「斯坦福小镇」团队成立Simile公司,获李飞飞等投资,探索Agent技术的人类行为规模化模拟!通过模拟个体决策,构建大规模系统,进行反事实实验。
原文标题:《西部世界》开始加载,「斯坦福小镇」团队创业,李飞飞、Karpathy都投了
原文作者:机器之心
冷月清谈:
怜星夜思:
2、如果Simile的技术被广泛应用,可能会对哪些行业产生重大影响?
3、Simile的模拟技术,如果出现偏差或者被恶意利用,可能会带来哪些潜在风险?
原文内容
还记得 2023 年爆火的「斯坦福小镇」吗?当时该研究一经发布,就震撼了整个 AI 圈。
这项研究几乎把《西部世界》的设想拉进现实:研究者构建了一个名为 Smallville 的「虚拟小镇」,让 25 个 AI 智能体在其中生活。他们各自有工作,会闲聊八卦,能自发组织社交、结交新朋友,甚至还会一起筹备情人节派对……
就在近日,迎来了新的延续 —— 创始团队多位核心成员共同创立了新公司 Simile,试图进一步利用 Agent 技术对人类行为进行规模化模拟。
刚刚,论文作者之一 Joon Sung Park 也在 X 上正式官宣了 Simile 的成立,并披露公司已完成 1 亿美元融资。投资人包括李飞飞、Andrej Karpathy 等众多 AI 大佬。
在宣传视频中,Joon 介绍到:模拟人类行为,是这个时代最具深远影响、同时也是技术难度最高的问题之一。

2023 年打造了模拟小镇 Smallville,现在是时候模拟我们所处的真实世界。
Simile 从个体出发,建模真实人类如何做决策,然后将这些个体自下而上地组合成大规模模拟系统。他们把每一次变化称为一次 simile change:只要调整一个假设、一个约束或一个角色设定,整个世界就会随之重新编译。
在这里,你可以运行那些现实中无法进行的反事实实验,理解什么真正有效、什么会适得其反,以及为什么那些看似显而易见的策略最终会失败。
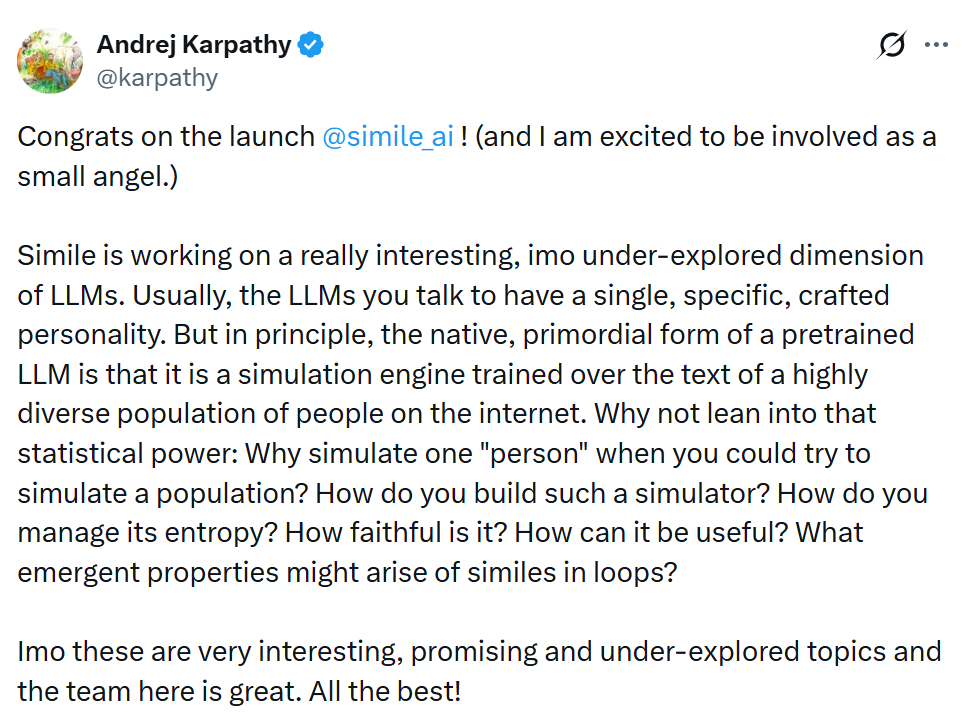
作为投资者之一的 Karpathy 表示:Simile 正在探索一个非常有趣、但仍被低估的 LLM 维度。通常我们与之对话的大模型,往往被赋予一个单一、精心设定的人格。但从原理上看,一个预训练 LLM 的原生形态,其实更像是一个基于互联网海量、多样化人类文本训练而成的模拟引擎。
既然如此,为什么不充分利用这种统计层面的能力?为什么只模拟一个人,而不去尝试模拟一个群体?这样的模拟器该如何构建?如何管理其中的熵?它的拟真度如何衡量?又能在哪些场景中真正发挥价值?当多个 Simile 在循环交互中运行时,又会涌现出哪些新的性质?
这些都是极其有趣、前景广阔但仍有待深入探索的方向。
公司介绍
根据公开资料显示,Simile 成立于 2025 年。
Simile 通过构建人的模拟体,帮助客户回答关于其受众、市场或人群可能如何反应的复杂问题。不同于传统方法,Simile 采用经过科学验证的生成式智能体 —— 这些基于真实人类数据训练的虚拟个体,能够实现即时交互、快速实验以及更准确的预测。用户只需通过简单的文本或图像输入,就可以直接与这些模拟的个体或群体进行互动。
Simile 由来自斯坦福大学的顶尖科学家与工程团队打造,他们曾主导多项生成式 AI 领域最具影响力的突破,包括生成式智能体与仿真技术的提出、提出基础模型(foundation models)这一概念,以及构建被广泛采用的机器学习模型与仿真评测基准。
团队人员包括:Joon Park 为斯坦福博士、《Generative Agents: Interactive Simulacra of Human Behavior》共同作者;Michael Bernstein 为斯坦福教授,已任教 12 年;Percy Liang 为斯坦福教授,同样拥有 12 年教职经历。目前,公司团队还包括 3 名技术研究人员、2 名业务成员以及 1 名行政人员。

斯坦福小镇原始论文作者,Simile 创始团队成员包括其中三位。
参考链接:
https://www.paraform.com/company/simile
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com