CineTrans提出了一种基于掩码机制的转场可控多镜头视频生成模型,并开源了代码、模型权重和数据集。
原文标题:ICLR 2026 | CineTrans: 首个转场可控的多镜头视频生成模型,打破闭源技术壁垒
原文作者:机器之心
冷月清谈:
怜星夜思:
2、CineTrans依赖于大规模多镜头数据集Cine250K进行微调,那么数据集的质量和多样性对模型最终的生成效果有多大影响?如果数据集存在偏差,比如过度偏向某种风格或主题,会对生成结果产生什么影响?
3、CineTrans目前主要关注于转场的时间级控制,未来是否有可能加入更多对转场风格的控制,比如指定转场类型(淡入淡出、划像等)或者转场速度?
原文内容

本文一作吴晓雪目前是复旦-上海人工智能实验室的联培博士生,目前的研究方向是可控多镜头生成、长视频生成。
随着视频生成模型的快速发展,其在画面质量、条件控制、美学表现上都已表现出影视级效果。然而,影视级长视频往往并非为单个镜头的无限延续,而是具有转场的多镜头序列(Multi-shot Sequence)。闭源模型 Sora2、Veo3 中多镜头视频已经能够表现出惊艳的效果。
如何使生成的视频带有自然的转场,如何指定转场的位置,如何令多个镜头形成丰富的语义流信号,是视频生成模型在未来所面临的新挑战。
针对这些问题,来自上海人工智能实验室的研究团队提出了一种基于掩码机制的全新方法 CineTrans。
基于对注意力特性的观察,CineTrans 提出块对角掩码的通用机制,使视频生成模型能高效地自动化转场。为了进一步提升转场模型的效果和准确性,作者设计了详细的多镜头视频生产管线,并收集了一个高质量、多镜头数据集 Cine250K,大幅提升多镜头转场视频生成的效果。作为首个时间级可控的自动化转场模型,CineTrans 为这一领域的众多后续方法提供了关键技术。
本文将深入介绍这篇被 ICLR 2026 接收的工作。

-
论文标题: CineTrans: Learning to Generate Videos with Cinematic Transitions via Masked Diffusion Models
-
论文链接: https://arxiv.org/pdf/2508.11484
-
项目链接: https://uknowsth.github.io/CineTrans/
-
代码链接: https://github.com/Vchitect/CineTrans
-
数据集链接:https://huggingface.co/datasets/NumlockUknowSth/Cine250K
来看看 CineTrans 的效果:



Multi-Shot Case 观测:
扩散模型是如何理解多镜头的
首先思考:在镜头转场情境中,相比于单镜头视频,模型在处理多镜头序列时有何不同。对于这点,作者假设,对于两个相邻帧之间的相关性,过渡点与非过渡点之间存在显著差异,前者需要在像素级(pixel-level)差异的前提下保证语义级(semantic-level)的一致性,后者则需要实现视觉连贯性。
而在 Attention Layer 中,所有 visual token 的交互是平等的,但 Q 对于不同 K、V 的关注度则会有所不同,这表明了使用 Attention Map 作为重要观测工具的可能性。
作者对大规模预训练模型中概率出现的 Multi-Shot Case 进行观测,如预期地发现,某些 Layer 表现出较强的镜头内关联(Intra-shot)和较弱的镜头间关联(Inter-shot)。更具体地说,Attention Map 矩阵呈现块对角结构。经过量化(intra-shot vs. inter-shot probability 26.88, r=0.71),这一点被进一步证实。
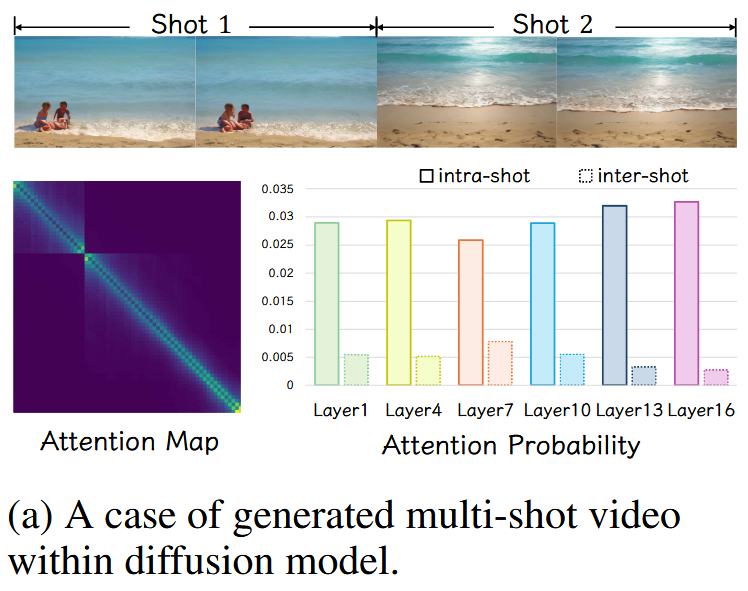
此外,作者还在某些 Layer 发现了所有 visual token 对第一帧信息的高度关注。这启发了利用 Attention 内部隐式理解达成外部条件显式转场控制的方法设计。

