智谱发布 GLM-5 大模型,代码能力显著提升,性能逼近 Claude Opus 4.5,并已在国产芯片上部署。 #AI #大模型 #智谱
原文标题:编程超越 Gemini 3 Pro?GLM-5 性能实测对齐 Opus 4.6,智谱市值突破1700亿港元
原文作者:AI前线
冷月清谈:
怜星夜思:
2、智谱 GLM-5 强调了对国产芯片的支持,但在算力方面仍然面临挑战,你如何看待国产大模型在算力瓶颈下的发展路径?
3、GLM-5 的定价策略,输入成本比 Opus 便宜 6 倍,输出成本便宜 10 倍,你认为这种定价策略会对国内大模型市场产生什么影响?
原文内容

临近春节,智谱 AI 发布了其最新旗舰大模型 GLM-5。自 1 月初在香港进行备受关注的 IPO 之后,这是该公司推出的首款重磅大模型。

据称,GLM-5 标志着人工智能开发从“Vibe Coding”变革为“Agentic Engineering”,即更大规模的 AI 自动化编程,其代码能力实现跨越式提升。该公司的内部测试显示,GLM-5 在代码能力、智能体表现等关键领域的开源模型评分中取得 SOTA 表现,在真实编程场景的使用体感逼近 Claude Opus 4.5,擅长复杂系统工程与长程 Agent 任务。
目前,这款新模型已在智谱官网上线,并在 GitHub 和 Hugging Face 平台开源,模型权重遵循 MIT License。
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5
OpenRouter:http://openrouter.ai/z-ai/glm-5
值得一提的是,智谱在官宣帖中特意注明“GLM-5 在 OpenRouter 上的前称是 Pony Alpha”。就在几天前,全球模型服务平台 OpenRouter 上一款代号为“Pony Alpha”的神秘模型,因卓越性能和一系列令人惊艳的实测表现走红。当时,该平台合作方 Kilo Code 透露,Pony Alpha 是“某个全球实验室最受欢迎的开源模型的专项进化版”。
