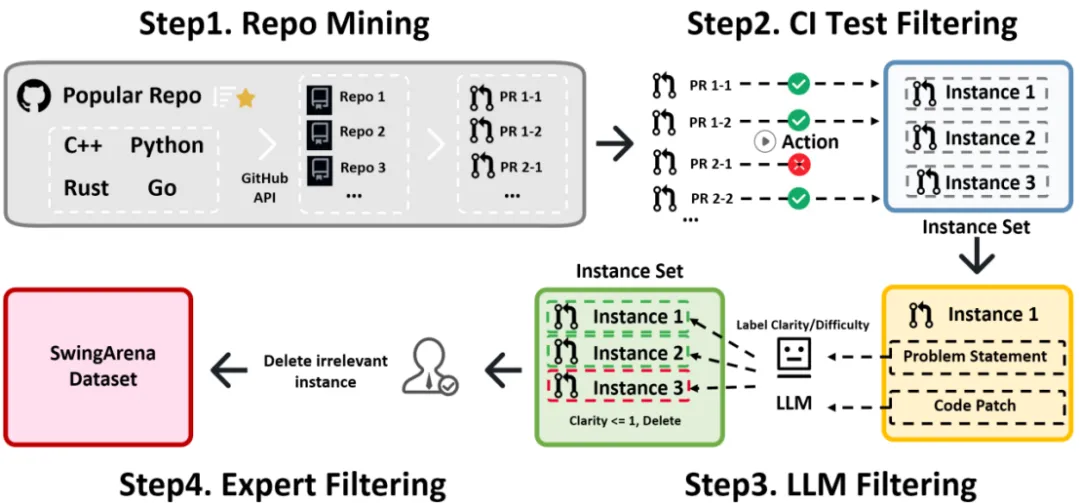
SwingArena模拟真实CI环境,对抗式评估AI代码的工程可用性,帮助选择适合生产环境的AI编程助手。
原文标题:ICLR 2026 oral | AI代码真能进生产环境?SwingArena:从「写对代码Commit」到「通过CI审查」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、RACG 检索增强流水线如何平衡“给模型多少代码”与“给对代码”? 在实际项目中,如何确定哪些代码片段是“最关键、最相关的”?
3、SwingArena 的评测结果显示,不同模型在工程决策上存在“性格差异”,例如 GPT-4o 比较激进,而 DeepSeek 和 Gemini 则更保守。你认为这种差异是由什么造成的? 在实际应用中,应该如何根据不同的需求选择合适的模型?
原文内容

过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。
这种能力的提升,让很多人开始认真思考一个问题:AI 能不能真正参与到软件工程的核心流程中?
但越接近真实开发,这个问题就越显得复杂。因为在工业界,“写出一段能跑的代码” 远远不够。
代码是否能被合并,取决于它能否通过完整的持续集成(Continuous Integration,简称 CI)流水线——这是一种在代码开发过程中,通过自动化的构建、测试和代码检查,确保每一次改动都能在真实工程环境下稳定运行的机制。
此外,代码还需符合项目规范、经得起代码审查,并在多轮修改中保持稳定可靠。遗憾的是,现有主流代码评测基准,几乎都停留在“能否通过几个单元测试”的层面。
SwingArena 的出发点,正是填补这块长期缺失的评测空白。
该论文已被 ICLR 2026 正式接收。目前,SwingArena 已实现全栈开源。

-
论文标题:SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
-
论文链接:https://arxiv.org/abs/2505.23932
-
项目链接:https://swing-bench.github.io/
从 “写对代码” 到 “通过审查”,
评测逻辑需要一次转向
在传统评测中,模型面对的是一个高度简化的问题:给定函数签名和说明,只要输出能通过测试的实现即可。这种设定对于衡量基础编程能力是有效的,但它忽略了真实软件开发中最关键的一环 —— 审查与迭代。
在现实中,一段代码往往要经历多个回合的反馈与修改,才能最终被接受。CI 系统会自动检查编译、测试、代码风格和潜在风险,而审查者则会从逻辑正确性、边界情况和可维护性等角度不断提出质疑。这种过程,本质上是一种持续博弈。
SwingArena 将这种博弈引入评测之中。它不再让模型 “单打独斗”,而是通过对抗式设定,让两个模型分别扮演 “提交者” 和 “审查者”,在真实 CI 环境中反复交锋。
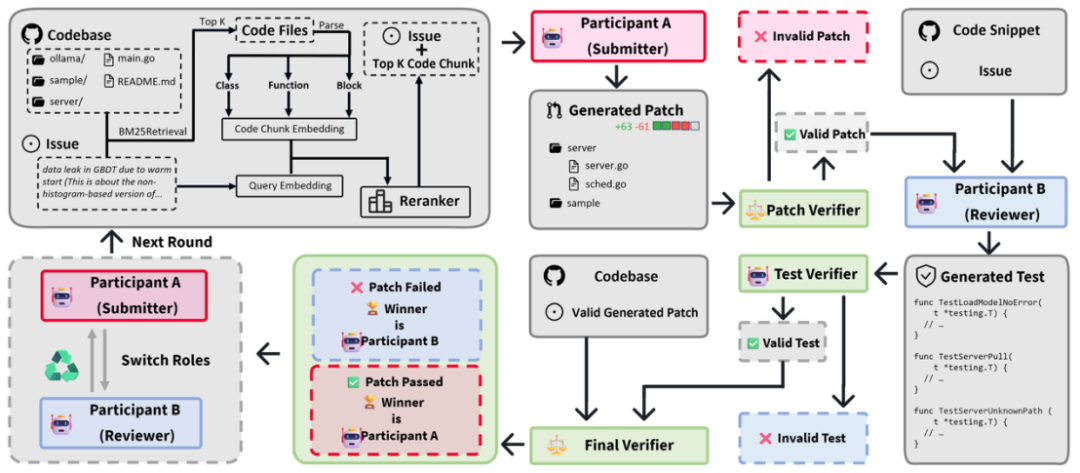
