TeleAI发布TextOp,首创流式文本驱动人形机器人控制,实现机器人与人实时自然语言交互,为具身智能发展铺平道路。
原文标题:让机器人「秒懂人话」!中国电信TeleAI发布首个实时文本驱动人形机器人控制框架TextOp
原文作者:机器之心
冷月清谈:
怜星夜思:
2、TextOp 通过文本指令控制机器人,那么对于更加复杂的、需要多轮交互才能完成的任务,例如“帮我倒杯水”,TextOp 是如何处理的?它是否需要结合大语言模型(LLM)才能实现?
3、TextOp 在哪些实际应用场景中最有潜力?除了文章中提到的内容创作、动作示范和遥操作,还有没有其他值得期待的应用方向?
原文内容

人形机器人正在舞台上大放异彩:街舞、空翻、武术套路…… 但这些令人眼花缭乱的表演,大多暗藏「玄机」—— 它们往往依赖预录的人类动作跟踪,通过「一个动作一个策略」的僵硬模式实现。想要换一支舞?需要手动切换模型。想临时加个动作?只能拿起遥控器。这种「表面智能,本质播放」的模式,让机器人始终无法走出实验室,更无法满足人们对「人机自然交互」的期待。
针对这一痛点,中国电信人工智能研究院(TeleAI)具身智能团队推出人形机器人 TextOp 通用小脑,首创流式文本驱动的实时小脑控制范式。无需预编程、无需遥控器,用户只需像对话一样随时发出文本指令,机器人即可在运动中实时理解、无缝切换动作,真正实现了「大脑随时改主意,小脑依然稳落地」的类人交互体验。
此项成果由中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领科研团队创新完成,并已在 GitHub 开源代码仓库。
-
项目主页: https://text-op.github.io/
-
代码仓库: https://github.com/TeleHuman/Textop
在深入了解技术细节之前,让我们先通过视频感受 TextOp 带来的革命性变化:
TextOp 表现的重要特性:
-
无缝衔接: 真正的一镜到底,所有动作一气呵成。
-
舞姿多变: 从律动的街舞到优雅的民族舞,风格切换行云流水。
-
武术展示: 功夫套路刚柔并济,展现惊人的动态平衡能力。
-
情感交互: 挥手、点头,肢体语言细腻如人。
-
即时响应: 现场观众随机给出指令,机器人毫秒级反应,指哪打哪。
试想这样一个场景:你对身边的机器人说「来一段街舞」,它立刻随着节奏律动;紧接着你发出新指令「做一个跳跃动作」,它瞬间腾空而起;随后你说「挥手打个招呼」,它又能优雅地切换回社交模式。整个过程中,机器人始终保持流畅的全身运动,并且能够根据你的实时指令无缝切换各种动作。
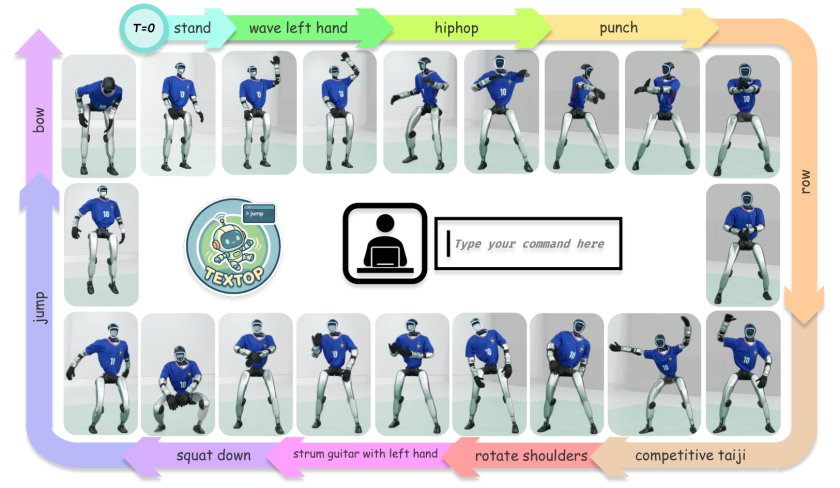
图 1:TextOp 概览 - 实现人形机器人通过实时文本指令执行多样技能的无缝序列。
从「预编程」到「对话式」:
机器人控制的新范式
现有的机器人通用控制器系统往往面临两难困境:要么依赖预设轨迹,动作死板僵硬;要么依赖人类远程操控(遥操作),失去了自主性。这种「一刀切」的模式,早已无法满足人们对智能机器人「听得懂、动得快、变得强」的期待。
TeleAI 研究团队敏锐地捕捉到了这一痛点:如何让机器人像人类交流一样,通过自然语言实现实时、连续的交互控制?