之后,Pony Alpha 被众人猜测可能是 Anthropic 的 Claude Sonnet 5、DeepSeek-V4 或者 GLM-5 的提前试水。现在,答案终于被“正主”揭晓。
官宣 GLM-5 后,智谱的股价连续暴涨。截止发稿前,智谱的市值突破 1700 亿港元。
自封“系统架构师”,
性能超过 Gemini 3 Pro
一个多月前,智谱才刚刚更新到 GLM‑4.7 。据介绍,GLM-5 的参数规模是上一代 GLM-4.7 的两倍,从 3550 亿提升至 7440 亿,训练数据量从 23 万亿增至 28.5 万亿 tokens,更大规模的预训练算力显著提升了模型的通用智能水平。
并且,该模型构建了全新的“Slime”框架,支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
此外,GLM-5 还采用了由 DeepSeek 率先提出的全新架构 DeepSeek 稀疏注意力机制,在维持长文本效果无损的同时,大幅降低模型部署成本,旨在最大化计算效率与成本效益。
在编程能力上,GLM-5 实现了对齐 Claude Opus 4.5,在业内公认的主流基准测试中取得开源模型 SOTA。在 SWE-bench-Verified 和 Terminal Bench 2.0 中分别获得 77.8 和 56.2 的开源模型最高分数,性能超过 Gemini 3 Pro。
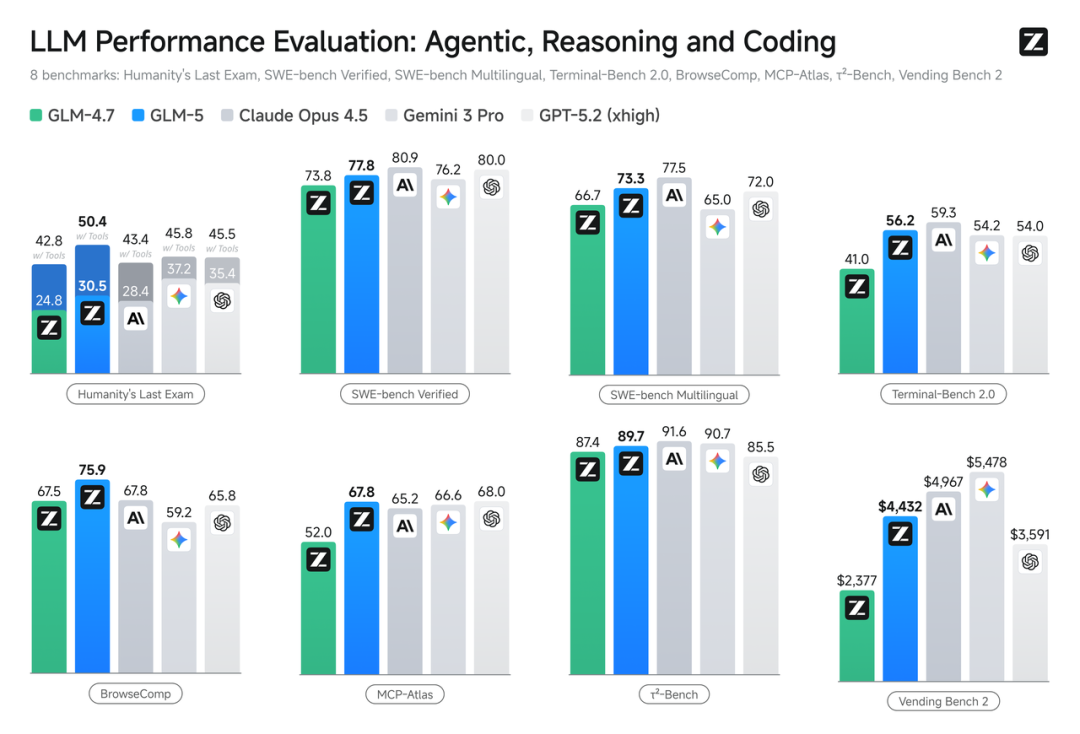
在内部 Claude Code 评估集合中,GLM-5 在前端、后端、长程任务等编程开发任务上显著超越上一代的 GLM-4.7(平均增幅超过 20%),能够以极少的人工干预自主完成 Agentic 长程规划与执行、后端重构和深度调试等系统工程任务,使用体感逼近 Opus 4.5。用智谱的话说,GLM-5 是一个“系统架构师”,不仅为开发精美的 Demo 而生,更为稳定交付生产结果而生。
