 “计算掩码”,用于精准控制;
-
训练时却无需任何标定:只需分割模型(如 SAM)提取的 “分割掩码”,即可提供有效监督。
团队将 AgiBot-G1 机器人数据与无标定的 Ego4D FHO(第一人称手部操作视频)混合训练,仅用 SAM 提取的手部掩码,就实现了惊人效果:
-
仅用分割掩码训练,模型仍能学到合理的运动规律;
-
加入大量 Ego4D 视频 + 少量机器人标定数据,性能几乎媲美全量标定训练。
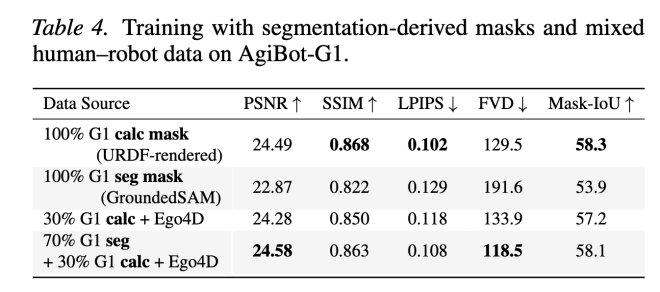
这说明:人类视频蕴含丰富的动作先验,只需少量机器人数据,就能完成 “具身对齐”。
一句话总结:训练靠 “野生” 视频扩规模,部署靠轻量几何保精度:BridgeV2W 兼得可扩展性与准确性。
BridgeV2W 揭示了一条极具前景的技术路线:
视频生成模型 + 具身掩码 = 可扩展的机器人世界模型
这条路线有三个关键优势值得深思:
1. 数据飞轮真正启动:互联网视频规模远超机器人数据数个数量级。BridgeV2W 无需几何先验即可利用人类视频,为构建 “机器人数据飞轮” 迈出关键一步。
2. 技术红利自动继承:视频生成领域正高速迭代(Sora、Wan、CogVideoX……)。BridgeV2W 的架构使其能自然受益于底座模型升级,底座越强,“预演” 越真。
3. 通用智能的坚实基石:从单臂到双臂,从已知场景到未知视角,BridgeV2W 展现出的跨平台、跨场景、跨视角泛化能力,是迈向通用具身智能的重要里程碑。
总结与展望
BridgeV2W 通过 “具身掩码” 这一简洁而优雅的中间表征,成功架起了从大规模视频生成模型到实用具身世界模型的桥梁。它不仅解决了动作 - 像素对齐、视角鲁棒性、跨具身通用性三大核心挑战,更关键的是:训练无需 URDF 或相机标定,可直接利用海量无标注人类视频,为世界模型的规模化训练开辟了全新路径。
目前展现的能力,或许只是冰山一角。
试想未来:当视频生成底座从十亿参数迈向千亿,当训练数据从数千小时机器人视频扩展到百万小时人类操作视频,当具身掩码从机械臂延伸至全身人形、乃至多机协作,机器人的 “预演能力” 将迎来怎样的飞跃?
正如 DreamZero 等工作预示的 “机器人 GPT 时刻”,BridgeV2W 从另一个维度证明:
让机器人借助视频生成模型 “预演” 自身行动的后果 —— 这条路,不仅走得通,而且可以走得很远。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com