研究表明,扩散模型虽然速度快,但在智能体任务中因果推理能力不足,格式输出易混乱。DiffuAgent评估框架揭示了其在不同模块中的优劣势,并提出了改进建议。
原文标题:速度提升,能力却暴跌?扩散模型做智能体的残酷真相
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到,扩散模型在工具调用任务中,选择能力强但格式修正能力弱,那么有没有什么办法可以结合两者的优势,让扩散模型在工具调用上也能大放异彩?
3、文章建议“建立面向智能体应用的基准体系”,那么具体来说,这种基准体系应该包含哪些要素?应该如何设计才能更有效地评估智能体的能力?
原文内容

来源:机器之心本文约2500字,建议阅读5分钟扩散语言模型在智能体能力方面存在系统性缺陷,显著落后于同规模的自回归模型。
基于自回归语言模型的智能体已在许多场景中展现出完成复杂任务的能力,但高昂的推理成本和低下的执行效率问题仍然是制约智能体工作流(Agentic Workflow)发展的关键瓶颈。
与传统的自回归式语言模型不同,扩散语言模型(Diffusion-Based Language Models)采用并行解码机制,显著提升了生成速度,似乎为突破这一瓶颈带来了全新的可能性。
现有的关于 Llada、Dream 等扩散语言模型的研究中,这类模型在大幅度提高生成效率的同时,在 MMLU、GSM8K 等基准任务上保持了与自回归语言模型相当的通用能力。然而其在智能体任务上的表现尚缺乏系统性的评估。