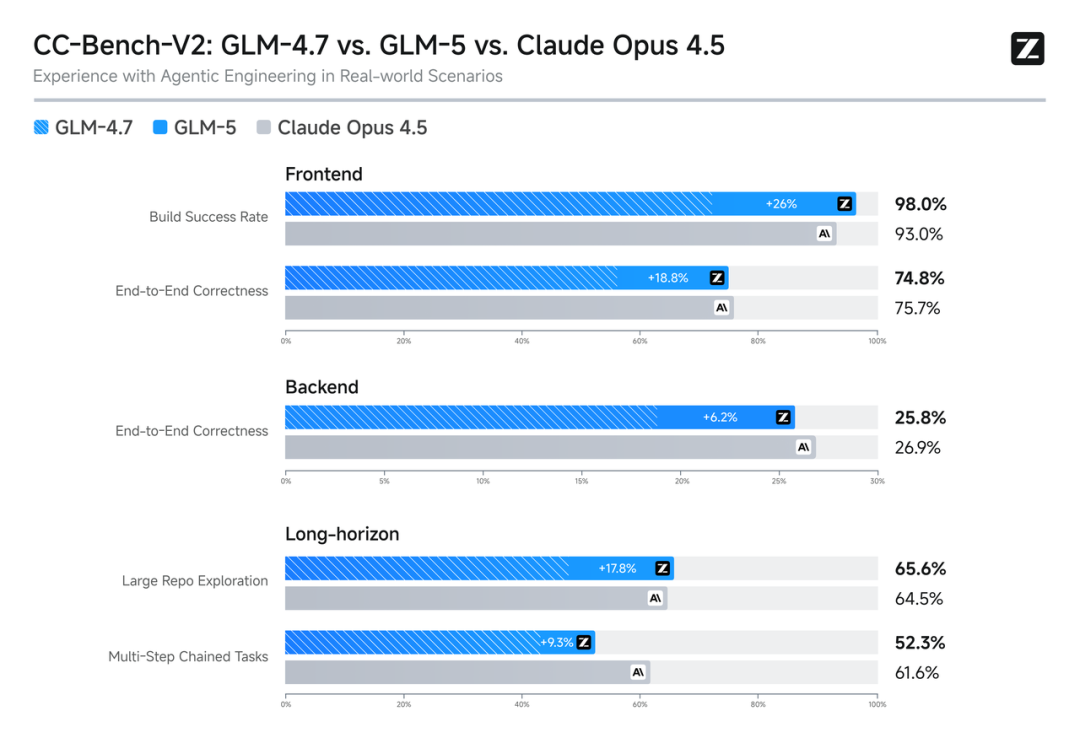
在 Agent 能力上,GLM-5 实现开源 SOTA,在多个评测基准中取得开源第一,在 BrowseComp(联网检索与信息理解)、MCP-Atlas(大规模端到端工具调用)和 τ²-Bench(复杂场景下自动代理的工具规划和执行)均取得最高表现。在衡量模型经营能力的 Vending Bench 2 中,GLM-5 获得开源模型第一表现。Vending Bench 2 要求模型在一年期内经营一个模拟的自动售货机业务,GLM-5 最终账户余额达到 4432 美元,经营表现接近 Claude Opus 4.5。
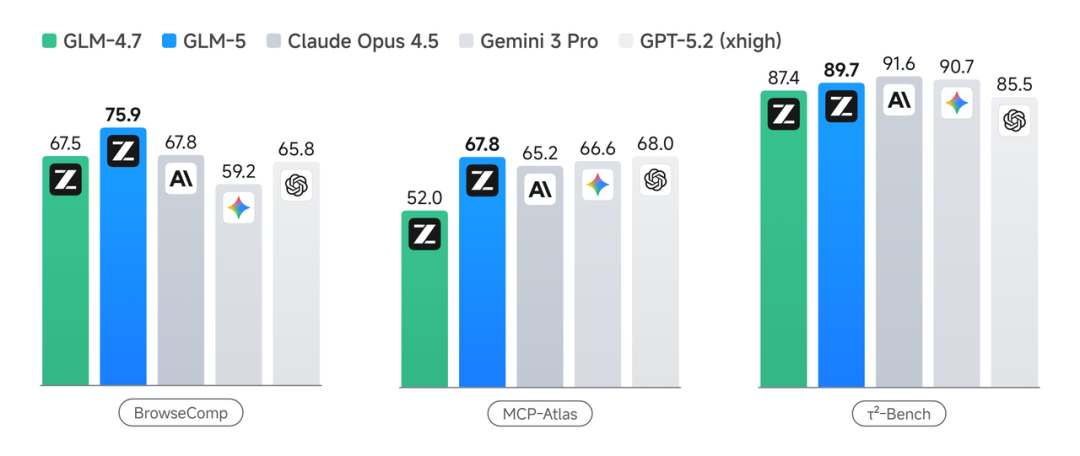
不过,该公司自行公布的分数也显示,在各项代码基准测试中,这款模型仍全面落后于 Anthropic 的 Claude。
“价格简直离谱”,
实测被评最优秀开源模型之一
此前,在 OpenRouter 匿名上线时,就有许多开发者使用 GLM-5 完成了真正能用、能玩、能上线的应用,例如横版解谜游戏、Agent 交互世界、论文版“抖音”等应用。如今公开推出后,又迎来一波开发者的积极试用。
“GLM-5 现在已经能和 Opus 4.6 同台竞技了。”一位开发者表示,“我一整个上午都在编程任务和游戏环境里折腾 GLM-5。整体来说,它在某些任务上执行得很快,表现不错,但碰到更复杂的场景,对我而言 Claude 依然是王者。”
另一位开发者则称,GLM-5 表现得很完美,绝对是目前发布的最优秀开源模型之一。“我在 Ollama 命令行和 Claude Code 里都跑了一遍。我发现 Claude Code 里有个缺陷,但找到了临时解决办法。我的 GLM-5 对话会话达到了和 Opus 4.6 同一水准的自我认知 / 理解深度。”

