极佳视界发布GigaBrain-0.5M*,基于世界模型的新一代具身智能,实现机器人长时间稳定运行,并在多项任务中取得突破,具有强大的泛化能力。
原文标题:世界模型原生新一代范式!极佳视界斩获全球第一后,GigaBrain-0.5M*再进化
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 GigaBrain-0.5M* 使用 GigaWorld 合成数据来突破真实数据采集的瓶颈,这种方法有哪些优势和局限性?在哪些场景下合成数据可能无法替代真实数据?
3、GigaBrain-0.5M* 在折纸盒、冲煮咖啡等任务中表现出色,这些技能迁移到其他领域的机器人应用,例如医疗、农业等,还面临哪些挑战?需要克服哪些技术难题?
原文内容
具身世界模型新一代原生范式重磅登场!继具身基础模型 GigaBrain-0.1 斩获 RoboChallenge 全球第一后,性能更强大的 GigaBrain-0.5M* 又来了。
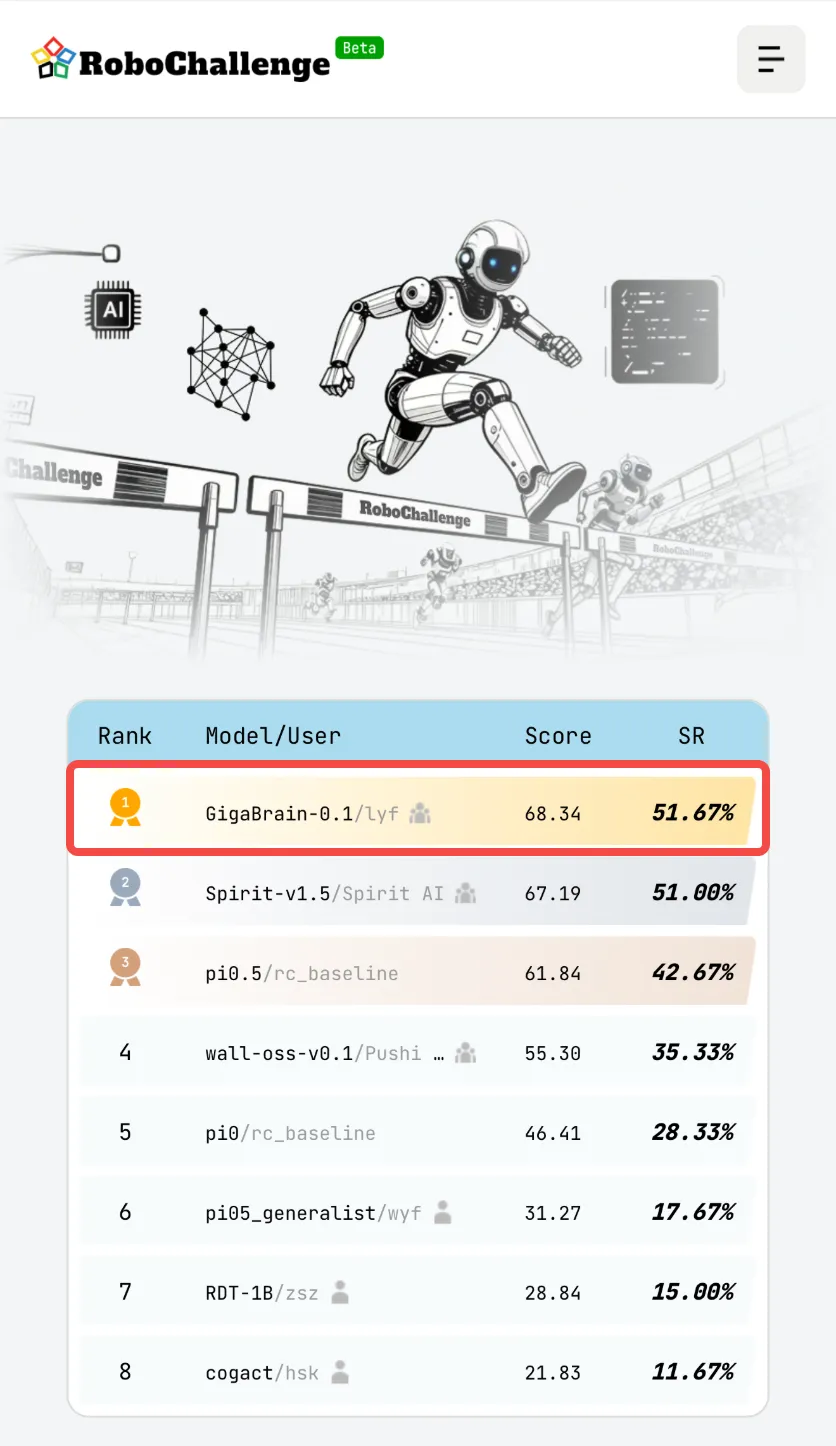
作为依托世界模型实现自我进化的 VLA 大模型,GigaBrain-0.5M* 在家庭叠衣、服务冲煮咖啡、工业折纸盒等多个真实机器人任务中,均实现数小时零失误、持续稳定运转。
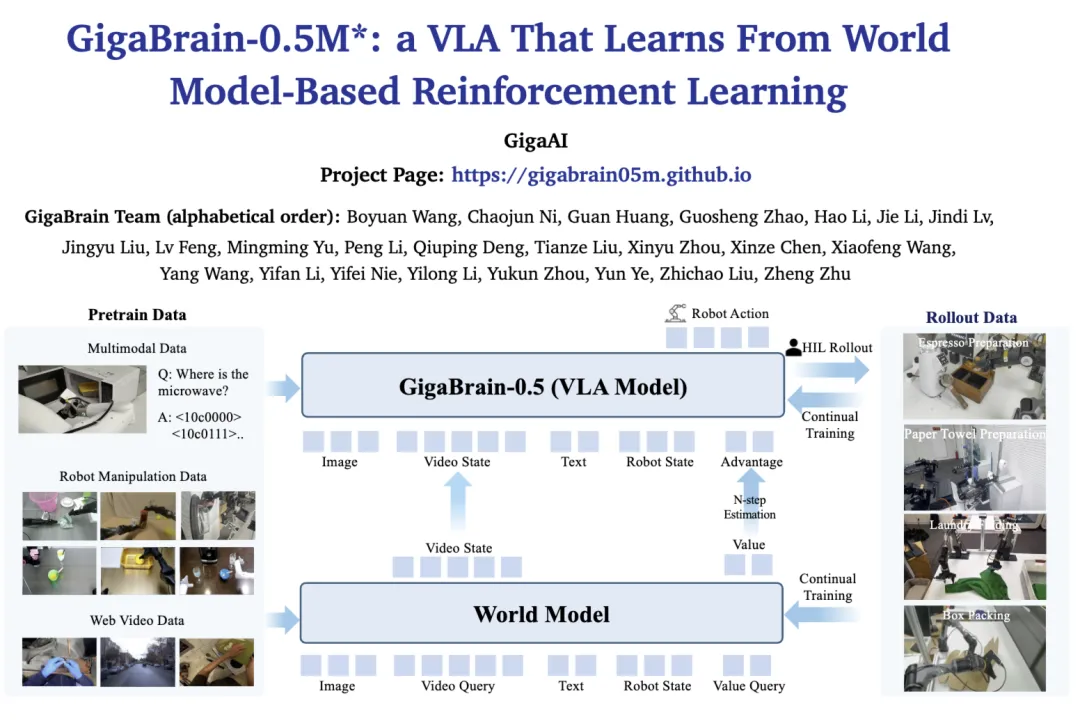
