RLinf-USER 统一系统助力真实世界机器人训练,效率提升 5.7 倍,支持异构协同与云边端在线微调。
原文标题:RLinf-USER重磅发布!别再用仿真了,真实世界训练也能「极致效率与系统化」
原文作者:机器之心
冷月清谈:
怜星夜思:
2、RLinf-USER 在异构机器人协同方面的突破,对于多机器人协作完成复杂任务有什么启发?
3、RLinf-USER 的全异步流水线设计在提升训练效率方面效果显著。在哪些其他领域也可以借鉴这种设计思路?
原文内容
核心速览:
-
🌟 首个统一系统:将物理机器人提升为与 GPU 同等的计算资源,打破硬件隔阂。
-
⚡️ 极致效率:全异步架构将真实世界训练吞吐量提升 5.7 倍。
-
🤖 异构协同:让不同品牌、不同构型的机器人(如 Franka + ARX)在同一模型下协同进化。
-
🧠 大模型支持:原生支持 VLA(如 PI0)的云边端在线微调。

-
Code: https://github.com/RLinf/RLinf
-
论文链接:https://arxiv.org/abs/2602.07837
01. 背景:当 AI 撞上物理世界的墙
在具身智能的浪潮中,我们已经见证了仿真训练的巨大成功。然而,当我们试图将智能带入真实世界时,却撞上了一堵看不见的墙:
-
时间无法加速:物理世界没有 100 倍速的快进键,数据采集极其昂贵。
-
系统支离破碎:训练在云端,控制在边缘,中间隔着不稳定的网络;机器人被视为难以管理的 “外设”,而非计算资源。
-
数据稍纵即逝:一旦发生故障或网络中断,昂贵的长序列数据往往付诸东流。
真实世界的策略学习(Real-World Policy Learning),不仅是算法的挑战,更是系统的挑战。
