阿里开源Qwen 3.5-Plus,性能媲美Gemini 3 Pro,成本降至1/18!底层架构革新,原生多模态训练,Agent能力大幅提升。
原文标题:阿里除夕开源“王炸”千问 3.5-Plus ,性能媲美Gemini 3 Pro、Claude 4.5 Opus,百万 Token 8毛钱
原文作者:AI前线
冷月清谈:
怜星夜思:
2、Qwen 3.5-Plus 在 Agent 智能体方面的能力提升,预示着大模型未来的发展方向吗?你认为“模型不仅会说话,还会做事”的 Agent AI,会在哪些领域率先落地应用?
3、文章提到千问 3.5-Plus 在多语言支持方面扩展至 201 种语言,这一特性对于全球化业务的企业来说意味着什么?你认为大模型在多语言能力上还有哪些挑战?
原文内容

除夕当天,阿里巴巴低调但密集地抛出了一枚重磅“技术炸弹”——全新一代大模型 Qwen 3.5-Plus 正式开源。
GitHub: https://github.com/QwenLM/Qwen3.5
API:https://modelstudio.console.alibabacloud.com/ap-southeast-1/?tab=doc#/doc/?type=model&url=2840914_2&modelId=group-qwen3.5-plus
Hugging Face: https://huggingface.co/collections/Qwen/qwen35
ModelScope: https://modelscope.cn/collections/Qwen/Qwen35
官方给出的定位非常直接:性能对标 Gemini 3 Pro,并在多个关键基准中实现超越;而在成本侧,千问 3.5-Plus 的 API 价格低至每百万 Token 0.8 元人民币,仅为 Gemini 3 Pro 的 1/18。
在当前大模型进入“性能趋同、成本博弈”的阶段,这一组合几乎精准击中了行业的核心痛点。
与前几代千问模型相比,千问 3.5 并非参数规模的线性升级,而是一次 底层模型架构的全面革新。
据官方介绍,千问 3.5-Plus 的总参数规模为 3970 亿,但单次激活参数仅 170 亿。