GigaBrain-0.5M* 作为一款基于世界模型条件驱动(World Model-Conditioned)的 VLA 大模型,以世界模型对未来状态与价值的预测结果作为条件输入,可显著提升模型在长时程任务中的鲁棒性。
在此基础上,GigaBrain-0.5M* 创新引入人在回路(Human-in-the-Loop)持续学习机制,系统依托经人工筛选与校正的模型推演轨迹开展迭代训练,基于真实环境交互反馈持续优化决策策略,最终实现「行动 — 反思 — 进化」的闭环式持续学习与自主迭代升级。
-
论文链接:https://arxiv.org/pdf/2602.12099
-
项目链接:https://gigabrain05m.github.io/
01
基于世界模型的强化学习训练范式
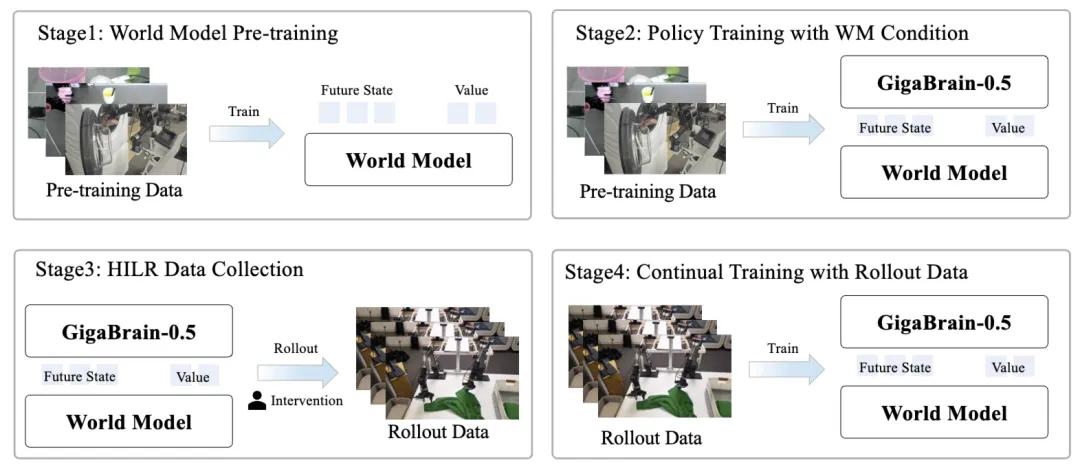
在 GigaBrain-0.5M* 的研发中,极佳视界提出基于世界模型的强化学习范式,并采用迭代式四阶段闭环训练流程:
-
基于大规模机器人操作数据完成世界模型预训练,实现对未来状态及对应价值的精准预测;
-
以世界模型输出的未来状态预测与价值评估为条件,对策略网络进行微调,以指引动作决策;
-
将条件化策略部署至真实物理环境,依托人在环干预机制,采集模型自主推演轨迹数据;
-
利用经筛选后的有效轨迹数据集,联合优化世界模型与决策策略,实现模型持续学习与自主进化。
02
数小时连续零失误执行
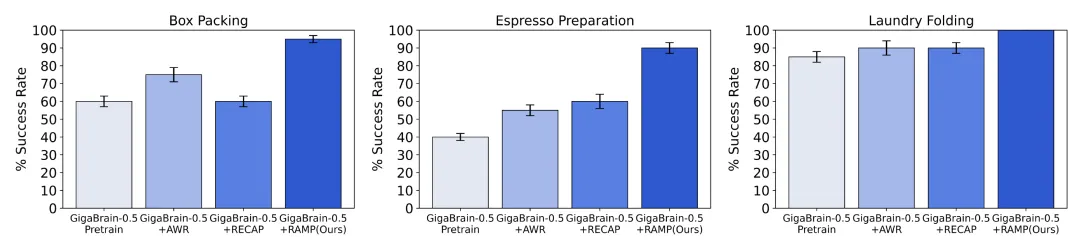