基于这一问题,近期南洋理工大学的陶大程教授团队联合东南大学、阿里巴巴等发布了一份综合评测报告,通过对 2 个自回归语言模型和 4 个扩散语言模型在具身智能体(Embodied Agent)和工具调用智能体(Tool-Calling Agent)上的一系列实验,揭示了一个反直觉的发现:扩散语言模型在智能体能力方面存在系统性缺陷,显著落后于同规模的自回归模型!
这项工作揭示了一个深刻的教训(Bitter Lesson):尽管扩散语言模型实现了高效的并行推理,但也显著削弱了其因果推理和反思能力,难以可靠地执行具身智能体的长链推理任务;同时,并行解码机制使得输出具有更高的不确定性,这对于精确性要求极高的工具调用任务造成了重大挑战。

-
论文标题:The Bitter Lesson of Diffusion Language Models for Agentic Workflows: AComprehensive Reality Check
-
论文地址: https://arxiv.org/pdf/2601.12979
-
项目地址: https://coldmist-lu.github.io/DiffuAgent/
-
代码地址: https://github.com/Coldmist-Lu/DiffuAgent/
一、为何失败?扩散模型
难以完成智能体任务的三大原因
-
具身智能任务:因果推理能力不足,陷入重复循环
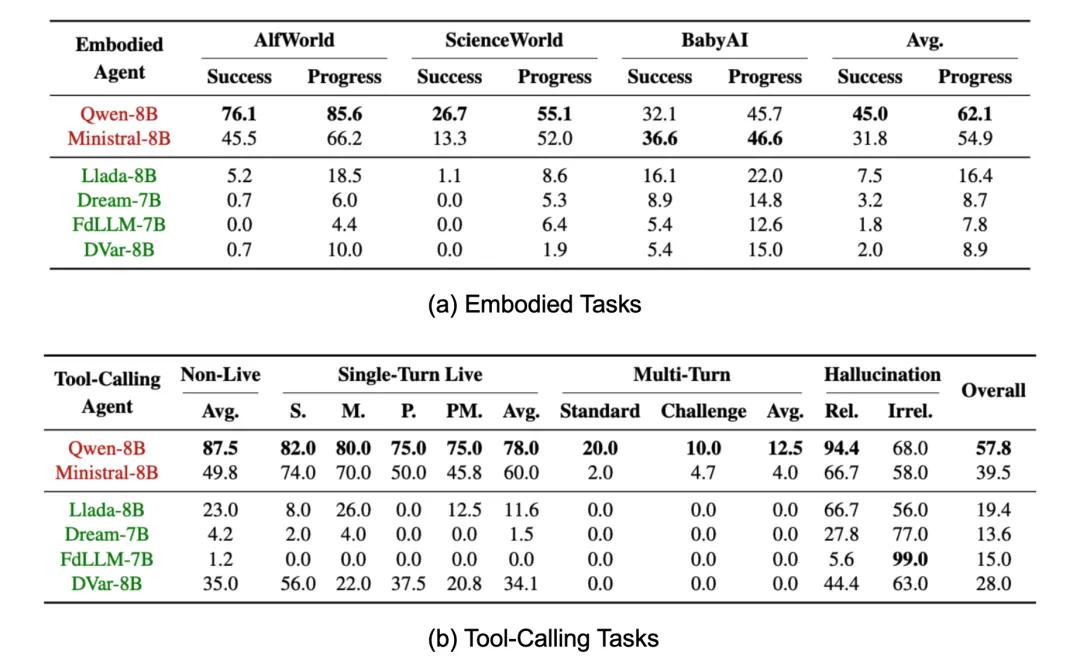
