小红书开源图像编辑模型FireRed-Image-Edit,在图像编辑领域取得SOTA!具备强大指令理解、文字编辑和创意生成能力,代码、报告、Demo均已开源。
原文标题:这个春节P图不求人!小红书开源图像编辑新SOTA
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到FireRed-Image-Edit在多参考图生成方面有能力,那么在实际应用中,这种能力可以用来做什么有趣或者有用的事情? 你能想到哪些创新的应用场景?
3、小红书开源FireRed-Image-Edit,你觉得对整个AI图像编辑领域会带来哪些影响?对于普通用户来说,又意味着什么?
原文内容

本文经AI新媒体量子位(公众号ID:qbitai )授权转载,转载请联系出处本文约3000字,建议阅读5分钟AI生图领域,又出了个“狠角色”。
小红书基础模型FireRed-Image-Edit正式亮相。
看似“低调”,实则战绩惊人——其在处理复杂编辑指令、风格化转换,及高精度文字编辑等多个核心指标上,展现出超强实力。
对比结果显示,FireRed-Image-Edit凭借更精准的理解力、更强的ID保持度及高效的架构,在多项权威测试中脱颖而出,在ImgEdit、GEdit等多个榜单中取得了SOTA,达到业界领先水平。
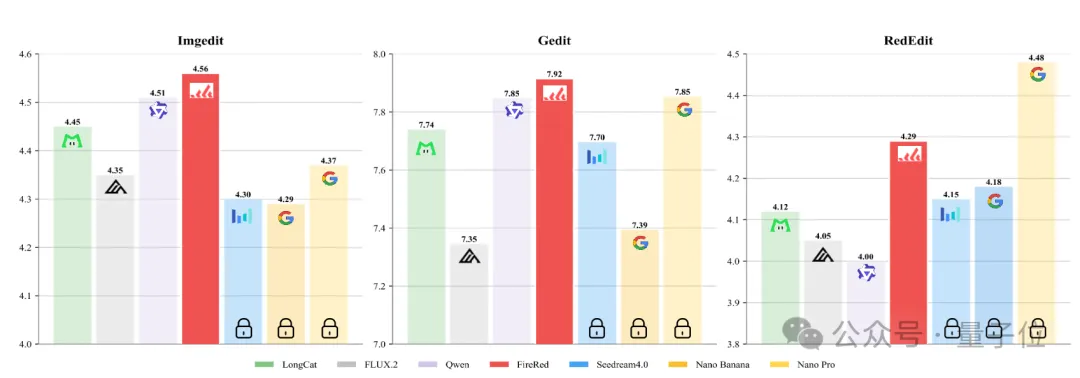
