DeepSeek模型迎来更新,最显著的提升是上下文处理能力扩展到1M Token!知识截止日期延至2025年5月,回答风格也更加热情。
原文标题:来了,DeepSeek悄悄上新模型!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、DeepSeek 这次模型更新,回答风格变得更“热情”、更细腻了,你们觉得 AI 的个性化表达是好事吗?会不会让人们对 AI 产生情感依赖?
3、DeepSeek 开年搞了技术三连发,又是新架构,又是新机制,又是新模型,你们觉得这些技术最终会如何影响大模型的发展方向?
原文内容

来源:Datawhale本文约1000字,建议阅读5分钟DeepSeek 悄悄上线最新模型,是V4?

新版本有什么不同?
一、超长上下文
新版本支持处理更长的文本输入,达到了 1M Token(百万级别)——如果属实,这个容量可以一次性处理《三体》三部曲那么多内容。相比之前 V3.1 的 128K Token,这是近 10 倍的提升。
二、知识更新了
模型在不联网的情况下,已经能准确回答 2025 年上半年的一些事件。知识截止日期从之前的 2024 年 7-8 月更新到了 2025 年 5 月左右。
三、回答风格变了
新版本的语言风格明显变得更“热情”、更细腻。看起来 DeepSeek 可能在用户体验上做了一些调整。
四、依然是纯文本
这次更新目前没有加入视觉理解能力,模型仍然只能处理文本和语音,不能直接“看懂”图片(虽然可以通过 OCR 读取图片中的文字)。
DeepSeek实测
如今Agentic Coding能力十分重要,@PaperAgent 简单测了一个烟花coding的案例
打造一个震撼人心的动画烟花盛宴!用单一HTML文件,融合CSS与JavaScript,让屏幕瞬间化为璀璨夜空。烟花要有多种颜色、爆炸轨迹,最好能自动循环绽放。
思考更充分,速度挺快,效果比之前要更加酷炫~
最后测了一个近期较火的经典逻辑难题,快速模式下翻车了


DeepSeek 2026 的技术三连发
值得注意的是,DeepSeek 开年的技术三连发
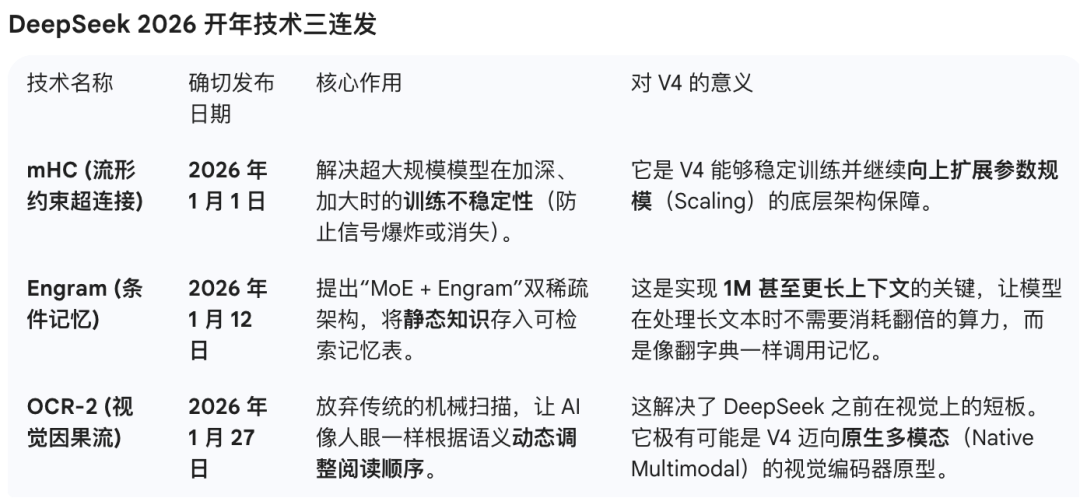
-
元旦期间公布了 mHC(流形约束超连接)论文,提出了一种新的网络架构设计思路
-
1 月 12 日发布了 Engram 论文和代码,探索“条件记忆”机制
-
1 月 27 日开源了 OCR-2 模型,视觉压缩能力提升明显
这些技术是否已经应用到当前测试版本中?目前还不确定。但从时间节点来看,这些研究成果很可能会出现在即将发布的版本里。
编辑:文婧