基于此,TextOp 应运而生。其核心创新在于提出了「流式文本驱动的人形机器人实时控制范式」。与传统的「一次性指令」不同,TextOp 支持流式文本指令(Streaming Text Commands)—— 这意味着用户可以在机器人执行任务的过程中随时修改意图,机器人能实时「听懂」并立即调整动作,真正做到言出法随。
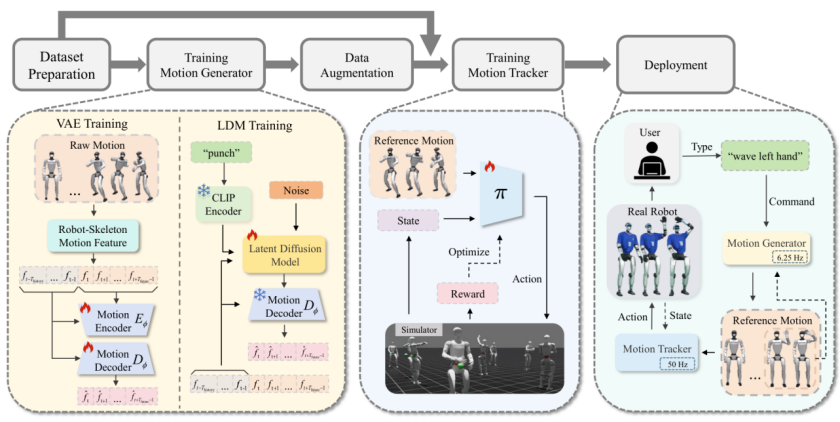
图 2:TextOp 方法架构 - 包含交互式运动生成、运动跟踪和部署三个主要部分
解密 TextOp:三大核心技术引擎
为了实现这一突破,TextOp 在架构设计和算法层面进行了三大关键创新,巧妙解决了「意图理解」与「精准控制」之间的矛盾。
1. 双层架构设计:让「大脑」与「小脑」完美协同
TextOp 采用了一种类人的双层架构,将高层的意图规划与底层的动作执行巧妙解耦:
-
上层 “大脑”(生成器):
1. 采用自回归文本条件运动扩散模型(结合 VAE 与 LDM)。
2. 它像人类的大脑皮层一样,基于历史动作和当前文本指令,持续构想未来的短时运动轨迹(每次生成 8 帧),负责「想做什么」。
-
下层 “小脑”(跟踪策略):
1. 采用通用全身运动跟踪策略(基于 PPO 强化学习训练)。
2. 它将上层生成的轨迹转化为高频关节指令(50Hz),负责「如何保持平衡地做出来」。
这种「高层意图随时更新,低层控制始终稳定」的设计,确保了机器人即使在改变主意(切换指令)时,也能像人类一样保持步态的连贯和身体的平衡。
2. 创新的运动表示:专为机器人「量身定制」
传统的运动生成系统常直接套用 SMPL 等人体骨架模型,但机器人的机械结构(单自由度关节)与人类(球形关节)存在本质差异。
TextOp 并未生搬硬套,而是创新性地采用了基于自由度(DoF)的增量表示法。系统每一帧的特征包含:
-
根姿态的旋转与增量
-
局部平移增量