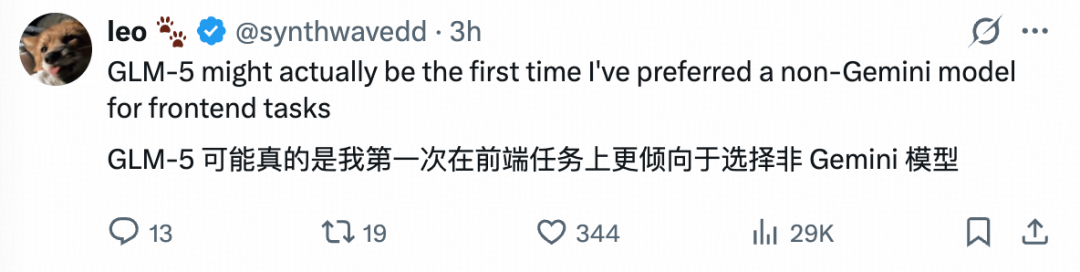
还有开发者评价道,“GLM-5 可能真的是我第一次在前端任务上更倾向于选择非 Gemini 模型。”
“价格简直离谱”,有开发者算完后表示,GLM5 的输入成本比 Opus 便宜 6 倍,输出成本便宜 10 倍。

依托国产芯片,
“把每一块芯片用到极限”
值得注意的是,智谱在发布公告中表示,GLM-5 可基于一批中国半导体企业的国产芯片部署,包括华为、摩尔线程、寒武纪、百度昆仑芯、沐曦集成电路、燧原科技及海光信息。而本次 GLM-5 的上线,也是依托众多国产芯片有力保障了线上服务的稳定和高效。
去年年初,智谱被美国列入实体清单。近几个月来,智谱已宣布致力于在纯国产硬件体系上研发前沿大模型。不过,受限于算力资源,智谱也被迫限制其旗舰产品在国际市场的应用。这一情况在 GLM-5 上仍在延续。
“算力非常紧张。即便在 GLM‑5 发布前,我们为了支撑推理服务,已经把每一块芯片都用到极限。”智谱表示,因 “算力容量有限”,将逐步向代码订阅用户开放 GLM‑5,并提醒用户,使用新模型可能会更快耗尽使用额度。
智谱也宣布,基于实际使用情况与资源投入变化对 GLM Coding Plan 套餐价格体系进行结构性调整,包括:取消首购优惠,保留按季按年订阅优惠;套餐价格进行结构性调整,整体涨幅自 30% 起;已订阅用户价格保持不变。
当前,中国几乎所有前沿大模型开发者都在农历新年前密集发布重磅产品,复刻了去年 DeepSeek 借此一举成名全球的打法。同样在香港上市的 MiniMax,也在昨天官宣了其重磅新模型 M2.5,并已在官网开放试用。
与此同时,DeepSeek 刚刚对其模型进行小幅升级,将对话上下文窗口扩展至 100 万 tokens 以上,其备受期待的全新旗舰模型尚未发布。让我们拭目以待。
参考链接:
https://z.ai/blog/glm-5

