MMDeepResearch-Bench提出多模态Deep Research Agent的可验证评测标准,强调过程可核验、证据可追溯、断言可对齐,推动Agent向可工程化发展。
原文标题:多模态Deep Research,终于有了「可核验」的评测标准
原文作者:机器之心
冷月清谈:
怜星夜思:
2、MMDR-Bench 提到了现有模型在图像细节理解上容易出错,例如小数字、轴标签等。那么,除了改进模型本身,我们是否可以通过其他方式来提高 Agent 对图像细节的理解能力,例如预处理、数据增强等?
3、MMDR-Bench 旨在推动 Deep Research Agent 的可工程化。你认为目前 Deep Research Agent 在工程化方面还存在哪些挑战?
原文内容

Deep Research Agent 火了,但评测还停在「看起来很强 」。
写得像论文,不等于真的做了研究。
尤其当证据来自图表、截图、论文图、示意图时:模型到底是「看懂了」,还是 「编得像懂了」?
俄亥俄州立大学与 Amazon Science 联合牵头,联合多家高校与机构研究者发布 MMDeepResearch-Bench(MMDR-Bench),试图把多模态 Deep Research 的评估从「读起来不错」,拉回到一个更硬的标准:过程可核验、证据可追溯、断言可对齐。
MMDR-Bench 与评测框架相关资源已公开:

-
论文标题:MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
-
论文主页:https://mmdeepresearch-bench.github.io/
-
论文链接: https://arxiv.org/abs/2601.12346
-
github 链接:https://github.com/AIoT-MLSys-Lab/MMDeepResearch-Bench
-
Huggingface 链接:https://huggingface.co/papers/2601.12346
当 Deep Research Agent 变得越来越常见,一个更现实的问题摆到了台面上:我们到底该怎么评价它的价值?很多时候,你很难用「答案对不对」去判一份研究型报告 —— 因为问题本身可能没有唯一标准答案。
真正决定可信度的,是过程纪律:有没有检索到可靠证据?关键断言有没有被引用支撑?引用是否真的对应这句话?以及最容易被忽略的一点:当证据来自图像时,它有没有「看对并用对」。