研究基于 AgentBoard 中的三个典型具身智能任务(AlfWorld、ScienceWorld 和 BabyAI)测试了模型的长链规划推理能力。结果显示,扩散语言模型的成功率(Success Rate)和平均任务进度(Progress Rate)均显著低于自回归模型,在部分任务甚至无法产生任何正确样例。
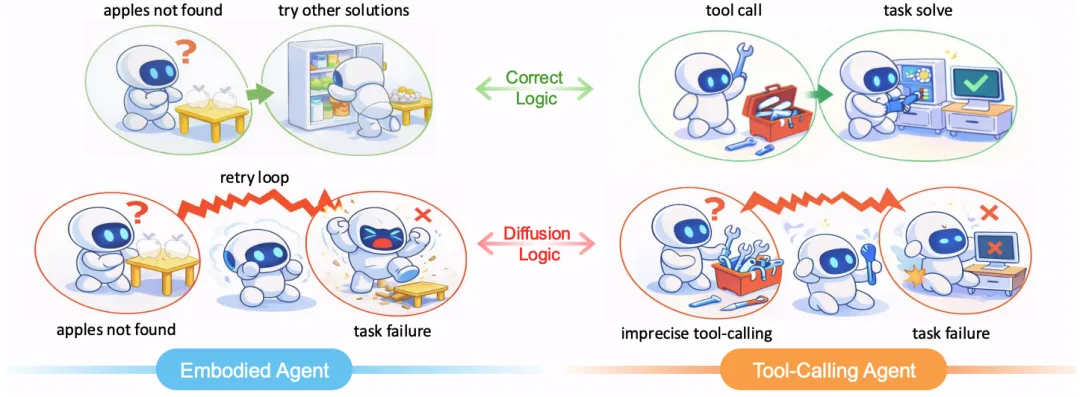
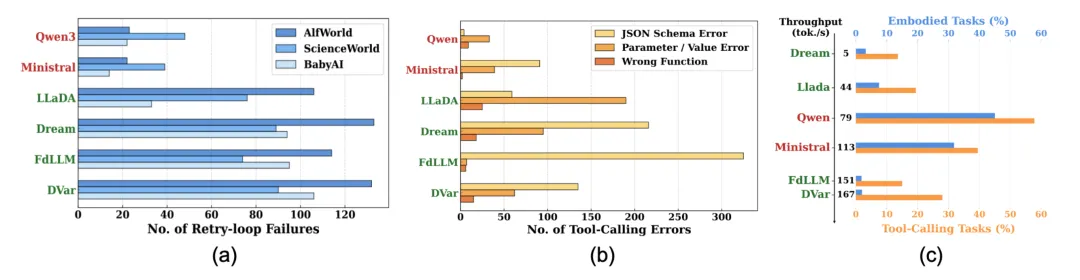
深入分析发现,扩散模型难以进行因果性的推理和实时反思,频繁陷入重复性操作循环(retry loop,见下图 a),而自回归语言模型则极少出现此类问题。
-
工具调用任务:格式输出混乱,多轮调用几乎失效
研究采用伯克利函数调用基准(BFCL v3)进行评估,发现扩散语言模型在单轮与多轮工具调用场景中均落后于自回归模型。尤其在具有挑战性的多轮任务中,扩散模型几乎无法成功完成一次完整调用工作流。
进一步分析表明,扩散语言模型更容易产生格式不规范、语义模糊的调用输出(见下图 b),在要求严格的结构化输出场景下表现尤为突出。
-
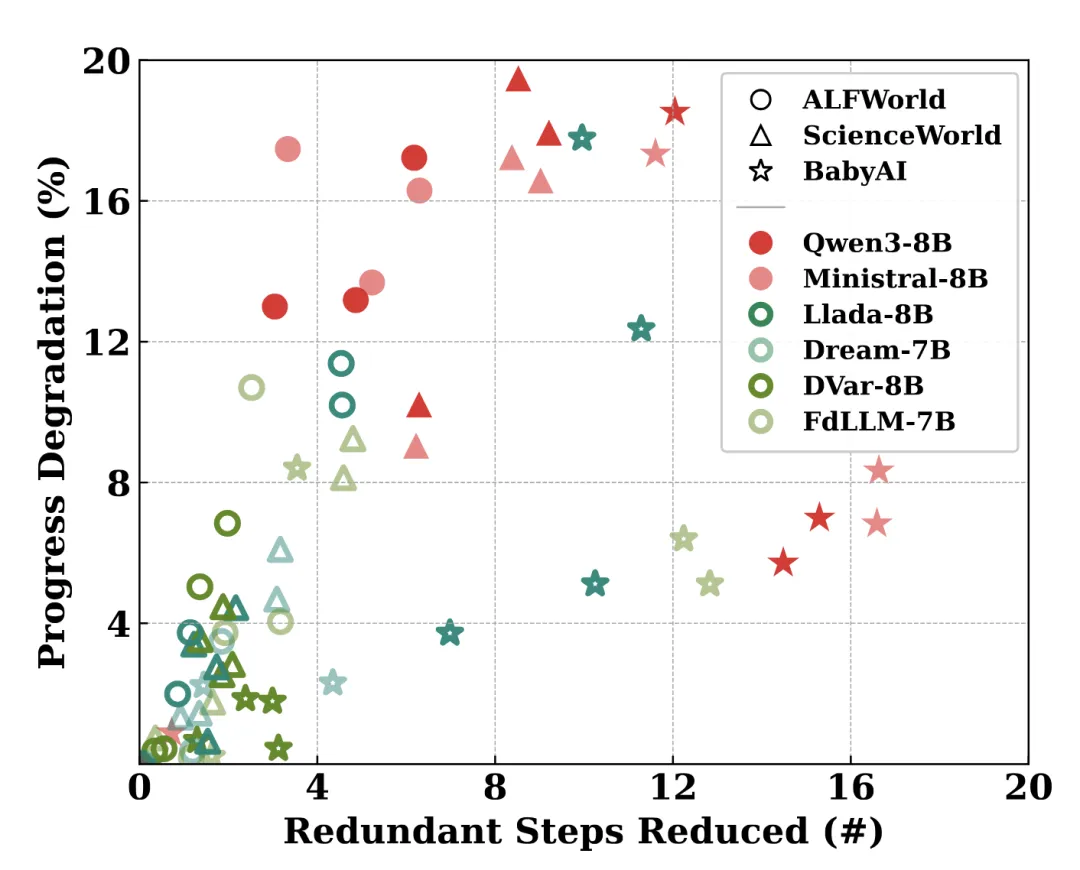
效率与能力的权衡:并行解码的隐性代价
尽管扩散语言模型以高吞吐量为卖点,但研究发现,更高的生成效率并不等同于更强的智能体能力(如下图 c)。相反,并行解码机制会削弱扩散语言模型的因果推理能力,并降低其在精确格式化输出方面的表现。
二、还有救吗?多智能体
评估框架 DiffuAgent 探寻真实潜力
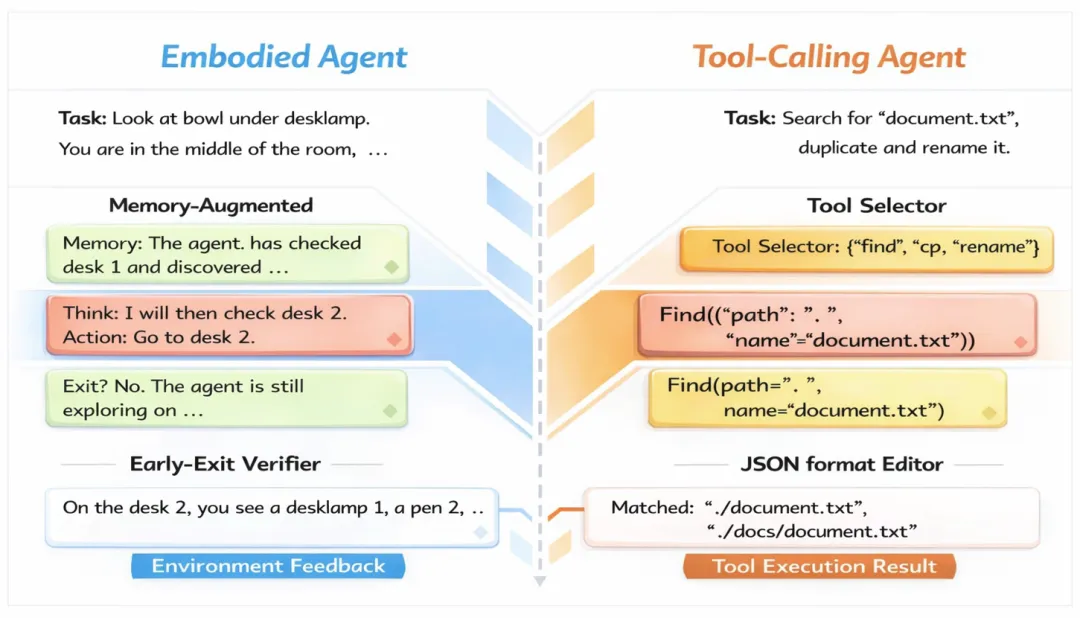