千问 3 预训练在纯文本 Tokens 上进行,而千问 3.5 则基于视觉和文本混合 token 上预训练,并大幅新增中英文、多语言、STEM 和推理等数据,让张开“眼睛”的大模型学会了更密集的世界知识和推理逻辑,以不到 40% 的参数量获得超万亿的 Qwen3-Max 基座模型的顶尖性能,在推理、编程、Agent 智能体等全方位基准评估中均表现优异。
在这种“以小胜大”的设计下,其综合性能不仅超过了此前万亿参数规模的 Qwen3-Max,显存占用反而降低约 60%,推理效率显著提升,最大推理吞吐量可提升至 19 倍。
这意味着,在相同硬件条件下,开发者可以:
-
跑更大的并发
-
支撑更复杂的 Agent 任务
-
显著压低单位调用成本
在推理密集型应用逐渐成为主流的当下,这种工程取向的优化,比单纯堆参数更具现实意义。
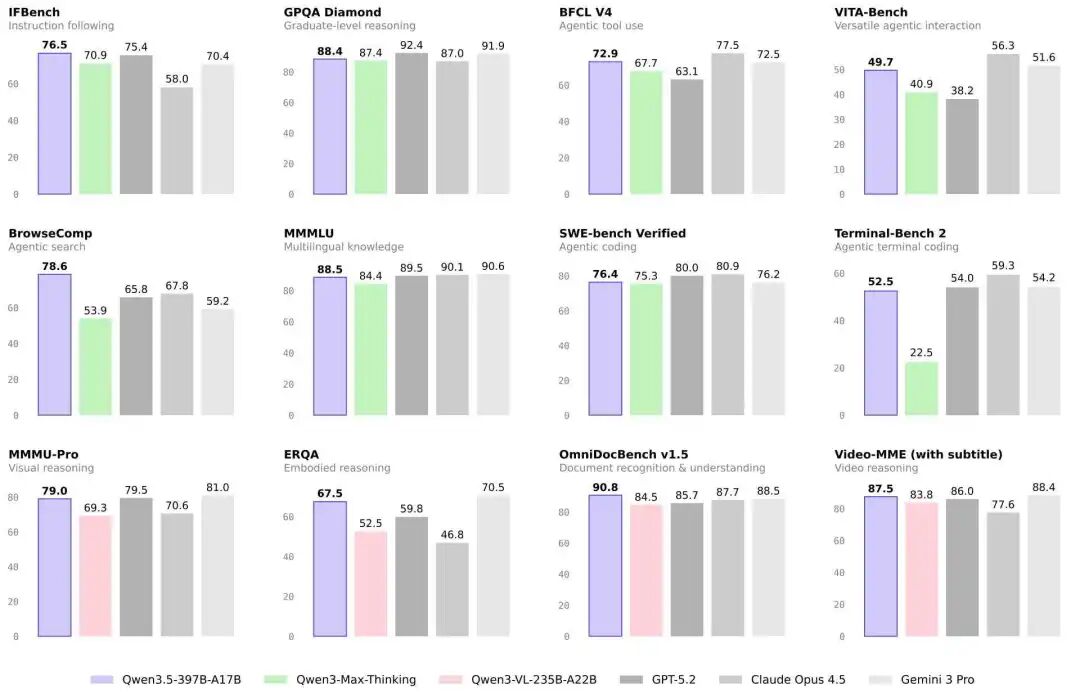
比如,在多个高难度基准中,其成绩已经进入“第一梯队”:
-
MMLU-Pro 知识推理:87.8 分,超越 GPT-5.2
-
GPQA 博士级难题:88.4 分,高于 Claude 4.5
-
IFBench 指令遵循:76.5 分,刷新当前模型纪录
-
通用 Agent 评测(BFCL-V4)、搜索 Agent(BrowseComp):整体表现均超过 Gemini 3 Pro 与 GPT-5.2
图说:阿里开源千问 Qwen3.5-Plus,性能媲美 Gemini 3 Pro
原生多模态训练,也带来千问 3.5 的视觉能力飞跃:在多模态推理(MathVison)、通用视觉问答 VQA(RealWorldQA)、文本识别和文件理解(CC_OCR)、空间智能(RefCOCO-avg)、视频理解(MLVU)等众多权威评测中,千问 3.5 均斩获最佳性能。
在学科解题、任务规划与物理空间推理等任务上,千问 3.5 相比千问专项模型 Qwen3-VL 表现更好,空间定位推理和带图推理能力均大幅增强,推理分析更精细、精准;在视频理解方面,千问 3.5 支持长达 2 小时(1M token 上下文)的视频直接输入,适用于长视频内容分析与摘要生成;同时,千问 3.5 实现了视觉理解与代码能力的原生融合,结合图搜和生图工具,可将手绘界面草图直接转为可用的前端代码,一张截图就能定位并修复 UI 问题,让视觉编程真正成为生产力工具。
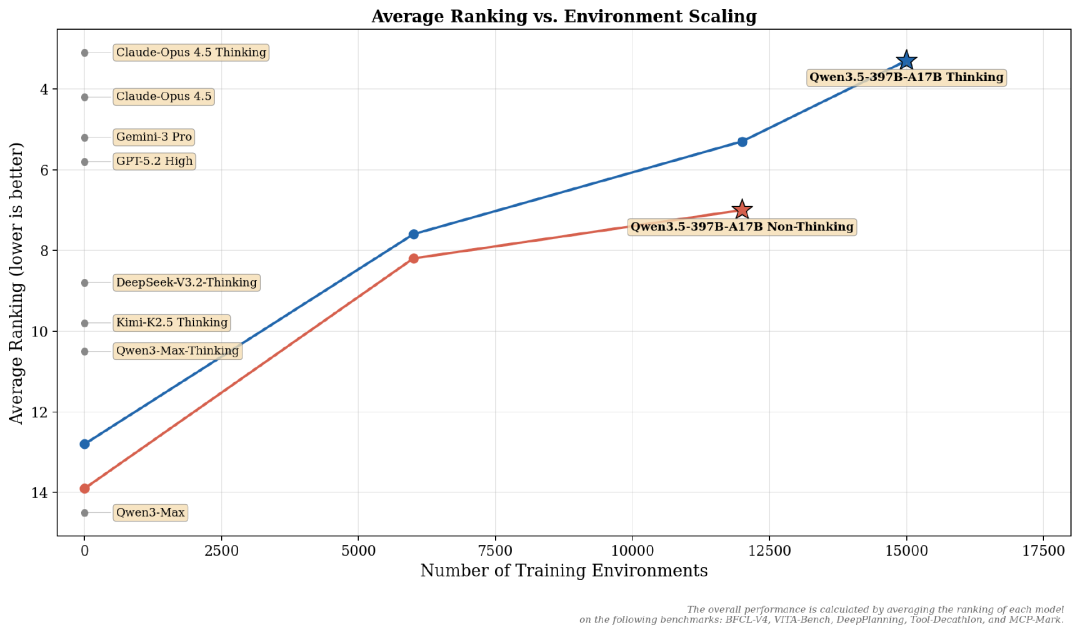