这种高效架构背后的技术底座,来自小红书Super Intelligence Team在图像生成与编辑领域的一次重要探索。
划重点!目前该项目代码、技术报告、demo网页已开源,模型权重也即将在未来几天开源。
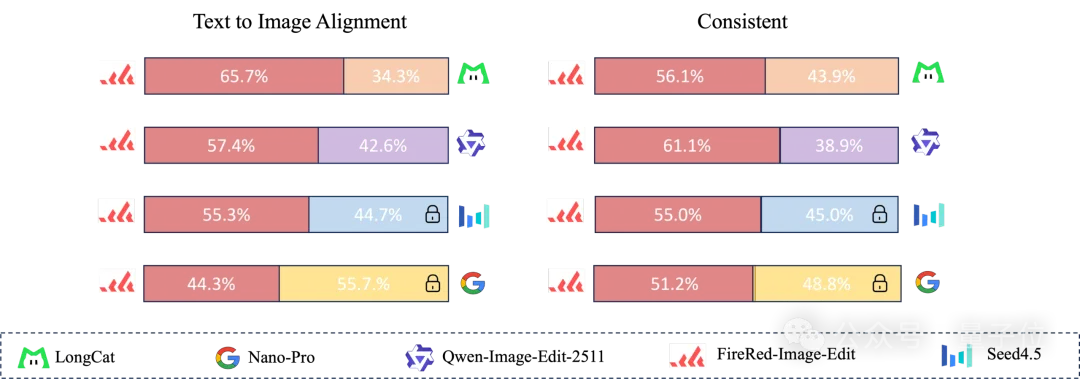
硬核评测指标与全链路技术底座
FireRed-Image-Edit之所以能被称为“狠角色”,不仅在于榜单上的惊艳表现,更源于小红书团队为其量身定制的一套“高难度考卷”与“进阶版练功房”。
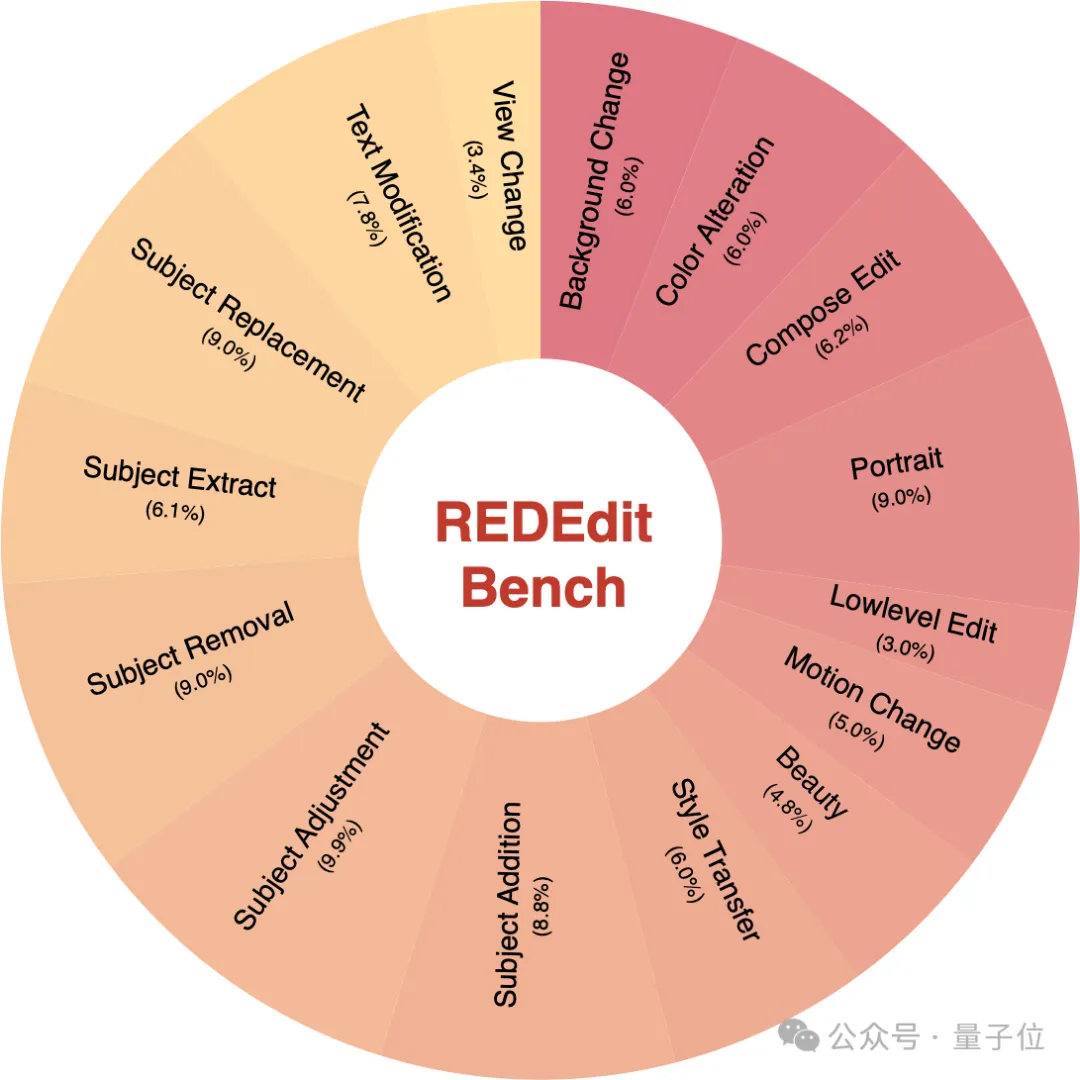
1、重新定义标准:RedEdit Bench
在AI生图领域,现有的基准测试往往难以覆盖用户真实的复杂需求。为此,团队推出了RedEdit Bench这一深度评测方案。
-
全场景覆盖:包含15个子任务。除了常规的画面增删改外,该评测集还前瞻性地纳入了人像美化、低画质增强等高频实战场景。
-
真实严苛:对比实验表明,相比ImgEdit和GEdit,该Bench对编辑模型通用能力的评估精度更高。
该Bench随后会开源,以期为开源社区对图像编辑模型的评估建立新维度的标准。
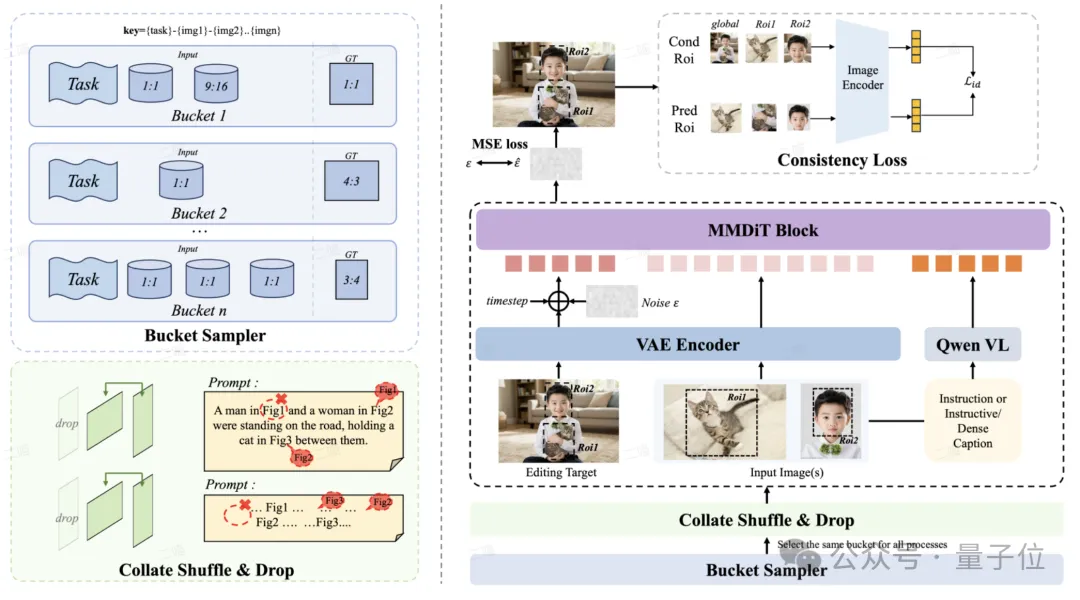
2、核心战力来源:数据构造与三阶段训练
有了严苛的考卷,如何“培养”出高分考生?
FireRed-Image-Edit依靠的是一套极具效率的数据引擎与训练逻辑——
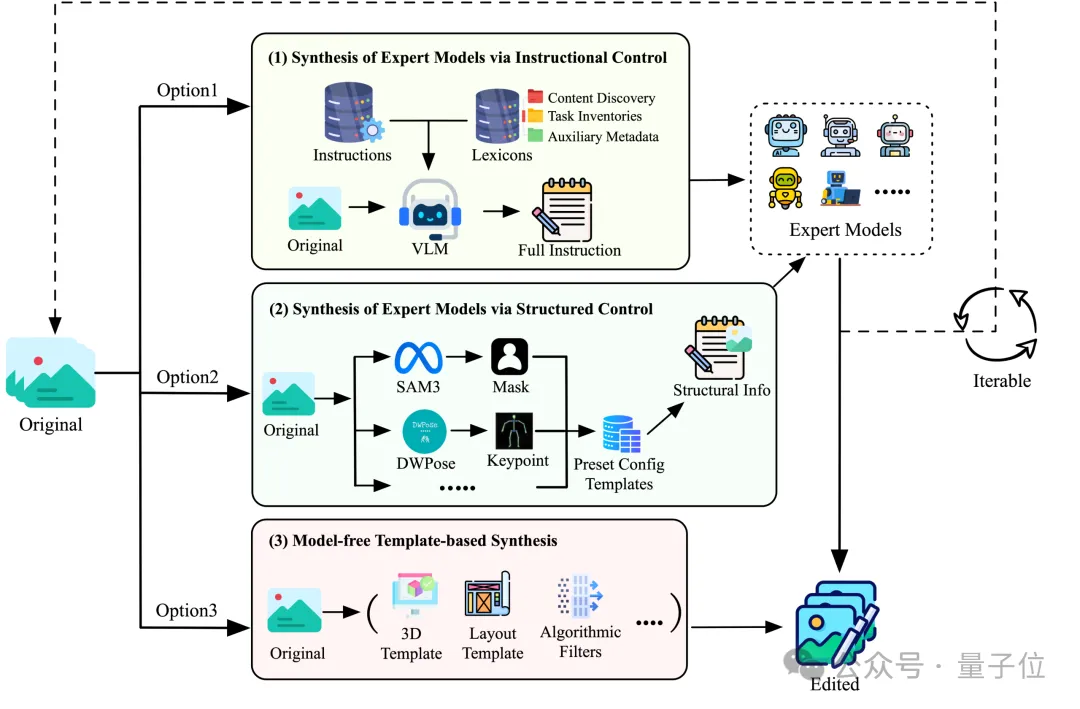