-
关节角度及其增量、足部接触状态
这种表示方法天然地强制执行了机器人的运动学约束,从源头上保证了生成的动作不仅「像人」,而且在物理上「可行」。
3. 数据分布对齐:打通「仿真」到「现实」的最后一公里
在机器人研发中,「仿真训练」与「真实部署」之间往往存在巨大的鸿沟(Sim-to-Real Gap)。为了解决这一难题,TextOp 采用了一种巧妙的数据增强策略:
-
挑战: 真实数据集的分布,与生成器在线生成的轨迹之间存在偏差。
-
对策: 直接使用生成器的输出作为训练数据,来训练底层的跟踪策略。
-
效果: 这种「自产自销」的策略,极大地缩小了训练与推理的分布差异,显著提升了机器人在真实环境中的鲁棒性。
真实机器人验证:跳舞、武术样样精通
研究团队在 Unitree G1 人形机器人上进行了大量真实世界测试。实验结果表明,TextOp 能够实现:
连续技能无缝切换
在连续测试中,机器人展现了惊人的多才多艺:
-
舞蹈大师: 从优雅芭蕾平滑过渡到动感街舞。
-
武术高手: 连贯执行复杂的功夫套路。
-
艺术家: 模拟弹吉他、拉小提琴,姿态惟妙惟肖。
-
社交达人: 配合丰富的表达性手势,仿佛拥有了情绪。

图 4:技能展示 - 机器人在真实环境中执行多种技能:舞蹈、武术、演奏和表达性手势
强抗干扰能力
即使在受到外部推搡和拉扯的干扰下,TextOp 驱动的机器人依然能快速调整重心,保持任务的连续性。

图 5:鲁棒性测试 - 机器人在外部干扰下的实时恢复能力
硬核数据:性能指标全面领先
研究团队进行了系统的定量评估,全面验证了 TextOp 的技术优势。实验涵盖了真实机器人验证、系统实时性能、以及运动表示方法的对比分析。
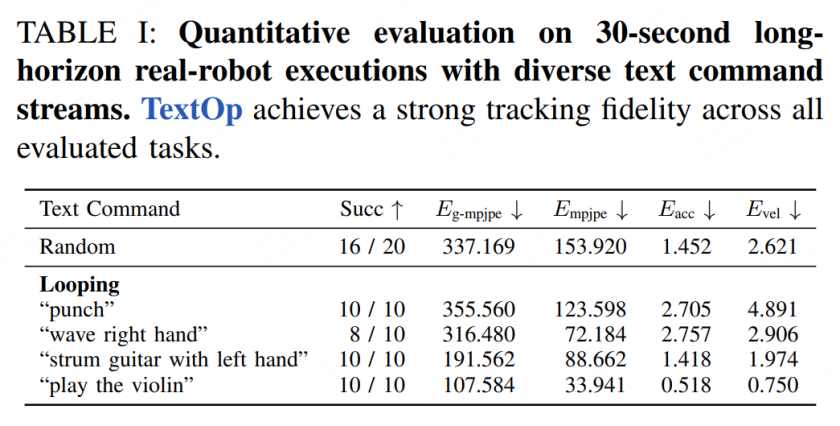
表 1:真实机器人 30 秒长序列定量评估结果
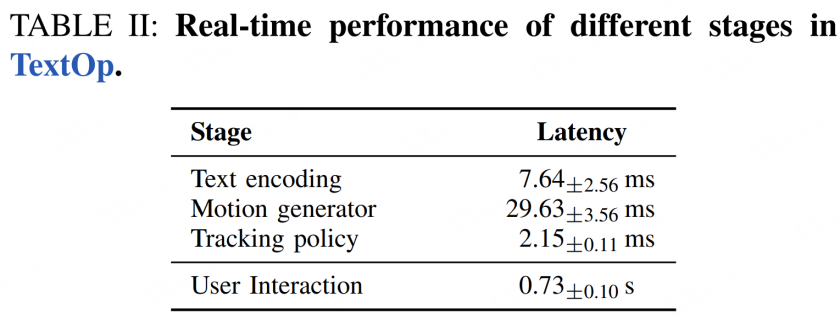