相对于 Qwen3 系列模型,Qwen3.5 的 Post-training 性能提升主要来自于阿里对各类 RL 任务和环境的全面扩展。研发团队更加强调 RL 环境的难度与可泛化性,而非针对特定指标或狭隘类别的 query 进行优化。
下图展示了在通用 Agent 能力上,模型效果随 RL Environment scaling 带来的增益。整体性能由各模型在以下基准上的平均排名计算得出:BFCL-V4、VITA-Bench、DeepPlanning、Tool-Decathlon 和 MCP-Mark。
千问 3.5 性能跃升的背后,是对 Transformer 经典架构的重大创新突破。千问团队自研的门控技术成果,曾斩获全球 AI 顶会 2025 NeurIPS 最佳论文,该前沿技术已融入到千问 3.5 创新的混合架构中去,团队结合线性注意力机制与稀疏混合专家 MoE 模型架构,实现了 397B 总参数激活仅 17B 的极致模型效率;
同时,千问 3.5 通过训练稳定优化以及多 token 预测等系列技术,Qwen3.5 性能与 Qwen3-Max 模型持平,并进一步提升了推理效率:在常用的 32K 上下文场景中,千问 3.5 推理吞吐量可提升 8.6 倍;在 256K 超长上下文情况下,Qwen3.5 推理吞吐量最大提升至 19 倍,推理效率大幅提升。
具体而言,千问团队做了什么?
据千问技术博客介绍,他们在预训练上下了一番功夫。Qwen3.5 在能力、效率与通用性三个维度上推进预训练:
能力(Power):在更大规模的视觉 - 文本语料上训练,并加强中英文、多语言、STEM 与推理数据,采用更严格的过滤,实现跨代持平:Qwen3.5-397B-A17B 与参数量超过 1T 的 Qwen3-Max-Base 表现相当。
效率(Efficiency):基于 Qwen3-Next 架构——更高稀疏度的 MoE、Gated DeltaNet + Gated Attention 混合注意力、稳定性优化与多 token 预测。在 32k/256k 上下文长度下,Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-Max 的 8.6 倍 /19.0 倍,且性能相当。Qwen3.5-397B-A17B 的解码吞吐量分别是 Qwen3-235B-A22B 的 3.5 倍 /7.2 倍。