现有评测往往缺一块关键拼图:要么偏短问答(图表问答、文档问答),要么偏纯文本深研(长文 + 网页引用),很难覆盖端到端的「多模态深度研究」链路:既要写研究式长报告,又要把图像证据与文本断言逐句对齐,并且能审计、能追责。
01 为什么需要 MMDR-Bench:Deep Research 的「幻觉」不止发生在文本
在真实研究场景里,图像证据常常是不可替代的:曲线走势、轴标签与单位、表格关键单元格、截图里的开关状态、论文图中的对比结果……
这些信息一旦读错,就会把后续检索与合成带偏,最后变成一份「写得很像、引用很多,但根上错了」的报告。
问题在于,传统「引用评测」往往只看有没有 URL,却不追问 Claim–URL 是否真的支撑;传统「多模态评测」多是短问答,又覆盖不了 agent 的长链路检索与报告合成。MMDR-Bench 想做的,是把这两件事接起来:让多模态 deep research 的输出能被逐句核验。
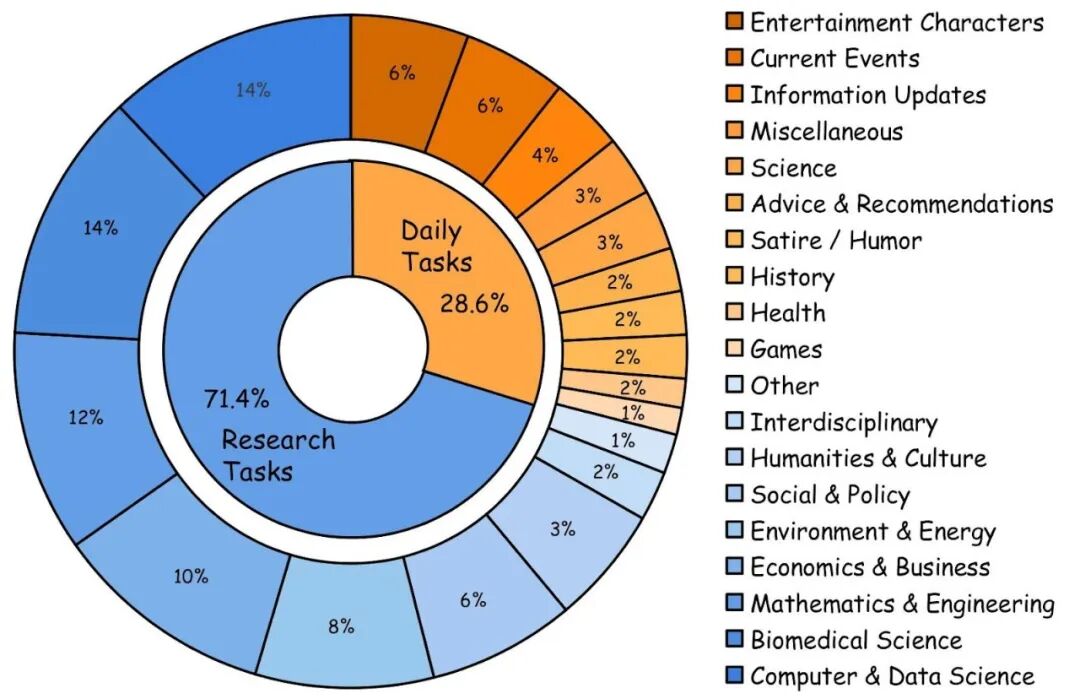
02 MMDR-Bench 是什么:140 个专家任务,覆盖 19 个领域
MMDR-Bench 包含 140 个由领域专家打磨的任务,覆盖 19 个领域。每个任务都提供「图像 — 文本 bundle」:你不仅要检索网页、汇总证据,还必须解释并使用给定图像中的关键事实来支撑报告结论。
作者将任务划分为两种使用情境:
-
Daily:偏日常使用场景,输入多为截图、界面、噪声较高的图片,考察系统在不完整信息下的稳健理解与可核验写作。
-
Research:偏研究分析场景,输入多为图表、表格、示意图等信息密集视觉证据,强调细粒度读图与跨来源综合。

03 怎么评:不押「唯一答案」,押「证据链 + 过程对齐」
为了解决「开放式问题没有标准答案」的评测困境,MMDR-Bench 把评估拆成 3 段管线、12 个可定位指标,重点不在「结论是不是唯一正确」,而在「证据链是否站得住」。
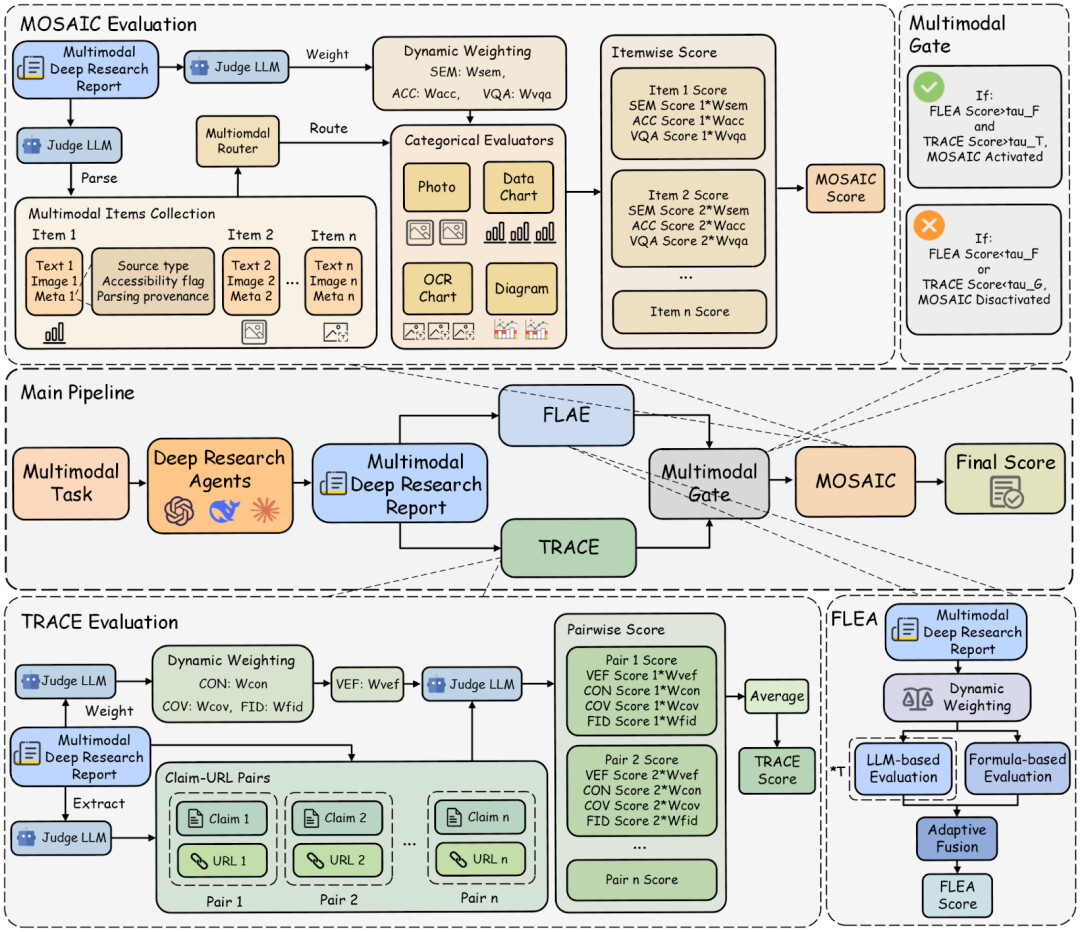
(1)FLAE:可解释的长文质量评估(可审计)
长报告的要求随任务而变。FLAE 用可复现的文本特征公式(结构、可读性、覆盖度等)叠加任务自适应评审信号,避免「一把尺子量所有报告」,同时保证评分可回放、可解释。
(2)TRACE:Claim–URL 支撑核验,让引用不再是装饰