表 2:系统实时性能表现
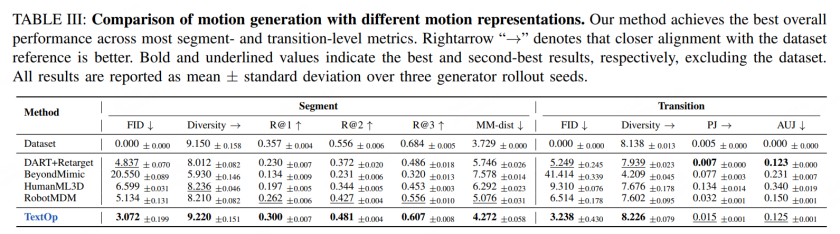
表 3:不同运动表示方法性能对比
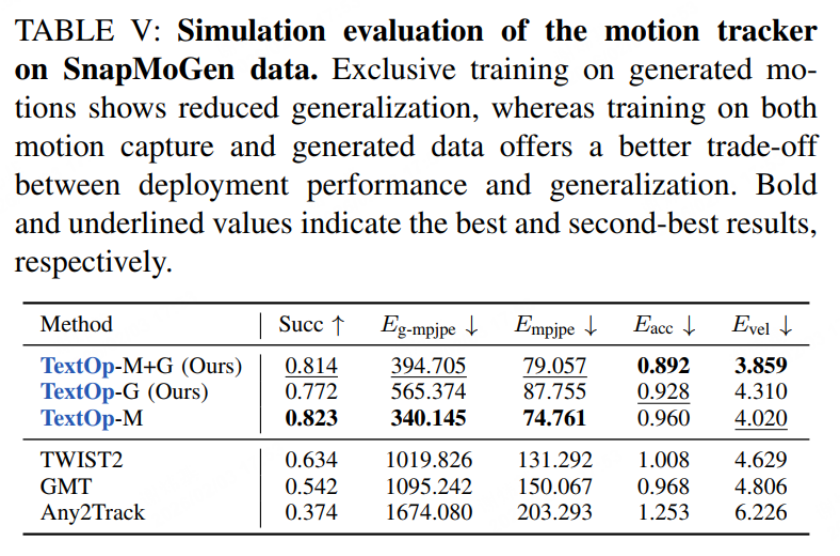
表 4:运动跟踪器在生成数据上的评估
实验结果表明,TextOp 在动作成功率、轨迹质量等关键指标上均达到学界领先水平。特别是用户交互延迟仅 0.73 秒,为实时交互应用奠定了坚实基础。
应用前景:重新定义人机交互
TextOp 的核心价值在于将人形机器人的运动控制从「预编程」升级为「对话式调用」。在多个场景已展现明确潜力:
-
内容创作与表演编排。影视拍摄或舞台演出中,导演可通过文本实时调整机器人动作(如「切换街舞风格」、「加入挥手」),无需等待动捕录制,实现可即兴编排的「数字演员」。
-
标准化动作示范。在体育教学或技能培训中,教练只需发送文本指令即可调取标准动作演示(如「展示深蹲姿势」),机器人即时呈现并能在受干扰后快速恢复,保证教学连续性。
-
遥操作的智能中间层。在危险环境巡查等需人工介入的场景,TextOp 作为高层指令接口,操作员只需说「蹲下检查」,机器人自动规划平衡动作执行,降低逐关节操控的门槛。
结语:迈向通用具身智能的重要一步
虽然 TextOp 在环境感知和物理推理上仍有进化空间,但它成功解决了「从自然语言到物理动作」的映射难题,解决了 AI 领域长期存在的「符号接地(Symbol Grounding)」 问题。
正如论文结语所言:「将这种即时的动作执行能力,与大语言模型的高层推理相结合,我们将为全自主、通用的具身智能机器人铺平道路。」
TextOp 让我们看到,那个机器人能听懂我们、理解我们、并与我们共舞的未来,已然触手可及。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com