首先来看数据引擎方面,FireRed-Image-Edit构建了一套图像编辑数据生产引擎,从“快速、可控、精准”出发,将复杂编辑需求拆解为可组合的子任务,并通过三条路径规模化产出训练对:
-
指令控制的专家模型合成;
-
结构化控制(如分割/关键点/深度等)的专家模型合成;
-
模型无关的模板化合成(如3D/布局/文字)。
针对长尾编辑任务样本稀缺问题,采用“检查—补齐”的定向补数流程,由引擎快速生成针对性数据,并配合三层级去重、十余种质量清洗算子与严格一致性守门员,确保数据的指令遵循、视觉自然度与内容一致性。
而在模型训练方面,当前模型框架参考主流编辑模型框架,模型通过三阶段训练来完成能力的进阶。
-
预训练阶段:通过多条件感知桶采样来平衡不同的编辑任务,并通过随机动态指令来提升模型的指令泛化理解能力,并通过前置的embedding抽取来提升训练效率;
-
微调阶段:通过高质量数据的引入,来提升模型表现;
-
强化学习阶段:通过非对称梯度优化来强化正样本反馈,基于OCR奖励的diffusionNFT来提升文字编辑准确性。
模型核心能力展示
FireRed-Image-Edit的强大,源于对“编辑”二字的深度理解。
并非简单重绘,而是实现精准控制,其核心能力提升如下。
1、指令遵循一致性
指的是模型引入随机指令对齐的机制,通过随机打乱和动态重组prompt,来使模型能真正理解语义与图像的对应关系,而非死记硬背。
请修正图像中的错误。
示例1:


示例2:


FireRed-Image-Edit创新性地提出了Layout-Aware OCR-based Reward。
在强化学习阶段,团队不仅惩罚错别字,还惩罚字符的错位、大小异常和布局崩坏。
这使得模型在进行海报修改、文字替换时,能更准确地进行编辑并保持原始文字风格。
示例1:
将海报上右下角的文字“ programme”修改为“program ongoing”,保持字体和风格一致。


示例2:
用参考图的玩偶作为画面主角,衣服上面印着“FireRed-Image-Edit”字样,站在童话感花园草地中,周围有精致小花和柔和建筑背景,整体风格温暖梦幻,超清细节,商业级摄影质感。 小红薯正对镜头,自信可爱地站立,身后是一块黑板,用白色粉笔清晰写着: “FireRed-Image-Edit三大绝活:文字艺术家:中英文字体排版专业稳定,视觉风格统一 时光修复师:老照片修复细节丰富,呈现自然真实造型设计师:智能换装精准自然,多风格服饰一键切换”,文字为白色粉笔手写体。 画面光线柔和自然光,浅景深,背景轻微虚化,色彩明亮饱满,高清8K,真实摄影风格,细节锐利,无噪点,无畸变。


3、创意与多图生成
同时依赖于强大的模型架构能力,FireRed-Image-Edit支持了创造力场景生成和多参考图生成的能力,支持风格迁移或多图融合。
示例1:
模特穿上图1服饰,版型宽松。搭配黑色、材质为氨纶、纯色、紧身、长度至大腿中部的骑行短裤,再搭配金色圆环耳环。