今天,我们正式介绍 RLinf-USER —— 一个专为真实世界在线策略学习打造的统一且可扩展的系统。它不只是一个训练框架,更是连接数字大脑与物理躯体的 “神经系统”,是实现千台机器人物理世界策略进化的关键一环。
02. RLinf-USER 是什么?
RLinf-USER (Unified and Extensible SystEm for Real-World Online Policy Learning) 是基于 RLinf 基础设施构建的专用系统。它的核心理念只有一个:将物理世界的复杂性,封装为简洁的计算流。
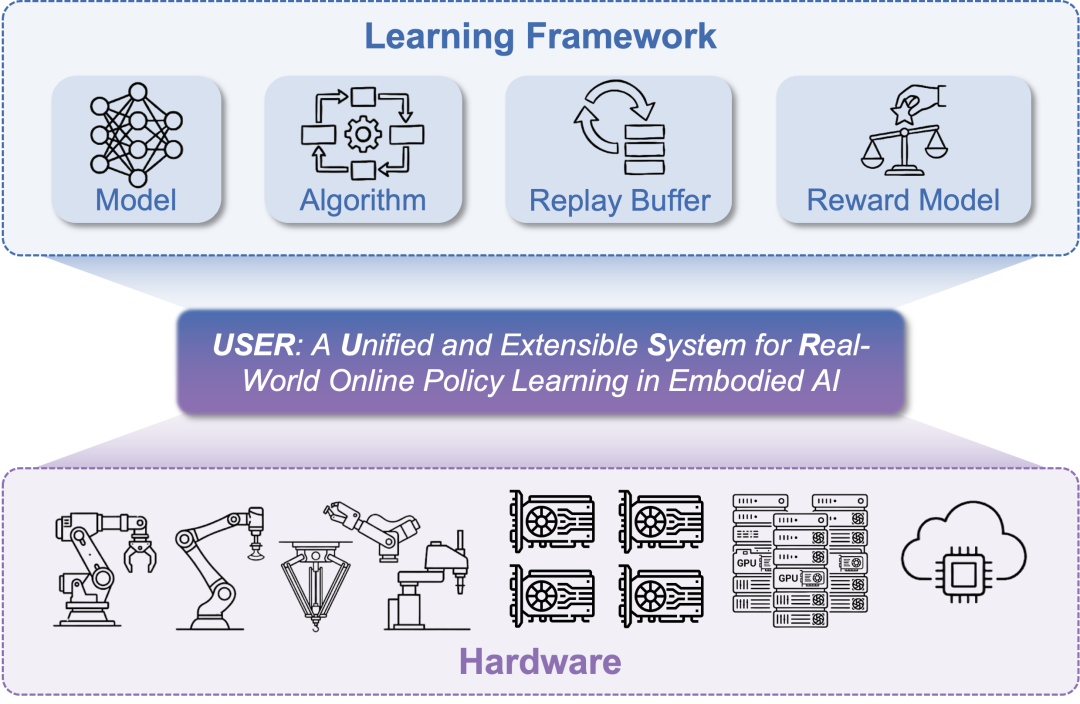
图 1 RLinf-USER 是基于 RLinf 构建的真机强化学习专用系统
系统设计:
🤖 设计 1. 机器人即计算 (Robot as Compute)
RLinf 首次提出 “像使用 GPU 一样使用机器人” 的概念。在 RLinf-USER 中,机器人不再是游离于集群之外的 “设备”。通过统一硬件抽象层 (HAL),物理机器人被虚拟化为与 GPU/TPU 同等的可调度资源。
-
自动发现:像插上显卡一样,系统自动识别接入的机器人。
-
统一调度:无论是 7 自由度的机械臂,还是 4090 显卡,都在同一个资源池中被统一编排。
🌐 设计 2. 云边端无缝协同 (Adaptive Cloud-Edge Link)
大模型在云端,机器人在边缘。RLinf-USER 构建了一个自适应通信平面:
-
隧道穿透:无论机器人身处防火墙后还是复杂内网中,隧道技术都能建立直达云端的专线。
-
流量本地化:智能的分布式数据通道,只传输必要的训练样本,将海量原始观测数据截流在边缘,无惧带宽瓶颈。