提交者需要写出足够稳健的补丁才能通过流水线,而审查者则试图通过精心设计的测试暴露潜在问题。最终的得分,完全由真实执行结果决定。
真实工程环境,意味着真实复杂度
要让评测真正贴近工业场景,仅有对抗机制还不够。另一个更现实的挑战在于:真实项目的代码规模,远远超出了大模型的上下文窗口。
一个常见的开源仓库往往包含数万行代码,分布在数百个文件中。模型不可能 “通读全库”,只能在极其有限的上下文中做判断。SwingArena 因此设计了一套完整的检索增强流水线 RACG(Retrieval-Augmented Code Generation),试图在 “给模型多少代码” 与 “给对代码” 之间取得平衡。
RACG 的核心思路,是先通过经典信息检索方法快速缩小文件范围,再以语法结构为单位对代码进行切块,并使用语义模型进行精排。在严格的 token 预算下,系统会动态调整上下文粒度,确保模型看到的是最关键、最相关的代码片段,而不是噪声。
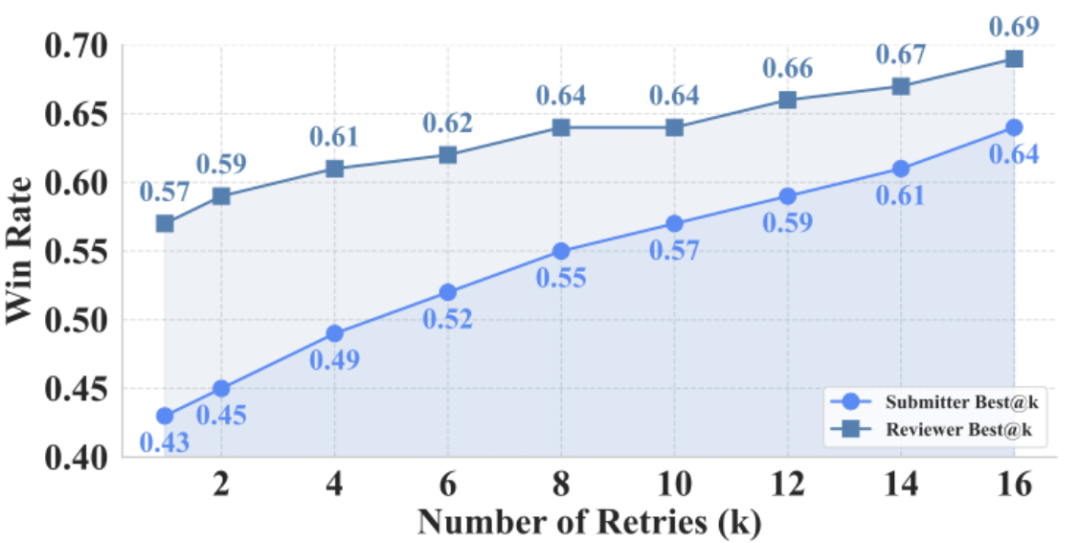
消融实验显示,这种分层检索策略,能够显著提升补丁定位的准确率,相比仅使用关键词匹配,Top-10 命中率提升超过一倍。这意味着模型不只是 “写代码”,而是在更接近人类工程师的认知范围内工作。
当模型真正对抗,差异才开始显现
在 SwingArena 的评测中,一个有趣的现象逐渐浮现:不同模型在工程决策上的 “性格差异”,被前所未有地放大了。
以 GPT-4o 为例,它在提交者角色中表现得极为激进,往往能够快速生成足以击败对手测试的补丁,因此胜率很高。但这种策略的代价是 CI 通过率并不稳定,代码在规范性和鲁棒性上更容易出现问题。
相比之下,DeepSeek 和 Gemini 的表现则明显更为保守。它们生成的代码风格更加规范,通过 CI 的概率也更高,尤其在多语言场景下展现出更强的稳定性。这类差异,在传统基准中往往被 “平均分” 所掩盖,而在对抗式评测中却变得非常直观。
更重要的是,这些结果为实际应用提供了清晰的参考:当目标是快速原型和探索性开发时,激进策略可能更有效;而在生产环境和长期项目中,稳定性显然更重要。
从评测到实践:
为什么 SwingArena 值得被重视
SwingArena 的意义,并不仅仅在于提出了一个新的 benchmark。它更重要的价值,在于推动了一次评测视角的转变:从 “功能正确性” 走向 “工程可用性”。
通过将 CI 流水线、代码审查和多轮迭代引入评测过程,SwingArena 让我们第一次能够系统性地回答这样的问题:哪些模型真的适合进入生产环境?在不同工程场景下,应该如何选择和使用它们?又该如何设计更符合现实需求的 AI 编程助手?
在论文匿名期结束后,SwingArena 将完整开源,包括数据集、评测框架、检索流水线以及所有实验复现代码。团队希望,这套框架不仅能成为研究者比较模型的新工具,也能为工业界评估和落地 AI 编程能力提供参考。
当 AI 生成的代码真正走进 CI 流水线,评测的标准,也必须随之升级。
SwingArena,正是向这个方向迈出的一步。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com