由于扩散语言模型直接执行智能体工作流时会产生大量的失败案例,这对深入分析其能力带来了困难。为了探明扩散语言模型作为智能体的真实潜力,研究团队提出了一个多智能体评测框架 DiffuAgent,将复杂的智能体任务按能力维度拆解为多个模块,在智能体执行每个步骤的前后进行针对性评测:
-
具身智能任务的模块化评估包括: 用于定期储存智能体的运行轨迹、提供历史信息的记忆模块;以及用于检测模型是否能主动识别当前轨迹中的问题,并及时终止无效尝试的自验证模块。
-
工具调用任务的模块化评估包括: 在产生调用指令前,预先筛选出合适的工具候选的工具选择模块;以及对不规范的 JSON 格式进行自动纠正的格式修正模块。
三、能做什么?扩散模型
在各智能体模块中的能力边界
为深入分析扩散语言模型在智能体工作流中的具体表现,研究采用多智能体架构设计:以自回归语言模型作为主控模块,将扩散语言模型分别应用于不同的辅助模块,从而评估其对智能体整体性能的影响。
记忆模块:表现相当甚至更优
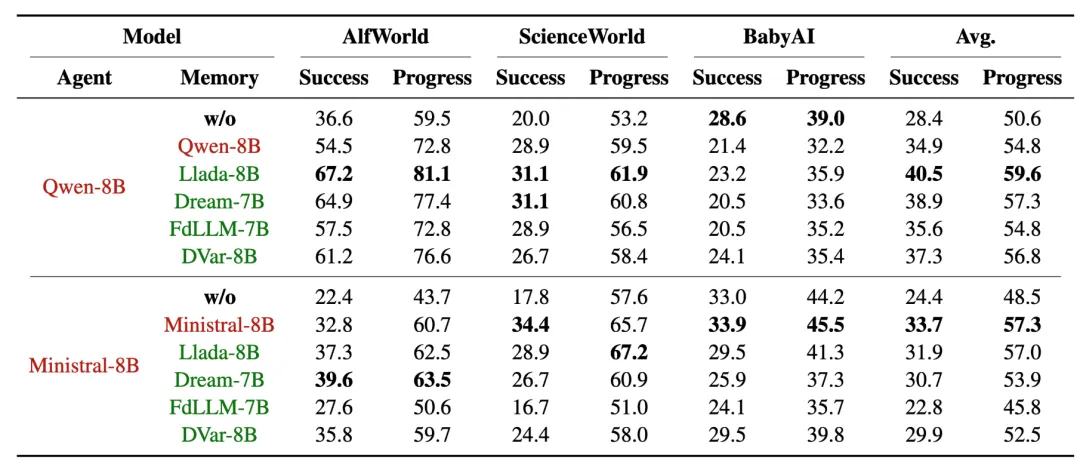
当扩散语言模型作为记忆模块时,其对智能体准确性的影响与自回归模型相当,使用 Llada、Dream 等模型时甚至效果优于自回归模型。
自验证模块:终止决策更加稳健
实验发现,自回归模型作为自验证模块时容易过早终止任务,即在智能体还未完成充分探索时就提前终止;而扩散模型在此场景下的终止判断更加可靠稳定。
工具调用模块:选择能力强,格式修正能力弱
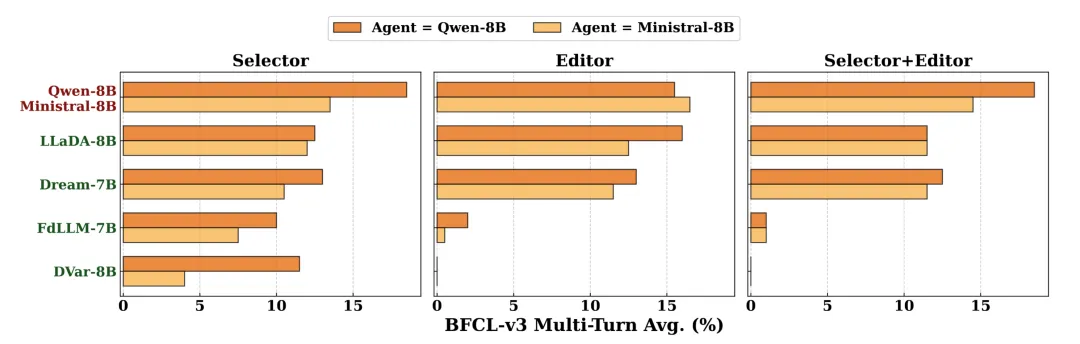
在工具调用任务上,扩散语言模型能有效地完成工具选择;但由于其并行生成机制带来的模糊性,在需要精确格式的工具编辑任务上表现欠佳。