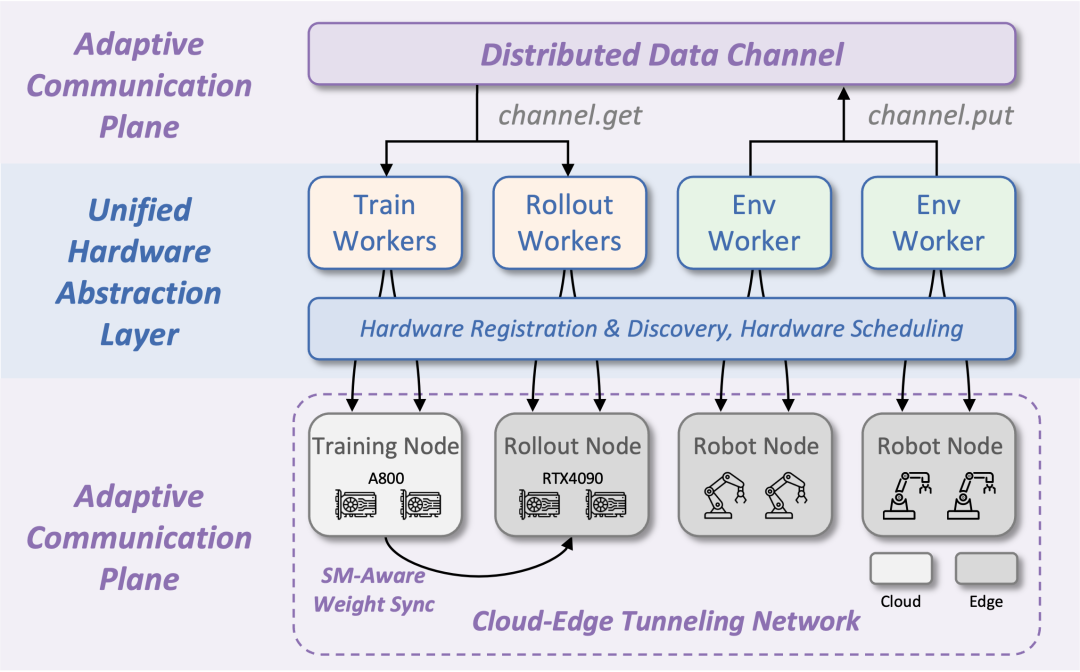
图 2 RLinf-USER 系统设计总览:统一硬件抽象层与自适应通信平面
学习框架设计:
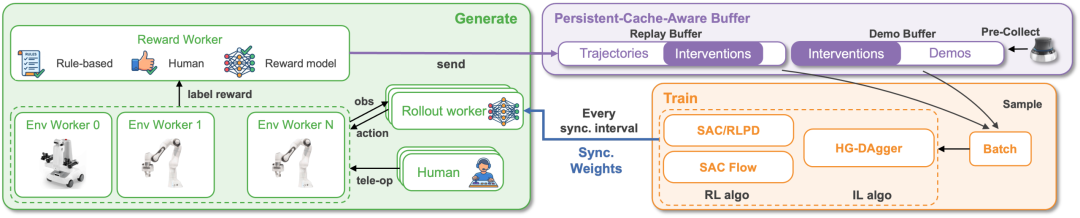
图 3 RLinf-USER 学习框架设计总览
⚡️ 设计 3. 全异步进化引擎 (Fully Asynchronous Pipeline)
真实世界不能等待。传统的 “采集 - 训练” 同步循环会让机器人把大量时间浪费在等待计算上。
RLinf-USER 采用了全异步流水线设计:
-
永不停歇:机器人在持续工作,GPU 在持续计算,网络在持续更新。三个进程完全解耦,互不等待。
-
极致吞吐:在 VLA 模型训练中,这种设计将整体吞吐量提升了 5.70 倍!这意味着在同样的物理时间内,你的机器人能多学 5 倍的经验。
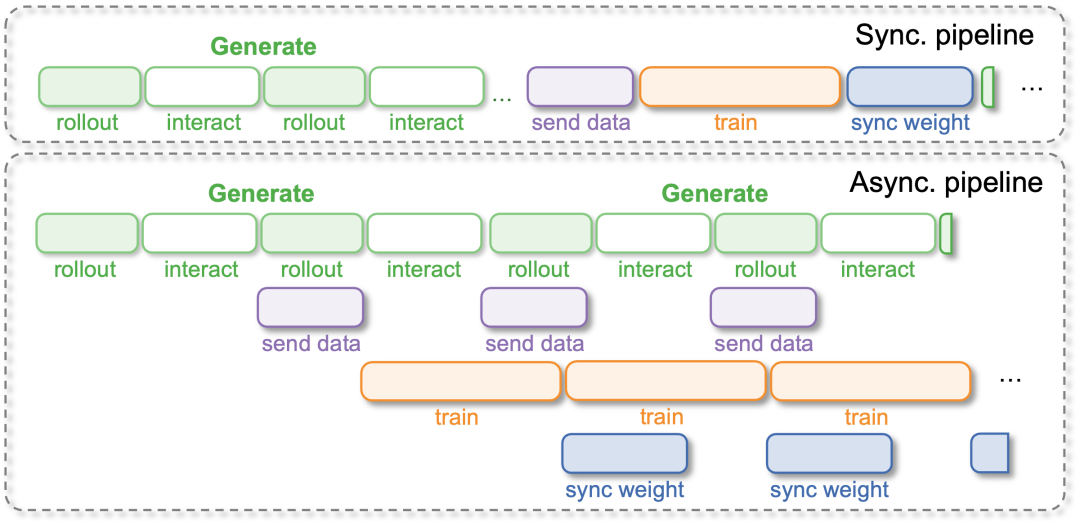
图 4 全异步流水线
💾 设计 4. 数据的 “时光机” (Persistent-Cache-Aware Buffer)
我们设计了持久化缓存感知缓冲区:
-
无限记忆:打破内存限制,支持 TB 级甚至 PB 级的历史轨迹存储。
-
崩溃恢复:即使实验意外中断,数据和状态也能毫发无损,支持长达数周的连续训练。
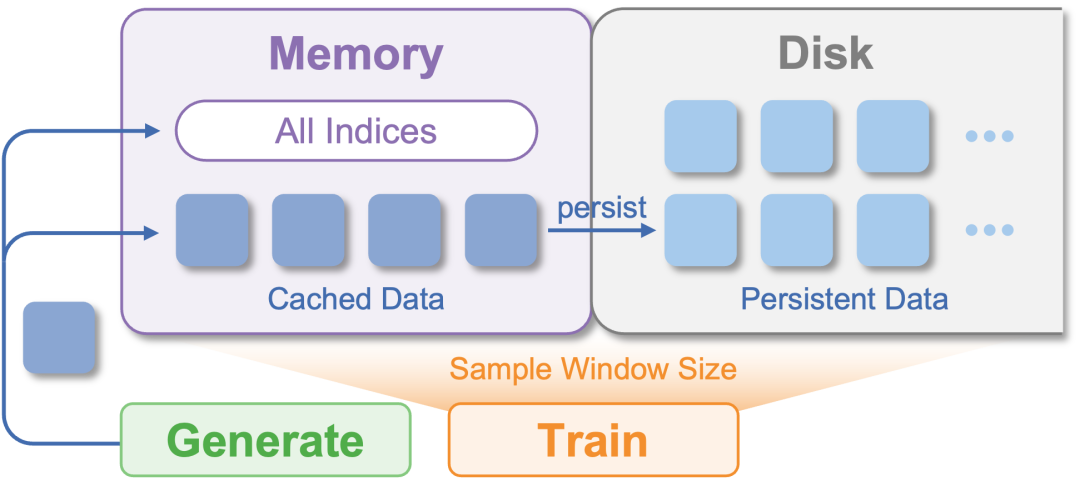
图 5 持久化缓存感知 buffer
🧠 设计 5. 丰富的在线学习组件支持
USER 在统一的接口下,支持了多样的学习组件,模块化的设计易于二次开发:
-
模型支持:CNN model,Flow matching model,VLA(如 PI0)
-