在与 AWR、RECAP 等主流模仿学习与强化学习基线方法的系统对比中,GigaBrain-0.5M* 展现出显著优势,在相同任务设定下,相较于由 π*0.6 由所提出的 RECAP 基线,任务成功率提升近 30%,并实现了稳定可靠的模型效果。
尤其在高难度长时程任务中,面对折纸盒、咖啡制备、衣物折叠等包含多阶段操作、精细感知与持续决策的复杂场景,GigaBrain‑0.5M* 均实现接近 100% 的任务成功率,并可稳定复现成功执行轨迹,充分彰显出卓越的策略鲁棒性。
03
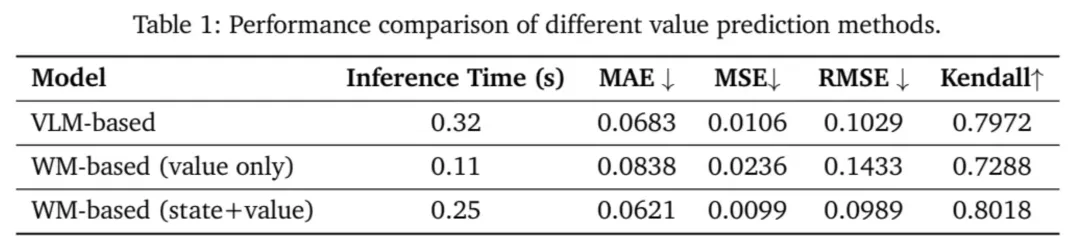
高效且准确的价值预测
实验结果表明,基于世界模型的价值预测方案在执行效率与预测精度上,均优于 π*0.6 所提出的 VLM 方案。该方案的核心优势源自对未来状态的显式建模与世界模型单步降噪机制,可为价值函数提供关键的时序上下文支撑,让价值估计实现更高效、更精准、更稳定的输出。
以叠衣服任务为例:任务初期,机械臂反复调整衣物姿态时,预测价值呈现合理波动;当衣物摆正、进入稳定叠放阶段,价值曲线稳步上升;若中途出现干扰物,价值骤降以反映任务受阻;待干扰物被移除后,价值迅速恢复增长趋势。这种与任务物理进程高度对齐的价值演化,正是世界模型提供「认知先验」的直接体现。
04
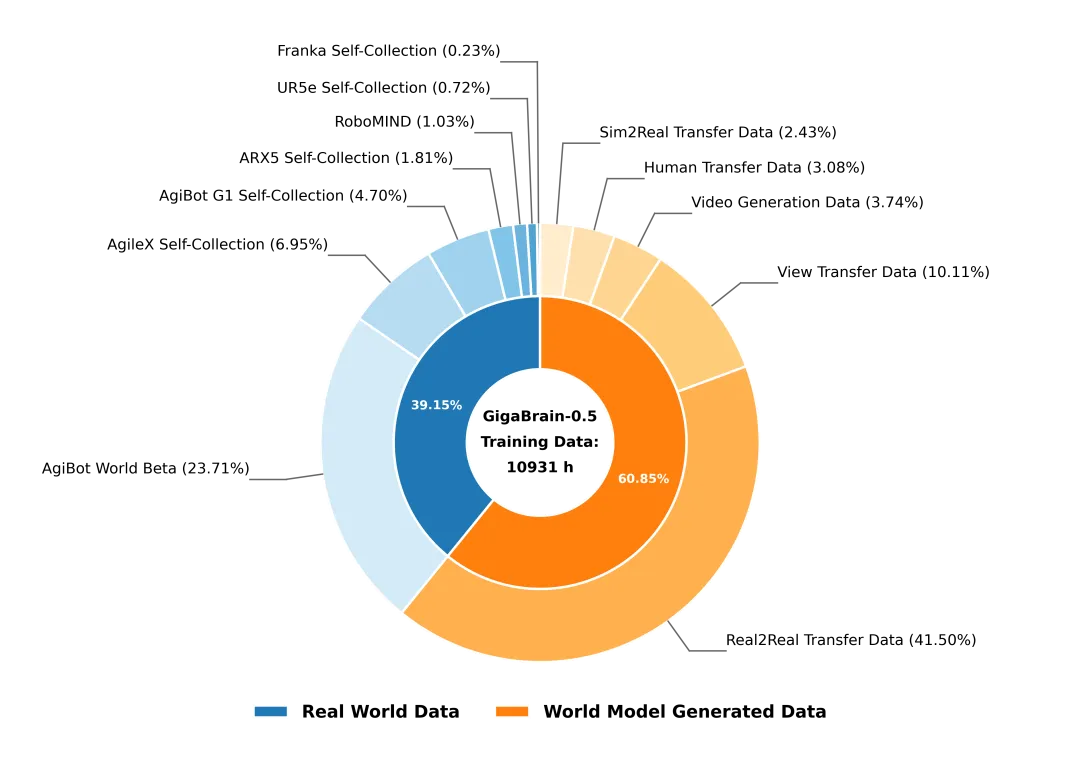
上万小时的训练数据