核心发现:并行解码机制带来的权衡与局限
对扩散语言模型在各智能体模块的表现分析,进一步验证了前文揭示的系统性缺陷:并行生成模式虽然导致了因果推理能力的缺失和动态决策能力的不足,但其在推理要求低的文本总结(记忆模块)和状态识别提取(自验证模块)等静态任务上表现出色;虽然难以完成高精确性的格式化输出(格式修正模块),却能有效的进行信息提取(工具选择模块)。这揭示了扩散模型「能力不均衡」的特性:擅长静态处理,弱于动态推理。
四、未来方向:对于
扩散语言模型智能体研究的启示
基于上述系统性评估,本研究从训练、解码和评估三个维度为扩散语言模型的研究者提供以下建议:
-
训练层面:应强化因果推理与解构化能力。在预训练和微调阶段引入具有强因果关系数据,如多步推理任务和轨迹,并大幅增加结构化内容的比重,如 JSON 代码、API 调用等,从源头提升模型对格式规范的理解,并建立对因果依赖关系的敏感性。
-
解码层面:探索自适应的混合生成策略。模型应基于任务特性自适应地选择解码方式,对关键的推理步骤采用自回归解码确保因果连贯,而对于静态任务和需要全局视野的长文本生成,采用并行解码以提升效率;此外可在解码过程中引入格式约束和校正来弥补不确定性的短板。
-
评估层面:建立面向智能体应用的基准体系。当前扩散模型的评估过度依赖 MMLU、GSM8K 等通用基准,这些基准无法反应智能体任务关于因果推理、多轮交互和工具调用等需求。研究者应报告模型在例如 DiffuAgent 智能体评估框架的结果,并建立覆盖真实应用场景的评估体系,避免「跑分高但不实用」的问题。