通用性(Versatility):通过早期文本 - 视觉融合与扩展的视觉 /STEM/ 视频数据实现原生多模态,在相近规模下优于 Qwen3-VL。多语言覆盖从 119 增至 201 种语言 / 方言;25 万词表(vs. 15 万)在多数语言上带来约 10–60% 的编码 / 解码效率提升。
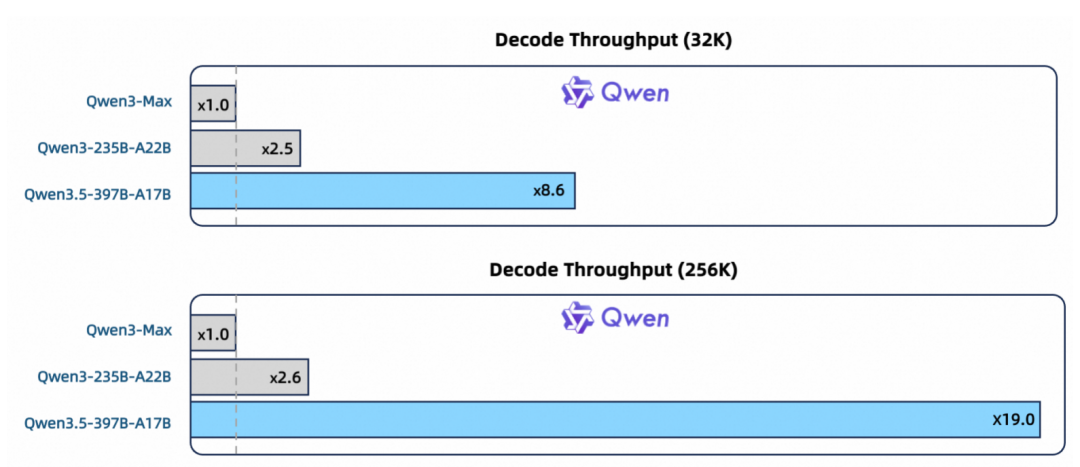
图说:千问 3.5 推理效率大幅提升,最大吞吐量提升至 19 倍
千问 3.5 的原生多模态训练工作,是在阿里云的 AI 基础设施上完成的。围绕多模态训练过程中常见的算力与效率瓶颈,千问团队在底层训练技术上进行了多项改进,使模型在文本、图像、视频等混合数据上的训练吞吐量,接近纯文本基座模型的训练水平,二者几乎持平。这在一定程度上降低了原生多模态模型在工程实现层面的复杂度与门槛。
在数值精度设计上,千问 3.5 采用了结合 FP8 与 FP32 的混合精度策略。在训练规模扩展至数十万亿 Token 的情况下,该策略使激活内存占用减少约 50%,同时训练速度提升约 10%。相关优化在控制训练稳定性的同时,降低了整体算力消耗,也带来了模型训练成本的进一步下降。
在模型能力层面,依托视觉理解能力的增强,千问 3.5 的应用场景开始从 Agent 框架层延伸至更具体的 Agent 应用。模型具备在手机和电脑环境中执行操作的能力,能够完成多种日常任务。在移动端,千问 3.5 支持更多主流应用及相关指令;在 PC 端,则可以处理包含多步骤的复杂操作,例如跨应用的数据整理和自动化流程执行等,从而提升整体操作效率。
围绕 Agent 能力的训练与扩展,千问团队同时构建了一套可扩展的异步强化学习框架。该框架在端到端训练过程中可实现约 3 至 5 倍的加速,并支持插件式智能体 Agent 的扩展,规模可提升至百万级。
在开源生态方面,自 2023 年启动开源以来,阿里已累计开源 400 余个千问模型,覆盖不同参数规模及多种模态类型。根据官方披露的数据,千问模型的全球累计下载量已超过 10 亿次,单月下载量超过 DeepSeek、Meta、OpenAI、智谱、Kimi、MiniMax 等多个模型的合计水平。开发者基于千问模型构建的衍生模型数量已超过 20 万。