算法支持:强化学习(如 SAC、SAC Flow)、模仿学习(如 HG-DAgger)
-
奖励函数支持:规则奖励、人工奖励、奖励模型
03. 硬核实战:它能做到什么?
RLinf-USER 在 5 个真实任务中证明了效率和性能。
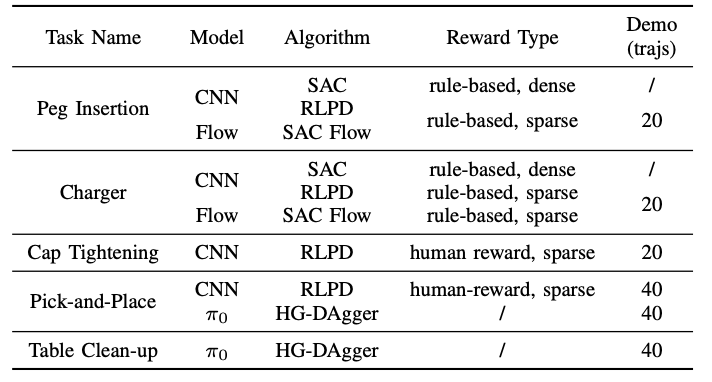
图 6 在 5 个真实世界任务上验证 USER,对应不同的 reward、算法、策略
🏆 战绩一:VLA 大模型的在线进化
这是目前少有的支持 3B 参数 VLA 模型(PI0)在真实世界进行在线微调的系统。
-
任务:桌面清理(Table Clean-up)—— 一个包含分类、抓取、放置、关盖的长序列任务。
-
结果:通过 HG-DAgger 算法,模型成功率从 45% 飙升至 80%。随着训练进行,人工干预次数显著下降,机器人逐渐学会了独立思考。

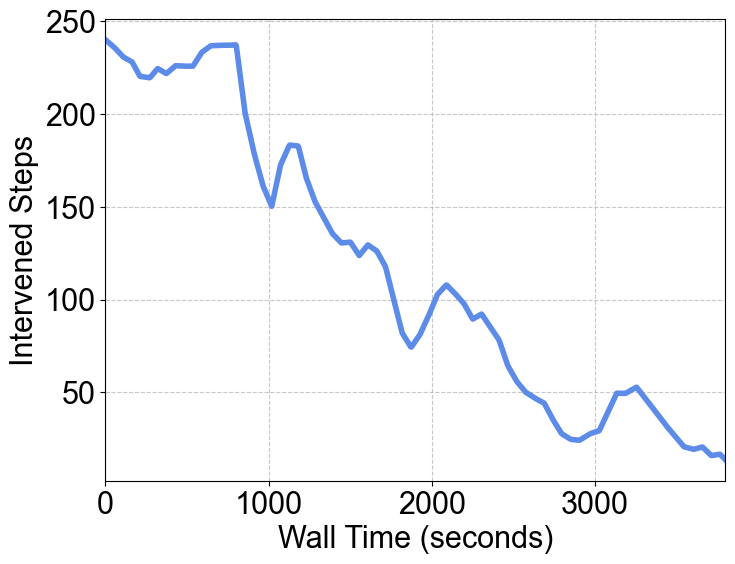
图 7 USER 框架使用 HG-DAgger 算法微调 PI0 模型。人工干预次数显著下降,成功率从 45%->80%
🤝 战绩二:异构机器人 “大一统”
RLinf-USER 完成了一项极具挑战的实验:让两种完全不同的机器人一起学习。
-
组合:高端的 7-DoF Franka 机械臂 + 低成本的 6-DoF ARX 机械臂。
-
效果:尽管它们的构型、关节数、摄像头参数截然不同,但在 USER 的统一抽象下,它们共同为一个策略贡献数据。最终,同一个模型学会了控制这两种截然不同的 “身体”。

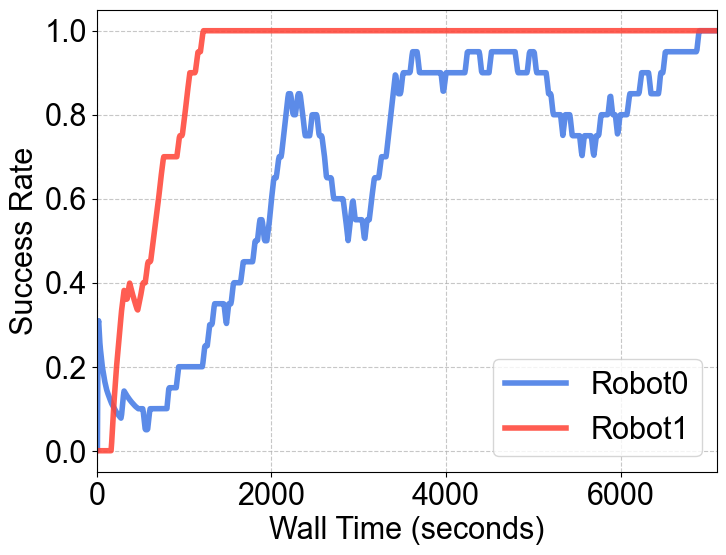
图 8 使用 USER 进行异构训练
☁️ 战绩三:跨越千里的 “云 - 边” 协同