示例2:
一瓶香水放居中,香水瓶放在水面上,透明方形瓶身搭配金色金属瓶盖,极简而现代。晶莹的水花如爆炸般环绕瓶身绽放开,无数水滴在空中定格,折射出梦幻的光彩。底部水波涟漪层层扩散,与飞溅的水花形成动静交织的视觉张力。清凉活力与高端奢华并存,仿佛将夏日清泉的瞬息灵动永久封存。透过瓶身能看到香水背后的说明书。


示例3:
将这张图变成游戏CG风格,极具艺术感,震撼人心,超高清。落叶飞溅,前景落叶虚化,动态模糊,背景动态虚化,阳光灿烂,蓝天白云,光影交错,仰拍特写镜头,突出速度感和视觉冲击力,强透视。


示例4:
将这张图变成游戏CG风格,极具艺术感,震撼人心。


示例5:
设计一张A6折叠卡:打开时显示图片中的小屋。


示例6:
画质修复,细节重现:除了通用编辑,实际应用中,用户经常面临照片模糊、低分辨率、曝光不足或画质受损的问题。FireRed-Image-Edit将超分、去模糊、去噪及光影增强等底层视觉任务统一纳入了指令微调的范畴。让用户可以一键画质调整。修复并上色这张老照片,使其看起来像是用现代相机拍摄的。
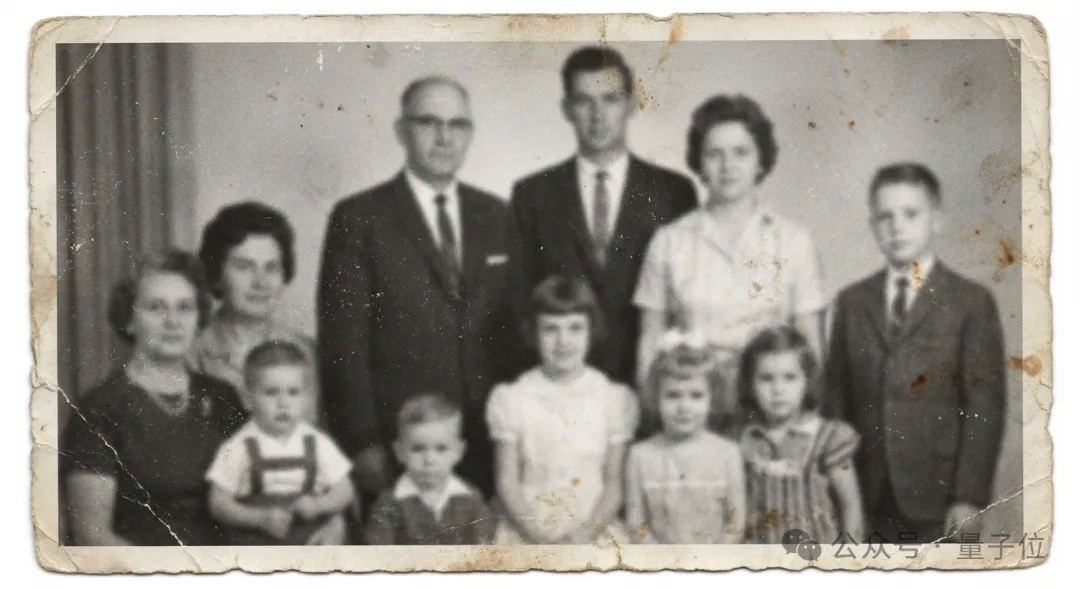

示例7:
将这张模糊的图像增强清晰度,使其极为清晰且高质量。


通过开源FireRed-Image-Edit,小红书希望为社区提供一个高效、可控、高质量的基座。
后续将会进一步提升基础模型在人像美化、一致性、文字上的编辑能力,并将在未来几个月内持续开源更新版本和文生图基座模型。
欢迎大家下载体验,在GitHub上点亮Star!
GitHub:
https://github.com/FireRedTeam/FireRed-Image-Edit
技术报告:
https://github.com/FireRedTeam/FireRed-Image-Edit/blob/main/assets/FireRed_Image_Edit_1_0_Techinical_Report.pdf
体验Demo:
https://huggingface.co/spaces/FireRedTeam/FireRed-Image-Edit-1.0
以下是小红书Super Intelligence的团队介绍:

编辑:文婧