CineTrans:
基于掩码的控制方法
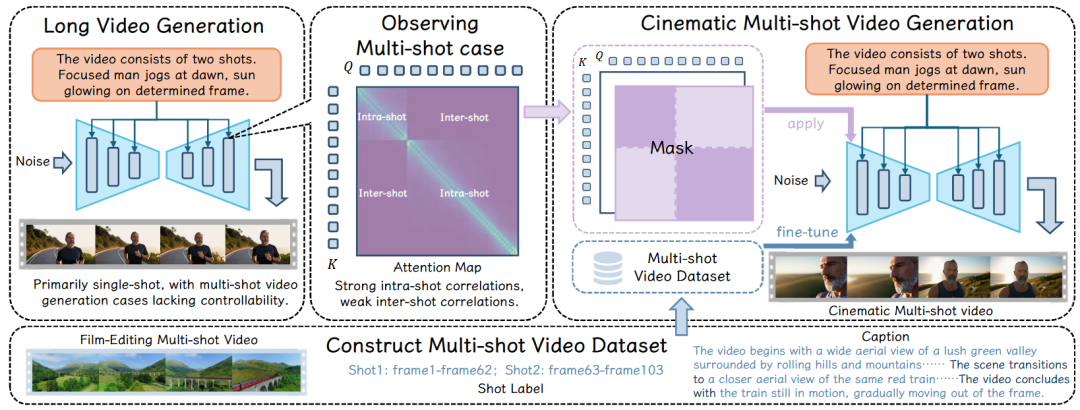
基于前文的观察,作者提出了块对角掩码架构(Block-Diagonal Mask Mechanism),并将第一帧作为锚点(Anchor),符合 Diffusion Model 本身的特性,意图在不破坏模型本身结构和先验知识的前提下实现预定义的转场时间控制。
将该掩码应用在部分 Attention Layer 中,作者发现,即使在未经训练(training-free)的情况下,模型也能在保持视觉质量的同时实现较强的时间级控制效果。