针对大模型训练算力在云端、机器人执行在边缘端的典型场景,RLinf-USER 克服了物理距离和网络隔离的障碍。
-
挑战:训练节点位于北京(云端),而机器人和推理节点位于数千公里外的深圳(边缘端),中间隔着高延迟、带宽受限且复杂的公网环境。
-
效果:得益于 USER 的隧道网络技术(Tunneling-based Networking)和分布式数据通道,跨域通信的效率大幅提升。实验数据显示,在跨域部署下,单集(Episode)数据的生成时间缩短了约 3 倍(从~69 秒 降至~22 秒),实现了如同在局域网般流畅的远程分布式训练。

图 9 USER 自适应通信平面显著降低了跨域部署的通信延迟
⏱️ 战绩四:异步 vs 同步架构速度的碾压
在经典的插孔(Peg Insertion)任务中:
-
传统同步架构:收敛需要 8000+ 秒。
-
RLinf-USER:收敛仅需 约 1500 秒。
效率提升超过 5 倍,让原本漫长的训练过程变得立等可取。
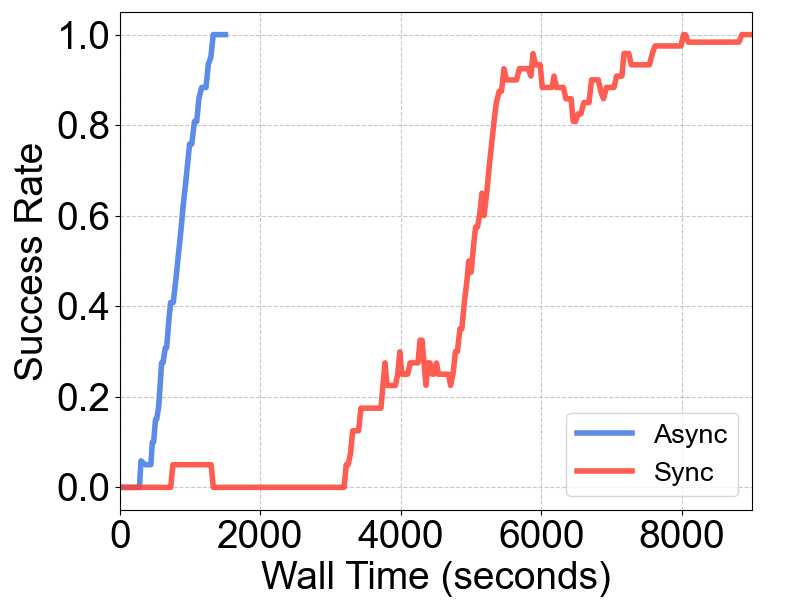
图 10 USER 的全异步工作流显著提升了物理世界中算法的收敛速度
💾 战绩五:打破 “内存墙”,数据的无限记忆与极速吞吐
在真实世界长周期(Long-horizon)的训练中,数据是极其宝贵的资产。针对传统 Buffer “存不下” 或 “读得慢” 的痛点,RLinf-USER 拒绝妥协。
-
机制: RLinf-USER 独创了 持久化缓存感知 Buffer (Persistent-Cache-Aware Buffer),通过智能索引机制,将海量历史数据异步落盘,同时在内存中保留高频热点数据(Cache)。
-