GigaBrain-0.5M* 的基座模型 GigaBrain-0.5 基于总计 10,931 小时的多样化机器人操作数据进行预训练,其中 61%(6,653 小时)由自研具身世界模型 GigaWorld 高保真合成,覆盖纹理迁移、视角变换、人手到机械臂映射等丰富场景;剩余 39%(4,278 小时)源自真实机器人采集,确保策略在物理世界中的可执行性。
海量数据的引入显著拓展了模型的任务覆盖广度与策略鲁棒性,使其在面对复杂、长时程操作任务时具备更强的泛化能力;而 GigaWorld 生成的合成数据则有效突破了真实采集的长尾瓶颈。通过可控地生成新纹理、新物体位姿与新观测视角下的训练样本,增强了模型在分布外场景中的适应性,为具身智能走向开放世界奠定了数据基石。
公司及团队介绍
极佳视界是一家具身智能和通用机器人公司,围绕「基模 - 本体 - 场景」三位一体,为工业、商业、家庭等场景提供软硬一体的具身智能机器人解决方案,推动通用机器人服务千行百业、走进千家万户。
公司核心团队包括清华、北大、中科院、中科大、WashU、CMU 等全球知名院校顶尖研究人员,以及来自微软、三星、地平线、百度、博世等全球知名企业高管,核心团队在物理 AI 方向兼具业内领先的研究能力和大规模的产业落地经验。
极佳视界是国内第一家布局世界模型的科技公司,以世界模型平台 GigaWorld、通用具身大脑 GigaBrain、原生本体 Maker 构建闭环生态,致力实现 10-100 倍以上的数据、训练、测试全链路效率提升,推动通用具身智能机器人、通用自动驾驶等物理 AGI 大规模爆发。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com