包括逐镜头生成(Shot-by-Shot)与端到端生成(End-to-End)的以往工作都可视作从两个维度解决多镜头问题:
-
转场的发生:确保视频中的两帧发生明显的像素级跳变,镜头边界不出现局部崩坏、粘连的情况。
-
转场前后的一致性维持:确保发生转场前后的画面内容在语义上呈现强关联,令画面的切换不会打断观看者的体验。
逐镜头的生成通过分别合成每个镜头自然保证的转场的发生,但将一致性的依赖至于模型外部(external),例如条件注入(conditioning)、关键帧生成(keyframe);端到端的生成通过 visual token 在前向过程中完全交互来维持整体一致性,但并不显式区分镜头间与镜头内,从而需要大规模训练才能让模型学会 multi-shot 的概念,且缺乏明确的时间级控制手段。
相比之下,CineTrans 通过选择性的掩码策略在这两个维度实现了一种平衡方案:
-
全局信息交互:通过第一帧的 anchor 与未经掩码的 full attention,visual token 进行全局交互,实现来自模型内部(internal)的一致性保证。
-
镜头内局部交互:在块对角掩码的作用下,镜头间的交互被限制,相邻镜头之间的像素信息自然形成跳变,在保持全局一致性的前提下形成稳定的转场。
进一步地,在通过多镜头视频数据集微调以后,CineTrans 也具备了电影级剪辑的先验知识,将转场前后的镜头关联理解内化在模型参数中,实现更具备电影美学的转场效果。此外,为了更丰富的内容表现,CineTrans 也在 video-text cross attention 结构中使用了 shot-level 的掩码机制,实现内容上的细粒度控制。
Cine250K:
丰富的多镜头数据集
文章还提出了 Cine250K,这也是 CineTrans 微调所采用的多镜头数据。Cine250K 经过了精细的设计,捕捉人类剪辑序列中的先验知识,提供优秀美学表现、精确镜头标签、层级细节标注的视频数据。其构建过程主要由三个阶段构成:
-
分割缝合阶段(Split & Stitch):经过镜头切换识别后,基于镜头间相邻帧之间的语义相似性将视频缝合起来,并删除软过渡的帧,明确镜头界限,奠定模型间镜头一致性的基调,提供时间级镜头标注。
-
筛选阶段(Selection):基于镜头数量、视频基本信息、美学表现等进行筛选。
-
多层级标注(Caption):为了细粒度语义控制,对逐个镜头进行内容、风格、氛围多个维度的标注,同时得到总体信息,为多粒度控制提供可能。
经过处理,最后得到了约 25 万个经过精细处理的多镜头视频-文本对,它提供了丰富的剪辑艺术先验信息,对多镜头生成任务来说,具有重要意义。
实验结果评估与分析
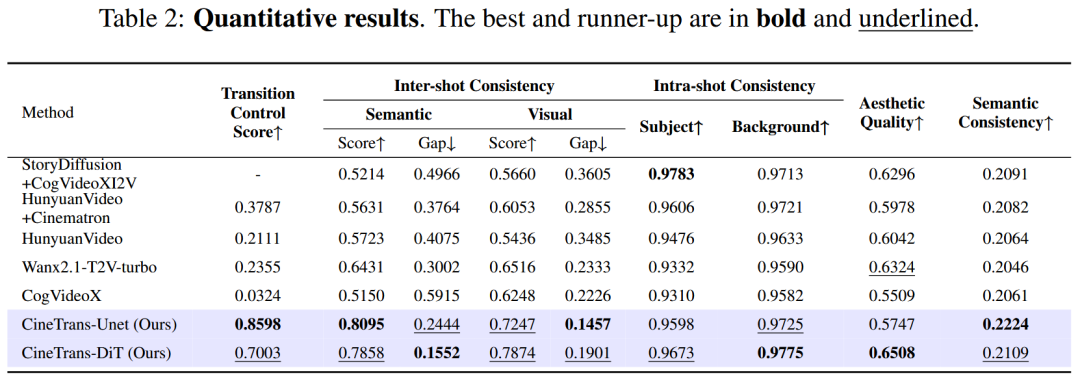
文中将 CineTrans 的转场效果与多种 Multi-shot 生成方法进行对比,包括逐镜头生成方法(StoryDiffusion + CogVideoXI2V)、大规模预训练方法(HunyuanVideo)和定制化方法(Cinematron LoRA)。结果表现出了大幅度超过基线的转场控制得分(Transition Control Score),以及在 Unet 和 DiT 架构上的泛化性。
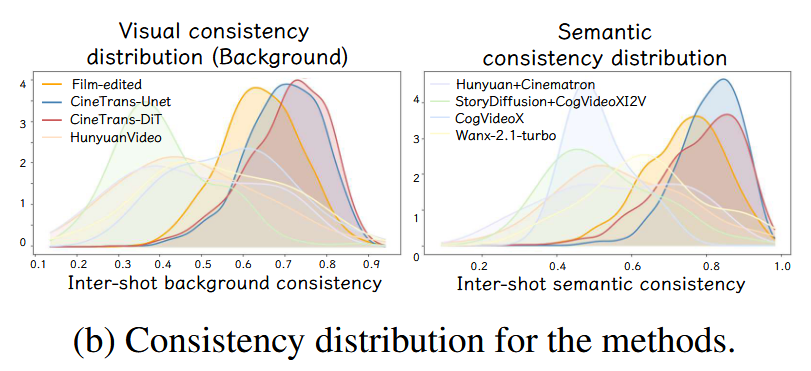
此外,为了更好地比较镜头间一致性,作者还提出了基于 JS 散度的新指标,以衡量真实剪辑的数据与生成数据的分布差异。经过可视化,CineTrans 生成的视频在一致性分布也最接近人类剪辑的视频数据,表现出了贴近人类剪辑习惯的多镜头生成能力。
总结与展望
利用扩散模型本身对多镜头序列的理解构建掩码,CineTrans 实现了符合模型先验的时间级转场控制,同时保持了镜头间一致性与视频质量。作为从逐镜头生成转向端到端生成的重要工作,它在转场与一致性之间的权衡问题上给出了一个行之有效的答案,为未来针对镜头设计、更多剪辑艺术先验的多镜头视频探索打下了坚实的基础。
目前,CineTrans 的代码、模型权重、数据集已在 GitHub 开源,欢迎社区进一步研究与使用。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com