效果: 这是一个 “鱼和熊掌兼得” 的方案。实验评测显示,RLinf-USER 在提供 磁盘级 “无限” 容量(支持 TB 级历史数据回溯)的同时,实现了 显著优于纯磁盘存储的采样吞吐量。同样关键的是,它自带崩溃恢复能力,即使实验因故障意外中断,长期积累的宝贵数据也能毫发无损,随时重启 “再战”。
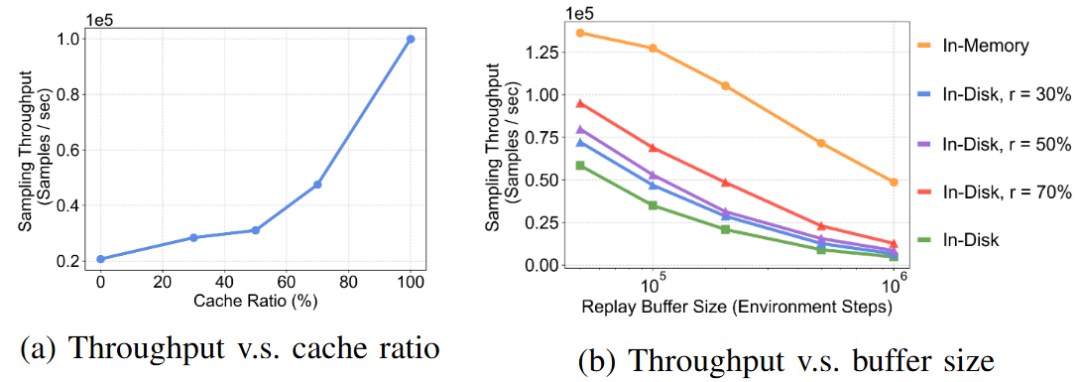
图 11 RLinf-USER 的 Buffer 在不同配置下的吞吐量性能测试,平衡了容量与效率
04. 为什么选择 RLinf-USER?
如果说 ChatGPT 是 AI 在数字世界的里程碑,那么 RLinf-USER 致力于成为具身智能在物理世界的基石。
✅ 如果你是研究者:它兼容 CNN、Flow-based policy、VLA 等多种策略,支持 RL、IL、Human-in-the-loop 等各种算法。它将模型、算法等模块解耦,简化开发难度。
✅ 如果你是工程师:它提供了工业级的稳定性(崩溃恢复)和扩展性(自动硬件发现),让大规模机器人集群管理变得像管理服务器一样简单。
此时此刻,机器人不再只是外设。RLinf-USER,让智能真正 “具身”。
写在最后
RLinf 发布半年,Github Star 2.5k+,得到了学术界和工业界的广泛认可,达成了多项战略合作,包括英伟达 IssacLab、原力灵机 Dexbotic 等,更多家合作官宣也会尽快和大家见面。道阻且长,26 年 RLinf 仍在为搭建更好的具身智能基础设施而努力,并持续做好可复现生态。团队也开放招生和招聘,欢迎大家联系于超老师(邮件:zoeyuchao@gmail.com)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com