针对不同国家和地区开发者及企业的使用需求,千问大模型体系仍在持续扩展中。以千问 3.5 为例,其语言支持范围已扩展至 201 种语言,词表规模由 15 万增加至 25 万,在部分小语种场景下,编码效率最高可提升约 60%。
据悉,千问 APP、PC 端已第一时间接入 Qwen 3.5-Plus 模型。开发者可在魔搭社区和 HuggingFace 下载新模型,或通过阿里云百炼直接获取 API 服务。阿里很快将继续开源不同尺寸、不同功能的千问 3.5 系列模型。性能更强的旗舰模型 Qwen3.5-Max 不久也将发布。
围绕 Qwen 3.5 Plus 的发布,海外技术社区也迅速出现了多种不同侧重的讨论视角。
在 x 平台,有用户首先注意到模型在界面与交互层面的能力。一位网友评价称,Qwen 3.5 Plus 展现出“非常出色的 UI 设计能力”,在生成界面布局、组件结构以及交互逻辑时,整体完成度明显高于以往的大模型表现。这类能力被认为对低代码开发、应用原型设计等场景具有直接价值。
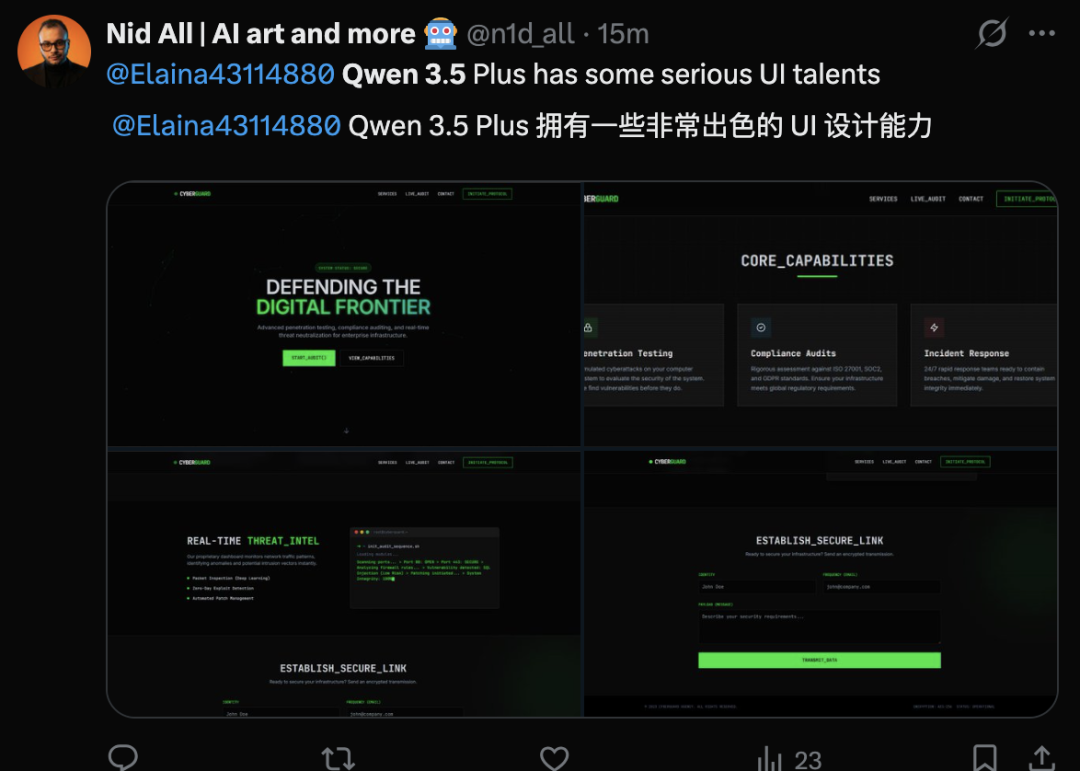
也有评论将关注点放在多语言覆盖能力上。
针对 Qwen 3.5 扩展支持 201 种语言,一位用户直言“太棒了”,并特别提到,模型已经能够清晰、自然地使用自己的母语进行表达。这位用户同时表示,十分期待后续 A17b 版本在多语言和推理能力上的进一步表现。这类反馈反映出,超大规模语言覆盖正在从“参数指标”转变为真实可感知的使用体验。

此外,还有网友从更宏观的行业趋势出发,对这次发布进行了解读。在相关评论中提到,“智能体人工智能(Agent AI)”的竞争正在明显升温。
该用户指出,阿里巴巴 发布 Qwen 3.5 的目标并不止于提升对话能力,而是让模型能够在真实应用中采取行动,包括在应用程序中执行任务、完成操作流程等。在其看来,“模型不仅会说话,还会做事”正在成为新的竞争方向,而“智能体”很可能成为 2026 年最重要的 AI 主题之一。

整体来看,这些来自社区的反馈从 UI 生成、多语言体验到 Agent 化趋势,勾勒出 Qwen 3.5 Plus 在开发者与技术用户眼中的几个关键定位:不仅是性能升级的模型版本,也被视为迈向“可执行智能体”的重要一步。
参考链接:
https://x.com/bariserdem81/status/2023331882893443347
https://qwen.ai/blog?id=qwen3.5