TRACE 将报告拆成原子断言,并对齐到引用 URL,检查是否支持、是否矛盾、是否过度推断,给出一致性、覆盖率与证据忠实度等指标。
更关键的是,它加入 Visual Evidence Fidelity(Vef.)作为硬约束:报告必须严格遵守题目给出的图文prompt,不得在分析题目时通过幻觉作答;一旦出现实体误识别、图中不存在却编造、数字、标签、映射关系读错,会被严格惩罚。
(3)MOSAIC:把「用到图像的句子」逐条对齐回图像本身
很多错误并不体现在 URL 上,而体现在「引用图像的句子」与图像内容不一致。MOSAIC 专门抽取这些多模态条目,按图表、照片、示意图等类型走不同核验规则,定位「看错图、用错图、引用图但没真正 grounded」的失败。
科研从来没有银弹。Deep Research 也是 —— 尤其当信息不完整、证据不确定时。与其赌一次性的「正确结果」,不如把尺子钉在过程:每一步检索、取证、引用与推理,都能被回放、被核对、被追责。
04 观察到的现象:强写作 ≠ 强证据;会看图 ≠ 会引用
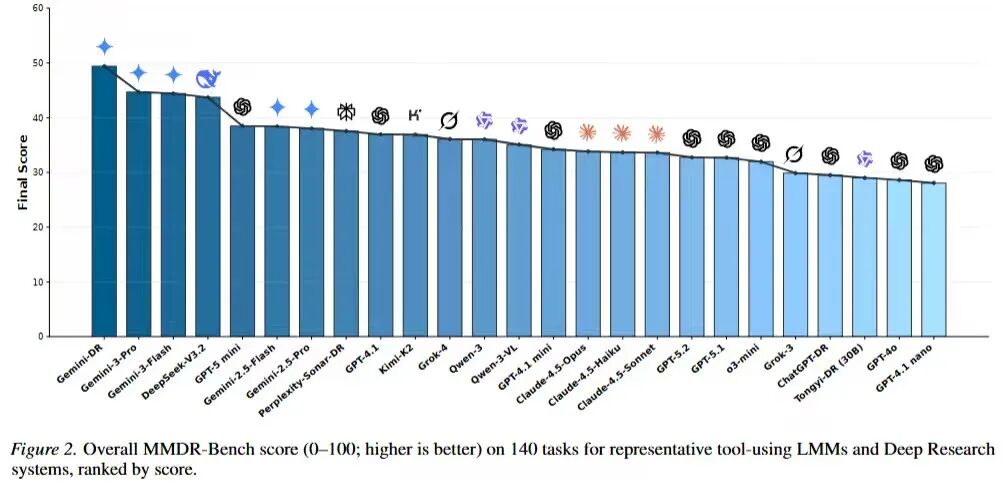
-
有的模型写作与结构很强,但 Claim–URL 对齐松散,容易出现「引用很多、支撑很弱」;
-
有的模型能读图抓到信息,但长链路合成中发生实体漂移,把证据绑到错误对象上;
-
有的系统检索覆盖率高,却在图像细节(小数字、轴标签、单位、映射关系)上翻车,导致视觉忠实度显著掉分。
也正因如此,能力并不会随着版本号线性上扬:有些模型读起来更「像一个会写的研究者」,但在证据对齐与多模态忠实度上仍会失分 —— 榜单上甚至不需要细看,一眼就能读出来。deep research 的关键瓶颈,正在从「能写」转向「能被查」。
05 更现实的意义:给 agent 对齐一个可训练的信号
Deep Research 的下一阶段,不是谁写得更像论文,而是谁的过程经得起核验。
MMDR-Bench 做的,就是把「经得起核验」这件事定成硬标准:每条关键断言都要能被证据接住,每个引用都要能被追溯到支撑点,每次用图都要能对齐到可观察事实。
这会直接改变系统迭代方式 —— 你不再凭感觉调 prompt,也不再被「看起来很强」的报告迷惑,而是用可定位的失败模式去驱动模型与工具链升级。
当评测开始追责过程,deep research 才真正进入可工程化的时代。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com